Python:金融应用实例--隐含波动率预测项目 :读取hdf文件过程问题
网络上下载了vstoxx_data_31032014.h5 文件,因为代码报一些错误,把文件后缀改为了vstoxx_data_31032014.hdf5,
h5=pd.HDFStore('D:/机器学习算法/Python与金融应用/Python/sources/vstoxx_data_31032014.hdf5')
futures_data=h5['futres_data']
options_data=ht['options_data']
h5.close()

用另一种方法读取hdf文件:
import h5py
hdfFile=h5py.File('D:/机器学习算法/Python与金融应用/Python/sources/vstoxx_data_31032014.hdf5','r')
futures_data=hdfFile.get('futures_data')
options_data=hdfFile.get('options_data')
hdfFile.close()
但是这里我遇到一个问题就是:
print(futures_data.shape()
Error是:

去了解了一下HDF5文件数据,发现里面是有group和datasets属性,
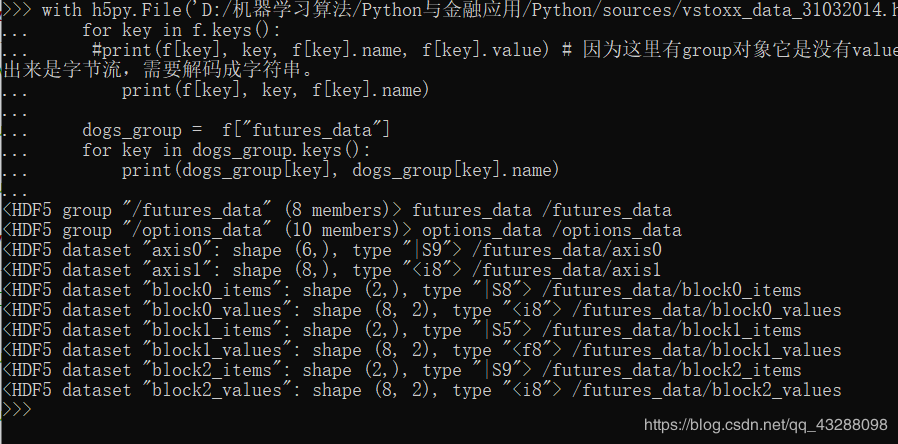 所以futures_data=hdfFile.get(‘futures_data’) 这里得到的是group?
所以futures_data=hdfFile.get(‘futures_data’) 这里得到的是group?
后来用另外一种读法还是不行:
import h5py
hdfFile=h5py.File('D:/机器学习算法/Python与金融应用/Python/sources/vstoxx_data_31032014.hdf5','r')
futures_data_group=hdfFile['futures_data']
futures_data=futures_data_group[:]
options_data_group=hdfFile['options_data']
options_data=options_data_group[:]
hdfFile.close()
print(futures_data.shape())
报错:
AttributeError: 'slice' object has no attribute 'encode'
‘futures_data’ group下面有8个datasets:
futures_data /futures_data
/futures_data/axis0
<HDF5 dataset "axis1": shape (8,), type " /futures_data/axis1
/futures_data/block0_items
