利用python爬取丁香医生上新型肺炎数据,并下载到本地,附带经纬度信息
新增:国外疫情网站介绍
已更新:爬取国外疫情数据
已更新:新型肺炎历史数据下载
2020年3月27日补充:
制作了一个全球肺炎数据查询下载网站,效果如下:
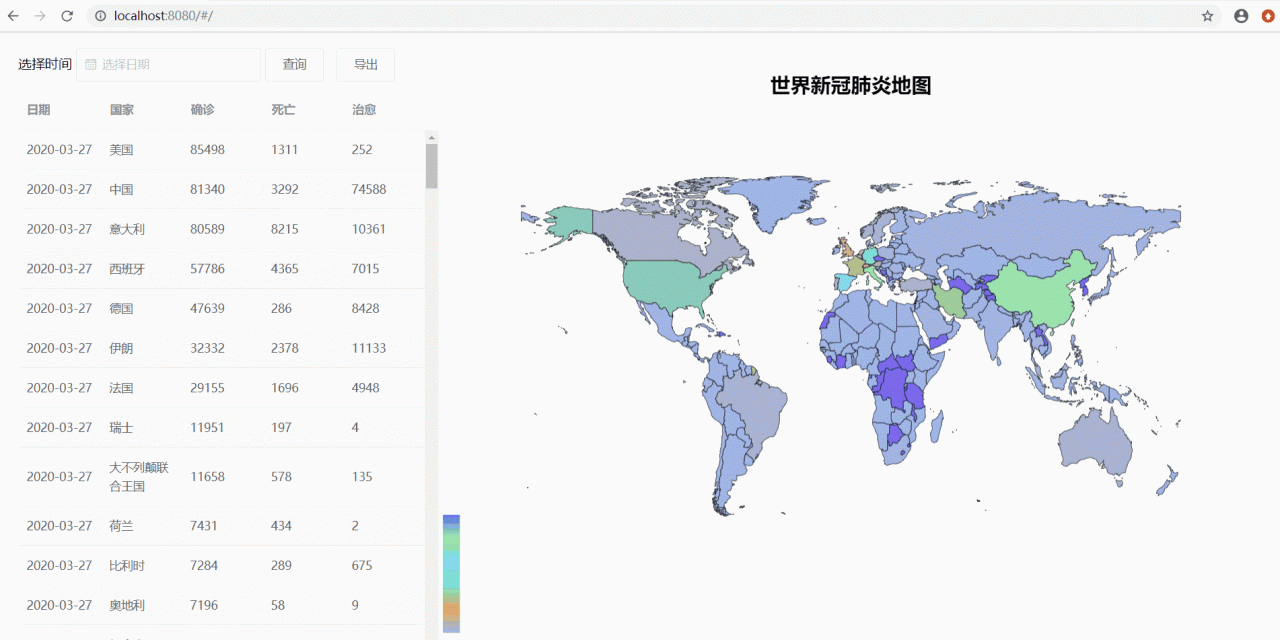
3月28日更新:
鉴于有些人说丁香医生的接口数据访问不了了,因此改为百度疫情数据,重新打包了一个工具,百度云盘地址:
链接:https://pan.baidu.com/s/1-nqi6uhCJYAi8kVDqGiYCw
提取码:6hos
新型肺炎肆虐全国,可以预知,最近一两年地理学中会有一部分论文研究新型肺炎的空间分布及与其他指标的关联分析。获取其患病人员分布数据,对于科学研究具有一定的指导意义,因此利用python爬取丁香医生上实时的数据,并将其打包成exe文件,可以本地直接执行,不需配置环境,当然爬取的数据没有经纬度信息,这里我利用百度地图开发者平台,通过市名获取经纬度坐标。
软件下载地址:
不带经纬度(可用)
链接:https://pan.baidu.com/s/1ffcGv7CsaKPPDohFd03pww
提取码:ibql
带经纬度(受百度地图api调用次数限制)
链接:https://pan.baidu.com/s/1zgPIre_39eG9iQfxTxq1Fg
提取码:1tmi
执行效果如下:
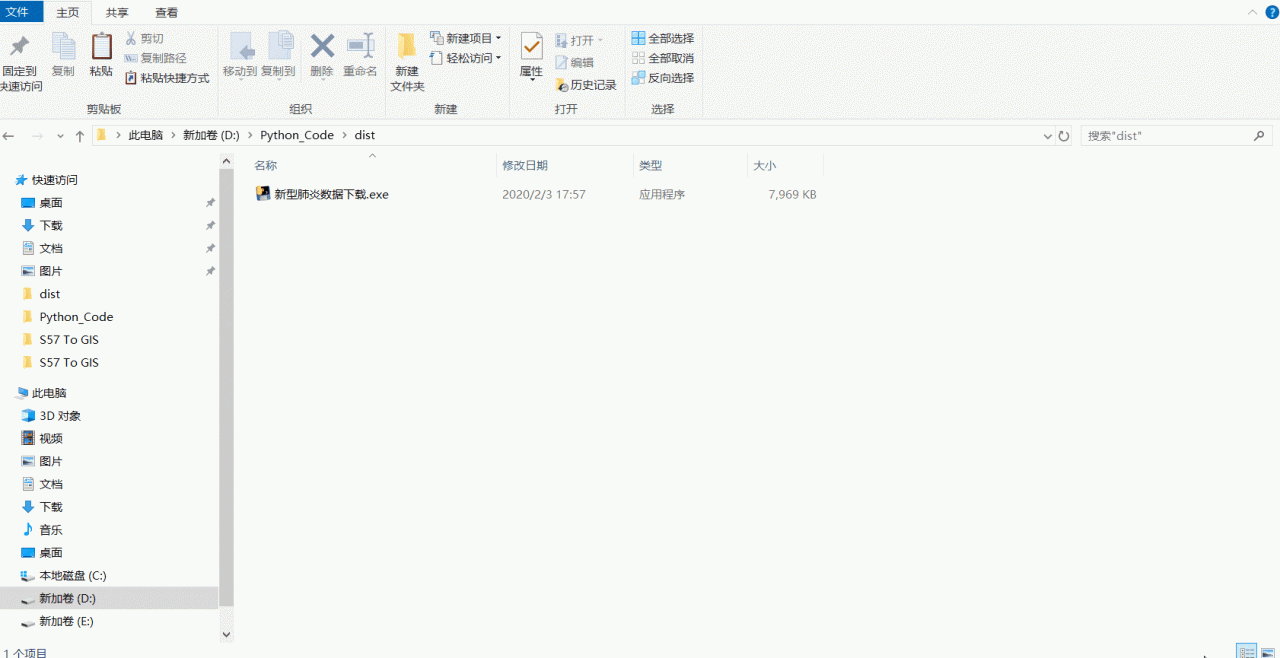
对比丁香医生上数据:
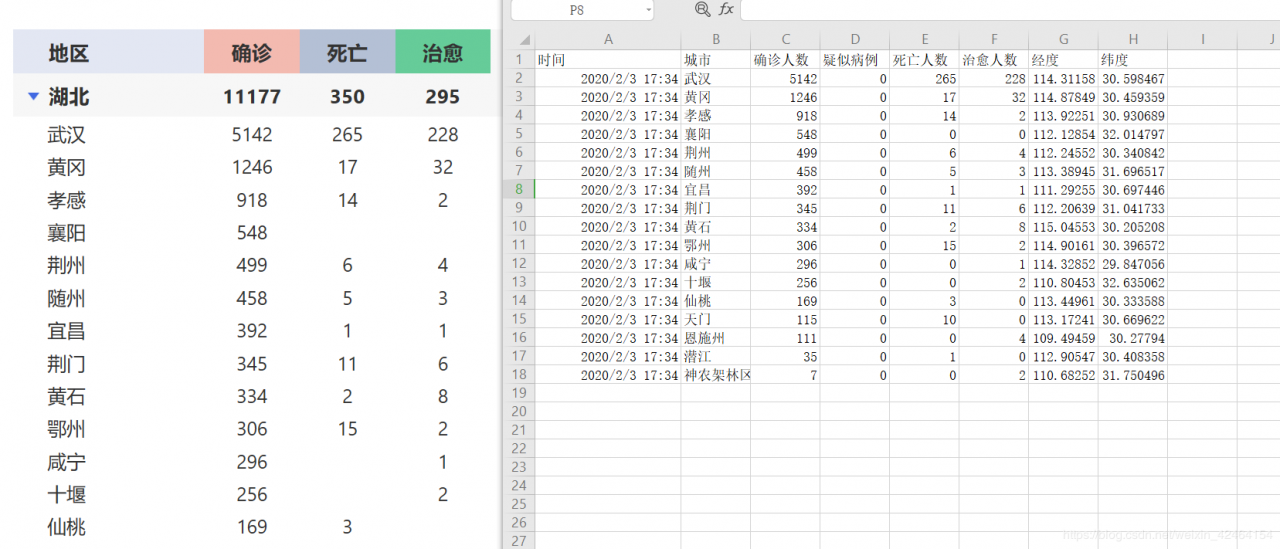
完整代码如下:
不带经纬度代码:
import requests,re
import json
import time
import csv
url = 'https://service-f9fjwngp-1252021671.bj.apigw.tencentcs.com/release/pneumonia'
html = requests.get(url).text
unicodestr=json.loads(html) #将string转化为dict
dat = unicodestr["data"].get("statistics")["modifyTime"] #获取data中的内容,取出的内容为str
timeArray = time.localtime(dat/1000)
formatTime = time.strftime("%Y-%m-%d %H:%M", timeArray)
new_list = unicodestr.get("data").get("listByArea") #获取data中的内容,取出的内容为str
j = 0
print("###############"
"版权所有:殷宗敏 &"
"& 数据来源:丁香医生 "
"###############")
