记一次用Python统计全国女性Size
前言
最近闲来无事,又正好在学习Python数据分析统计,于是便萌生一种想法:统计京东购买记录,分析全国女性平均Size
准备工作
首先查询京东网站,输入查询内容xz,查到87万+商品
购买size可以在评论区找到(就摆在那儿,那也太简单了,后面才知道我想多了。。。)
 先看域名,发现每一个域名的构成都是https://item.jd.com/然后加一串数字.html,经验告诉我,这串数字一定是商品id。
找id的话就要到搜索页面找了,果然,在分析搜索页面之后,发现id就躺在静态页面中。
先看域名,发现每一个域名的构成都是https://item.jd.com/然后加一串数字.html,经验告诉我,这串数字一定是商品id。
找id的话就要到搜索页面找了,果然,在分析搜索页面之后,发现id就躺在静态页面中。 思路有了,准备写代码。。。
开始码代码
第一步当然是获取id了,通过分析搜索域名(不得不说jd的反爬机制,唉,这里不好评价,自行体会,分析过程如下。)
思路有了,准备写代码。。。
开始码代码
第一步当然是获取id了,通过分析搜索域名(不得不说jd的反爬机制,唉,这里不好评价,自行体会,分析过程如下。) 需要注意的就是keyword,wq(全拼),还有后面的page和s,这几个参数是改变的