<HDF5 dataset "block0_values": shape (8, 2), type " /futures_data/block0_values
/futures_data/block1_items
<HDF5 dataset "block1_values": shape (8, 2), type " /futures_data/block1_values
/futures_data/block2_items
<HDF5 dataset "block2_values": shape (8, 2), type " /futures_data/block2_values
用了一个笨方法来读取group 下面datasets:
# Columns: [b'DATE', b'EXP_YEAR', b'EXP_MONTH', b'PRICE', b'MATURITY', b'TTM']
import pandas as pd
import h5py
from pandas import to_datetime
hdfFile=h5py.File('D:/机器学习算法/Python与金融应用/Python/sources/vstoxx_data_31032014.hdf5','r')
futures_data=pd.DataFrame(columns=hdfFile['/futures_data/axis0'],index=hdfFile['/futures_data/axis1'])
block0_values=pd.DataFrame(hdfFile['/futures_data/block0_values'],columns=hdfFile['/futures_data/block0_items'],index=hdfFile['/futures_data/axis1'])
block1_values=pd.DataFrame(hdfFile['/futures_data/block1_values'],columns=hdfFile['/futures_data/block1_items'],index=hdfFile['/futures_data/axis1'])
block2_values=pd.DataFrame(hdfFile['/futures_data/block2_values'],columns=hdfFile['/futures_data/block2_items'],index=hdfFile['/futures_data/axis1'])
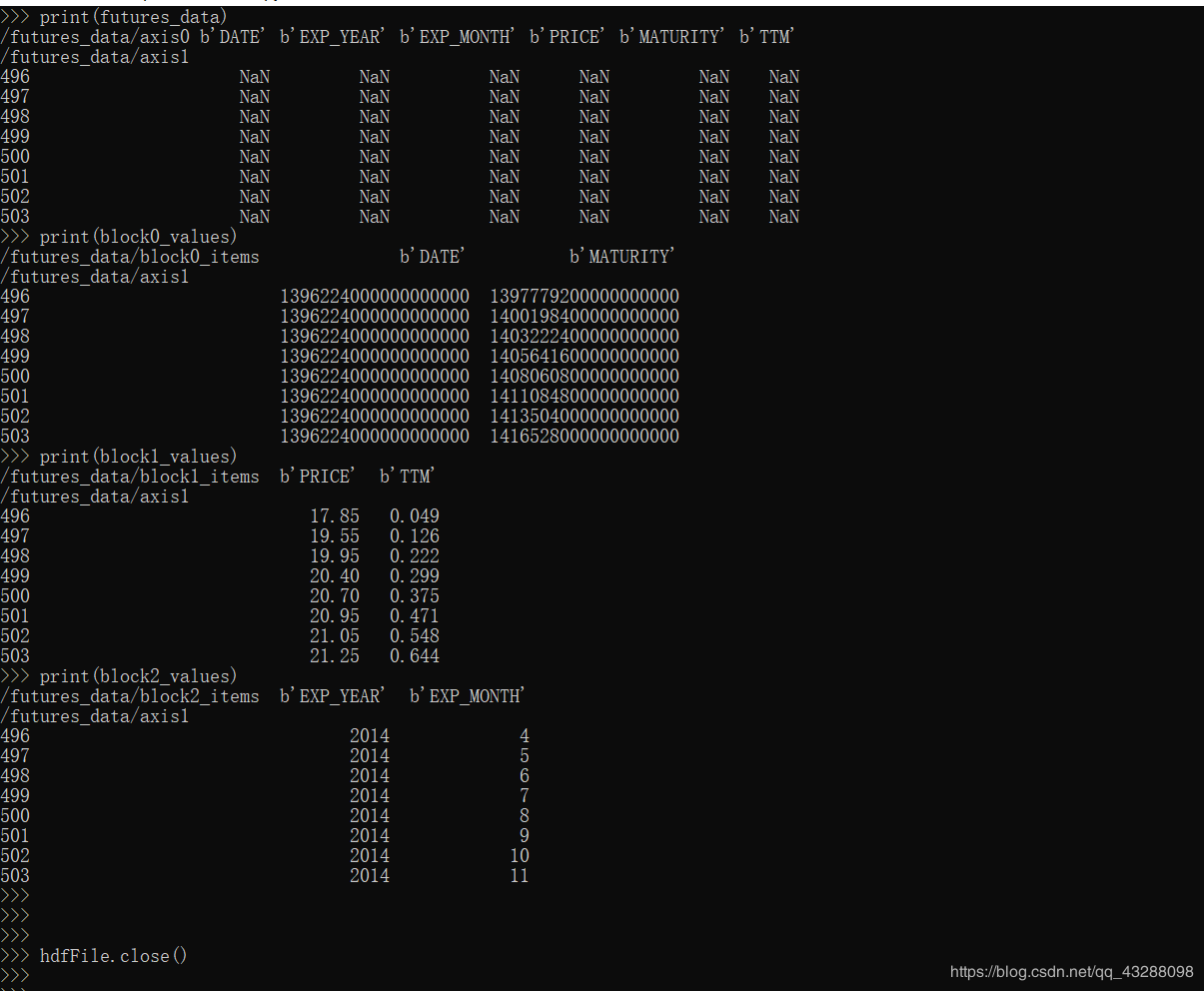
print(futures_data)
print(block0_values)
print(block1_values)
print(block2_values)
hdfFile.close()
结果是
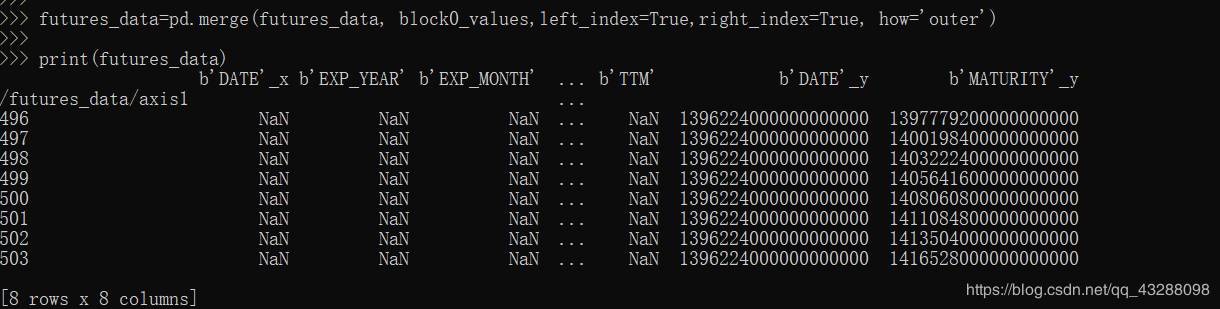