while j < len(new_list):
a = new_list[j]["cities"]
s = new_list[j]["provinceName"]
header = ['时间', '城市', '确诊人数', '疑似病例', '死亡人数', '治愈人数' ]
with open('./'+s+'.csv', encoding='utf-8-sig', mode='w',newline='') as f:
#编码utf-8后加-sig可解决csv中文写入乱码问题
f_csv = csv.writer(f)
f_csv.writerow(header)
f.close()
def save_data(data):
with open('./'+s+'.csv', encoding='UTF-8', mode='a+',newline='') as f:
f_csv = csv.writer(f)
f_csv.writerow(data)
f.close()
b = len(a)
i = 0
while i<b:
data = (formatTime)
confirm = (a[i]['confirmed'])
city = (a[i]['cityName'])
suspect = (a[i]['suspected'])
dead = (a[i]['dead'])
heal = (a[i]['cured'])
i+=1
tap = (data, city, confirm, suspect, dead, heal)
save_data(tap)
j += 1
print(s+"下载结束!")
具有经纬度功能代码:
import requests,re
import json
import time
import csv
from urllib.request import urlopen, quote
url = 'https://service-f9fjwngp-1252021671.bj.apigw.tencentcs.com/release/pneumonia'
html = requests.get(url).text
unicodestr=json.loads(html) #将string转化为dict
dat = unicodestr["data"].get("statistics")["modifyTime"] #获取data中的内容,取出的内容为str
timeArray = time.localtime(dat/1000)
formatTime = time.strftime("%Y-%m-%d %H:%M", timeArray)
url = 'http://api.map.baidu.com/geocoder/v2/'
output = 'json'
ak = 'XeCfCY777qDMTKSqyc3LTiGPnMA7fqzy'#你的ak