需要注意的就是keyword,wq(全拼),还有后面的page和s,这几个参数是改变的
 下面分析接口url(也不难)。
下面分析接口url(也不难)。
 - 分析并不难,直接上代码,这次没有用params的参数,而是用的字符串拼接,因为params一直报错,搞了好久。
- 分析并不难,直接上代码,这次没有用params的参数,而是用的字符串拼接,因为params一直报错,搞了好久。
 然后对获取到的数据进行分类汇总
然后对获取到的数据进行分类汇总
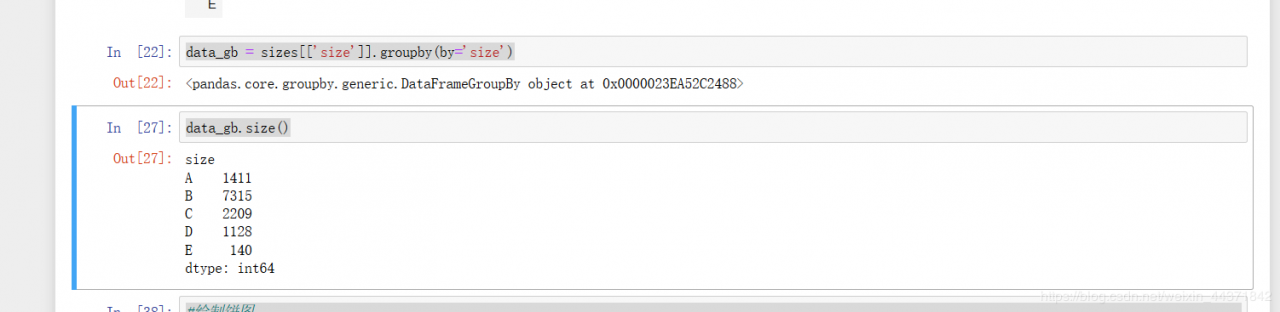 汇总之后就明显可以看出来,B占大多数了,然后开始绘制一下饼图。
汇总之后就明显可以看出来,B占大多数了,然后开始绘制一下饼图。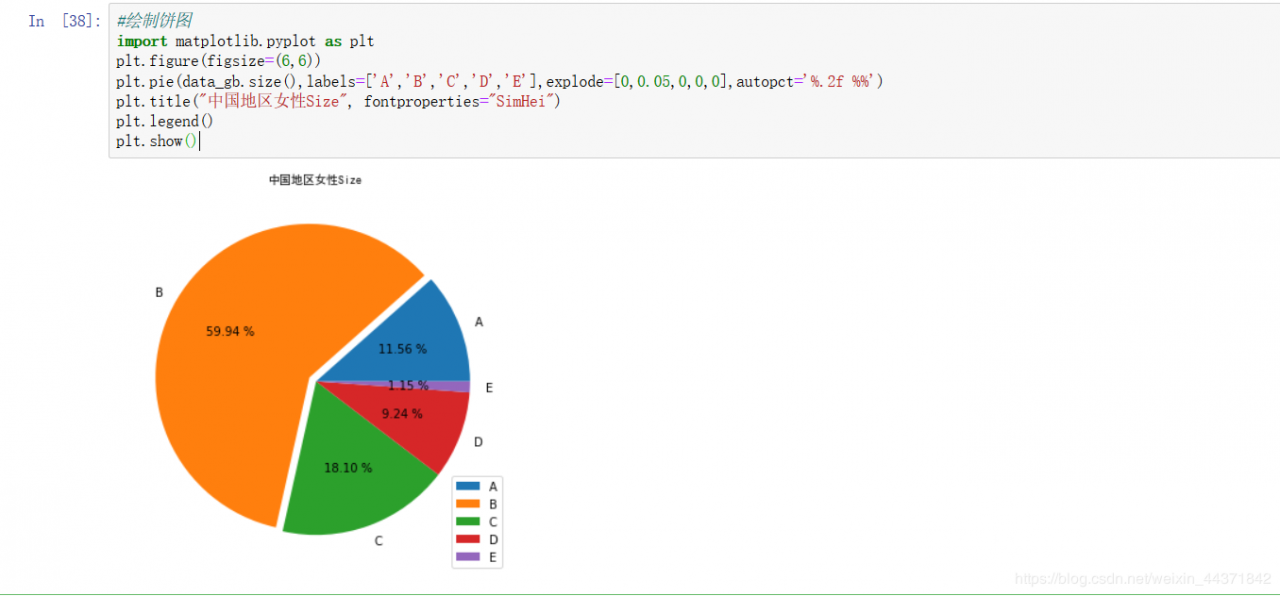 果然,B占一半以上,接下来再绘制一下直方图。
果然,B占一半以上,接下来再绘制一下直方图。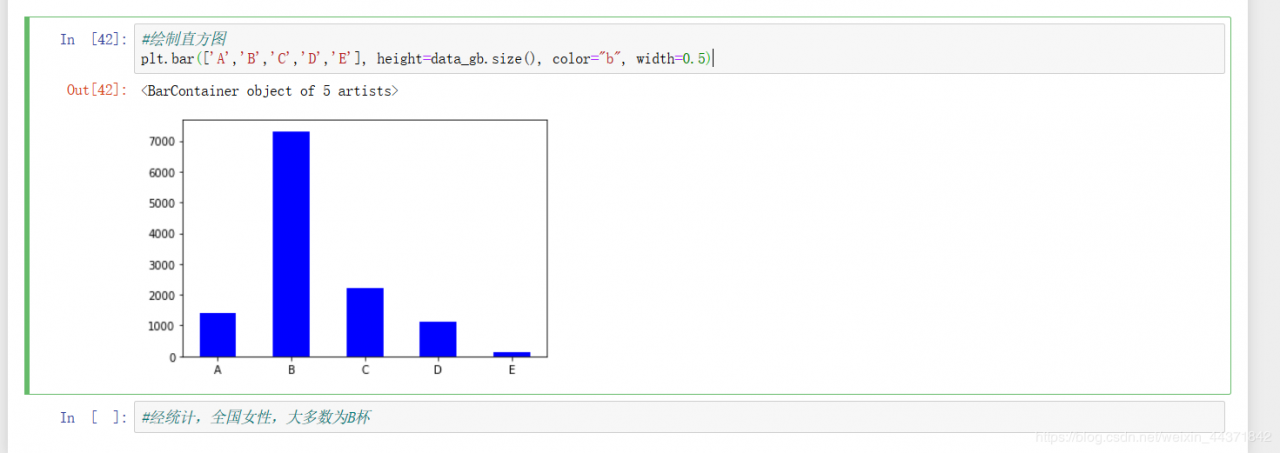 至此,我们的分析项目就完成了,经统计,全国女性大多为B杯。
至此,我们的分析项目就完成了,经统计,全国女性大多为B杯。
作者:Lang.
