Python数据可视化学习笔记:第一章 关联图 第四节 使用Python绘制一般气泡图
前言
作者:一个跻身科研大浪的小白
声明:这个系列的博文都是我自己学习所得的东西,秉承着每天进步一点点的理念进行学习,我参考的课程是《菊安酱与菜菜的Python机器学习可视化50图》,使用的Python版本为3.6.4。
今天学习的内容气泡图的绘制,这种图与散点图有很多相似之处,所以可以借鉴散点图的代码进行制作。
1.我们在复杂散点图绘制的基础上对代码进行修改,使之变为气泡图,原始代码如下:
import numpy as np #数学处理库
import pandas as pd #用于处理.csv excel html 文本等文件
import matplotlib as mpl #画图像的库
import matplotlib.pyplot as plt #画二维图像的库
import seaborn as sns #颜色库
watch_data1=datasets.head()
#print(watch_data1)
watch_data2=datasets.columns
#print(watch_data2)
#准备标签
watch_cat=datasets['category']
#print(watch_cat)#查看原始标签
categories=np.unique(datasets['category'])#去掉重复项
#print(categories)#查看去重后类别
#print(len(categories))#查看有几个类别
#准备颜色
'''colorx=plt.cm.tab10(5.2)#从tab10色带中取出一个颜色
x1=np.random.randn(10)
x2=x1+x1**2-10
plt.scatter(x1,x2,s=50,c=np.array(colorx).reshape(1,-1))
plt.show()'''
#开始绘制复杂散点图
#我们需要循环和类别数目一样的次数,目前有14各类别