new_list = unicodestr.get("data").get("listByArea") #获取data中的内容,取出的内容为str
j = 0
print("###############"
" 版权所有:殷宗敏 &"
"& 数据来源:丁香医生 "
"###############")
while j < len(new_list):
a = new_list[j]["cities"]
s = new_list[j]["provinceName"]
header = ['时间', '城市', '确诊人数', '疑似病例', '死亡人数', '治愈人数' ,'经度','纬度']
with open('./'+s+'.csv', encoding='utf-8-sig', mode='w',newline='') as f:
#编码utf-8后加-sig可解决csv中文写入乱码问题
f_csv = csv.writer(f)
f_csv.writerow(header)
f.close()
def save_data(data):
with open('./'+s+'.csv', encoding='UTF-8', mode='a+',newline='') as f:
f_csv = csv.writer(f)
f_csv.writerow(data)
f.close()
b = len(a)
i = 0
while i<b:
data = (formatTime)
confirm = (a[i]['confirmed'])
city = (a[i]['cityName'])
suspect = (a[i]['suspected'])
dead = (a[i]['dead'])
heal = (a[i]['cured'])
add = quote(a[i]['cityName'])
uri = url + '?' + 'address=' + add + '&output=' + output + '&ak=' + ak # 百度地理编码API
req = urlopen(uri)
res = req.read().decode()
temp = json.loads(res)
if temp['status'] == 1:
temp["result"] = {'location': {'lng': 0, 'lat': 0}}
lon = temp['result']['location']['lng']
lat = temp['result']['location']['lat']
i+=1
tap = (data, city, confirm, suspect, dead, heal, lon, lat)
save_data(tap)
j += 1
print(s+"下载结束!")
print("##########数据下载结束#########")
作者:新月清光