先看域名,发现每一个域名的构成都是https://item.jd.com/然后加一串数字.html,经验告诉我,这串数字一定是商品id。
找id的话就要到搜索页面找了,果然,在分析搜索页面之后,发现id就躺在静态页面中。
思路有了,准备写代码。。。
开始码代码
第一步当然是获取id了,通过分析搜索域名(不得不说jd的反爬机制,唉,这里不好评价,自行体会,分析过程如下。)
需要注意的就是keyword,wq(全拼),还有后面的page和s,这几个参数是改变的
keyword传入商品名称,wq传入商品全拼,page传入商品页(jd是按照奇数排序),s的话,需要计算,见代码。
#爬取商品id
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:75.0) Gecko/20100101 Firefox/75.0'}
def get_id(key_word,wq):
#jd_url='https://search.jd.com/Search?keyword=%E5%A5%B3%E6%80%A7%E5%86%85%E8%A1%A3&enc=utf-8&wq=%E5%A5%B3%E6%80%A7nei%27yi&pvid=fafd7af082734ae1a4a6cb674f98b2e4'
jd_url = 'https://search.jd.com/Search'
product_ids = []
# 爬前3页的商品
j = 51;
for i in range(17,25,2):
param = {'keyword': key_word, 'enc': 'utf-8', 'qrst':'1', 'rt':1, 'stop':1, 'vt':2, 'wq':wq, 'page':i, 's':j, 'click':0}
response = requests.get(jd_url,params = param,headers=headers)
# 商品id
ids = re.findall('data-pid="(.*?)"', response.text,re.S)
product_ids += ids
if i!= 3:
j = j+50+i-4;
else:
j+=50
return product_ids
获取id之后我们进入页面,准备获取评价里的购买尺寸,用静态网站方法爬一下,正则表达式分析一手,发现根本无法获得购买尺寸,再一看,获取的html页面中根本没有评价内容,经验告诉我这是通过json接口传入的。
于是,就开始了我的找接口。。。。(此处省略两个小时)
在我的不懈努力下,终于找到了接口。。。
下面分析接口url(也不难)。- 分析并不难,直接上代码,这次没有用params的参数,而是用的字符串拼接,因为params一直报错,搞了好久。
#爬取Size
def getSizes(ids):
Sizes = []
for id in ids:
for i in range(0,8):
url = 'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId='+id+'&score=0&sortType=5&page='+str(i)+'&pageSize=10&isShadowSku=0&fold=1'
response = requests.get(url)
size = re.findall('"productSize":"(.*?)"',response.text)
Sizes+=size
return Sizes
爬取Size后,发现Size并不统一,有的用XXL,有的用ABC,所以需要清洗一下获取的数据,如下
#数据清洗(统一尺码)
def unified(str):
if 'E' in str:
return 'E'
if 'D' in str:
return 'D'
if 'C' in str:
return 'C'
if 'B' in str:
return 'B'
if 'A' in str:
return 'A'
if 'XXL' in str:
return 'E'
if 'XL' in str:
return 'D'
if 'L' in str:
return 'C'
if 'M' in str:
return 'B'
if 'S' in str:
return 'A'
if '均码' in str:
return 'B'
if '大' in str:
return 'C'
if '小' in str:
return 'A'
搞定这一切后,想要对Size进行分析,但是我感觉直接在PyCharm里面分析有点难看,好吧,主要是想用上最近学的juty notebook。于是我便把获取到的数据先写入MySQL,再转到juty notebook进行分析。
#运行并写入数据库
conn = pymysql.connect(host='localhost',user='root',password='123',database='size',port=3306) #连接数据库
cursor = conn.cursor()
ids = get_id("胸罩","xiong'zhao") #获取id
Sizes = getSizes(ids) #获取sizes
Sizes_flush = []
for size in Sizes: #清洗Sizes
if unified(size) is not None:
Sizes_flush+=unified(size)
sql = "INSERT INTO jd_size(size) values('" + unified(size) + "');"
cursor.execute(sql) #入库
conn.commit()
开始分析
首先连接数据库并读入数据
然后对获取到的数据进行分类汇总
汇总之后就明显可以看出来,B占大多数了,然后开始绘制一下饼图。
果然,B占一半以上,接下来再绘制一下直方图。
至此,我们的分析项目就完成了,经统计,全国女性大多为B杯。
完整项目代码见https://github.com/lrffun/My_Python/tree/master/Size
作者:Lang.