#我们用循环的i来生成小数,这样就可以生成不同的颜色
#以下两个步骤可以去掉图例的边框
plt.style.use('seaborn-whitegrid')#设定整体风格
sns.set_style("white")#设置背景
plt.figure(figsize=(16,10),dpi=120,facecolor='w',edgecolor='k')#定义画布,分辨率,背景,边框
for i in range (len(categories)):
plt.scatter(datasets.loc[datasets["category"]==categories[i],"area"],datasets.loc[datasets["category"]==categories[i],"poptotal"],s=20,c=np.array(plt.cm.tab10(i/len(categories))).reshape(1,-1),label=categories[i])
#开始装饰
plt.gca().set(xlim=(0.0,0.12),ylim=(0,80000))#控制横纵坐标的范围
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.ylabel('Population',fontsize=22)
plt.xlabel('Area',fontsize=22)
plt.title("scatterplot of midwest Area vs Population",fontsize=22)
plt.legend(fontsize=12)
plt.show()
2.开始修改,我们要产生气泡图的实质是要让点的大小随着某一个类别的值的大小而变化,那么,就是要对s参数进行改变。我们之前可以让颜色变化同理就可以让点的尺寸变化,修改下面的代码看看效果,主要看s的部分:
plt.scatter(datasets.loc[datasets["category"]==categories[i],"area"],datasets.loc[datasets["category"]==categories[i],"poptotal"],s=datasets.loc[datasets["category"]==categories[i],"popasian"],c=np.array(plt.cm.tab10(i/len(categories))).reshape(1,-1),label=categories[i])
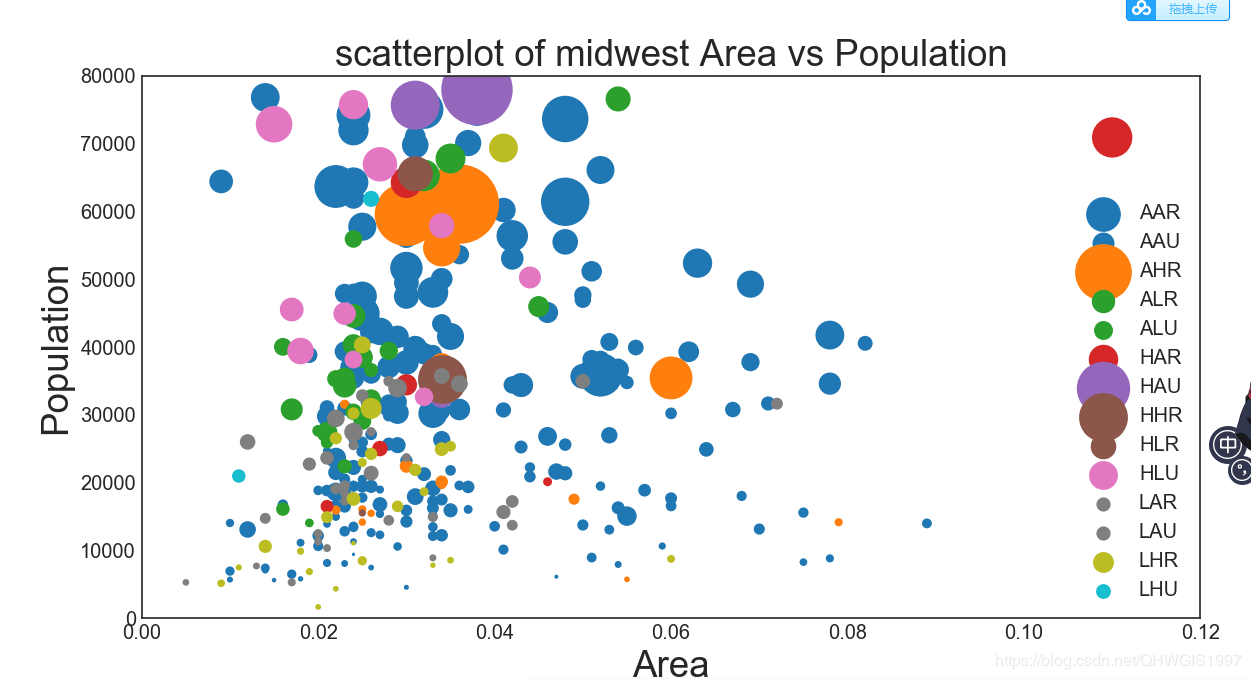
3.这时候基本上出现了我们想要的东西,但是存在很多问题,我们一一来解决:
问题1:点的颜色不透明,符号不好看,不是我们想要的;
加入下面的代码我们再来看看,增加了透明度,边缘颜色,边缘线宽参数之后:
plt.scatter(datasets.loc[datasets["category"]==categories[i],"area"],datasets.loc[datasets["category"]==categories[i],"poptotal"],s=datasets.loc[datasets["category"]==categories[i],"popasian"],c=np.array(plt.cm.tab10(i/len(categories))).reshape(1,-1),label=categories[i],alpha=0.7,edgecolors=np.array(plt.cm.tab10(i/len(categories))).reshape(1,-1),linewidths=0.5)#透明度,边缘颜色,边缘线宽
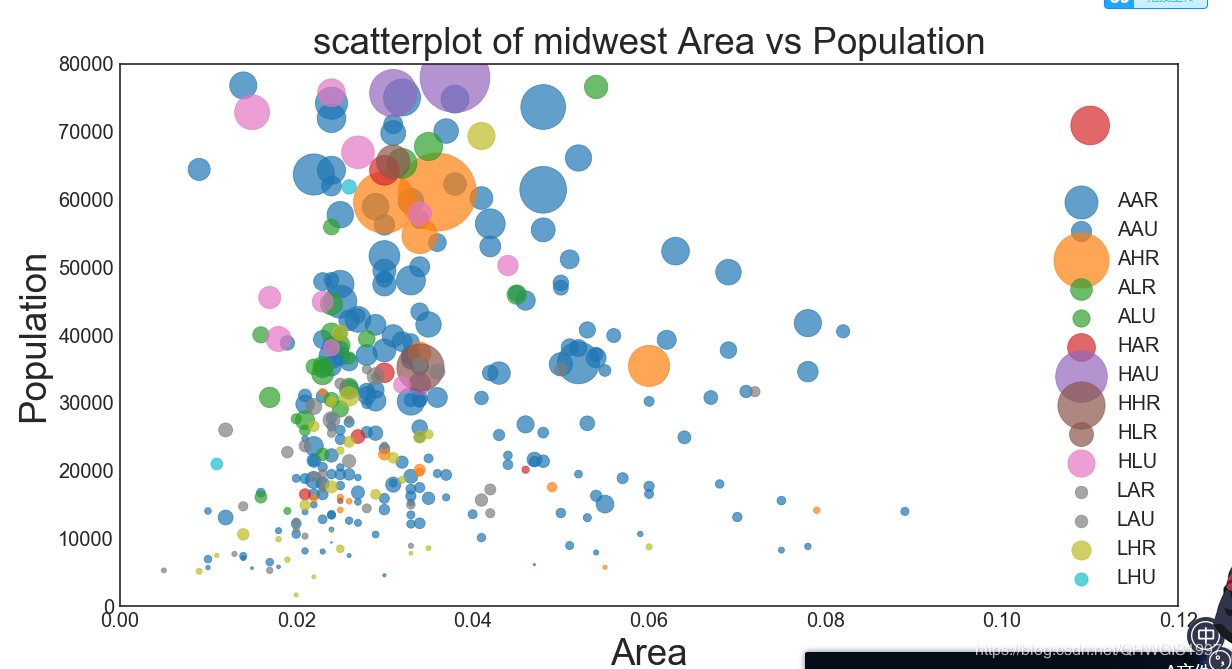
问题2:以人数绝对值为点的大小不合理,最好使用占比表达,但是占比的数值都比较小,怎么能使用它呢?
我们可以整体给占比乘一个比较大的数,扩大以后,显示就没有问题了,代码修改和效果如下:
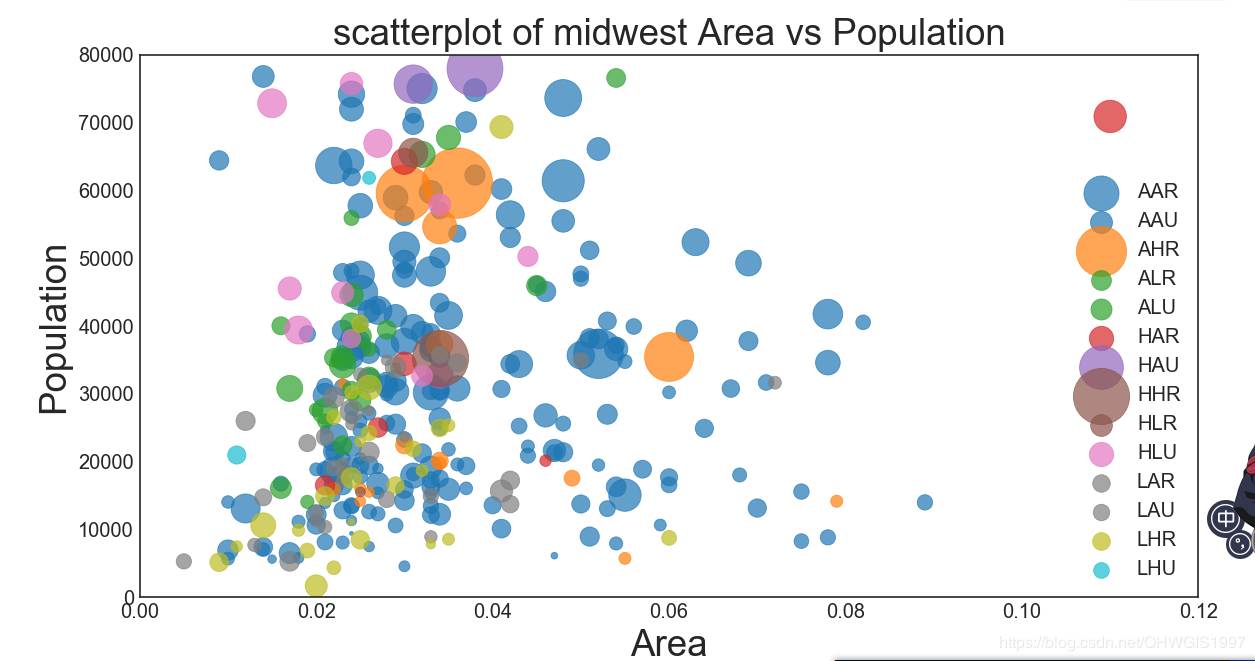
问题3:气泡图整饰的问题,图例很难看,点超出范围了,图名不正确。
#开始装饰
plt.gca().set(xlim=(0.0,0.12),ylim=(0,90000))#控制横纵坐标的范围
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.ylabel('Population',fontsize=22)
plt.xlabel('Area',fontsize=22)
plt.title("Bubble Plot with Encircling",fontsize=22)
plt.legend(fontsize=12,markerscale=0.5)#现有图例的0.5倍
plt.show()
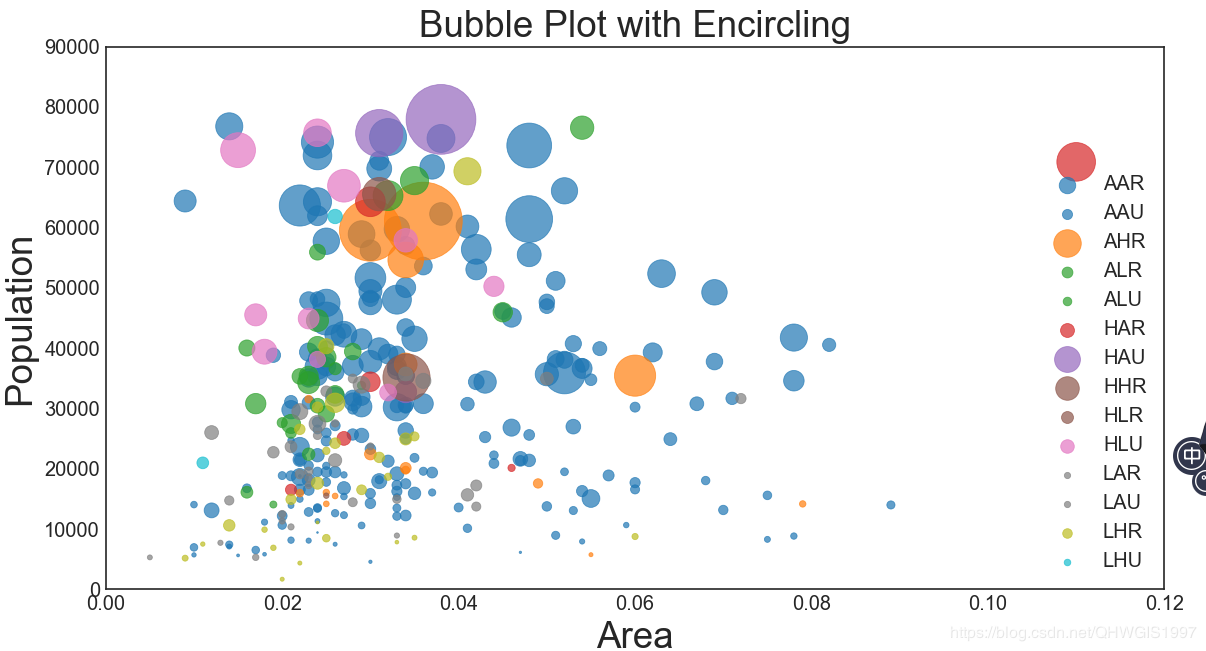
#Author:Albert(CSDN:一个跻身科研大浪的小白)
#Time:2020/03/23
#usage:气泡图
import numpy as np #数学处理库
import pandas as pd #用于处理.csv excel html 文本等文件
import matplotlib as mpl #画图像的库
import matplotlib.pyplot as plt #画二维图像的库
import seaborn as sns #颜色库
datasets=pd.read_csv("http://raw.githubusercontent.com/selva86/datasets/master/midwest_filter.csv")#由原博主提供的在线数据集直接导入
categories=np.unique(datasets['category'])#去掉重复项
#以下两个步骤可以去掉图例的边框
plt.style.use('seaborn-whitegrid')#设定整体风格
sns.set_style("white")#设置背景
plt.figure(figsize=(16,10),dpi=120,facecolor='w',edgecolor='k')#定义画布,分辨率,背景,边框
for i in range (len(categories)):
plt.scatter(datasets.loc[datasets["category"]==categories[i],"area"],datasets.loc[datasets["category"]==categories[i],"poptotal"],s=datasets.loc[datasets["category"]==categories[i],"popasian"],c=np.array(plt.cm.tab10(i/len(categories))).reshape(1,-1),label=categories[i],alpha=0.7,edgecolors=np.array(plt.cm.tab10(i/len(categories))).reshape(1,-1),linewidths=0.5)#透明度,边缘颜色,边缘线宽
#开始装饰
plt.gca().set(xlim=(0.0,0.12),ylim=(0,90000))#控制横纵坐标的范围
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.ylabel('Population',fontsize=22)
plt.xlabel('Area',fontsize=22)
plt.title("Bubble Plot with Encircling",fontsize=22)
plt.legend(fontsize=12,markerscale=0.5)#现有图例的0.5倍
plt.show()
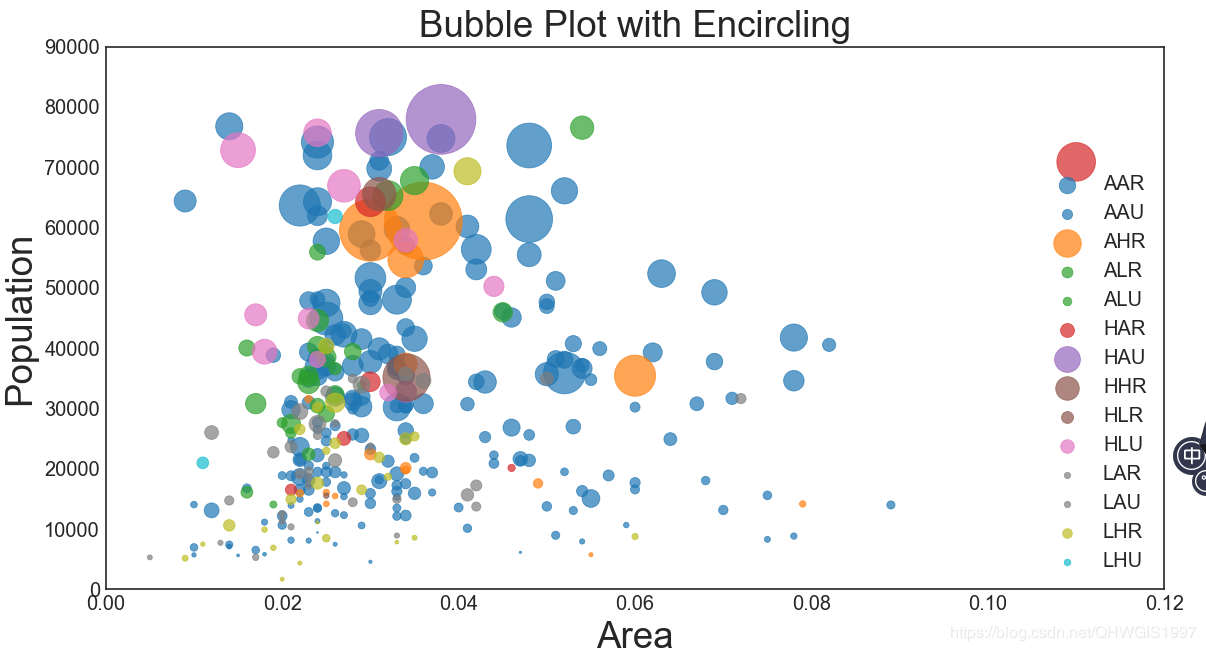
实质上感觉依然不是很明朗,下期在图像上加文字,然后再处理图例使之更加美观。
作者:一个跻身科研大浪的小白