 现在的问题是怎么把这几个dataframe进行合并,但是用pd.merge的时候,发现还是有问题,就是列名相同的列值不是合并,而是重命名了两列,头疼。。。
现在的问题是怎么把这几个dataframe进行合并,但是用pd.merge的时候,发现还是有问题,就是列名相同的列值不是合并,而是重命名了两列,头疼。。。
futures_data=pd.merge(futures_data, block1_values,left_index=True,right_index,how='outer')
结果是:
更新于2020/03/29 23:40
朋友建议删改列名,突然灵光一闪,为何不直接merge最后三个dataframe?!
# Columns: [b'DATE', b'EXP_YEAR', b'EXP_MONTH', b'PRICE', b'MATURITY', b'TTM']
import pandas as pd
import h5py
from pandas import to_datetime
hdfFile=h5py.File('D:/机器学习算法/Python与金融应用/Python/sources/vstoxx_data_31032014.hdf5','r')
futures_data=pd.DataFrame(columns=hdfFile['/futures_data/axis0'],index=hdfFile['/futures_data/axis1'])
block0_values=pd.DataFrame(hdfFile['/futures_data/block0_values'],columns=hdfFile['/futures_data/block0_items'],index=hdfFile['/futures_data/axis1'])
block1_values=pd.DataFrame(hdfFile['/futures_data/block1_values'],columns=hdfFile['/futures_data/block1_items'],index=hdfFile['/futures_data/axis1'])
block2_values=pd.DataFrame(hdfFile['/futures_data/block2_values'],columns=hdfFile['/futures_data/block2_items'],index=hdfFile['/futures_data/axis1'])
temp_data=pd.merge(block0_values, block1_values,left_index=True,right_index=True,how='outer')
futures_data=pd.merge(temp_data,block2_values,left_index=True,right_index=True,how='outer')
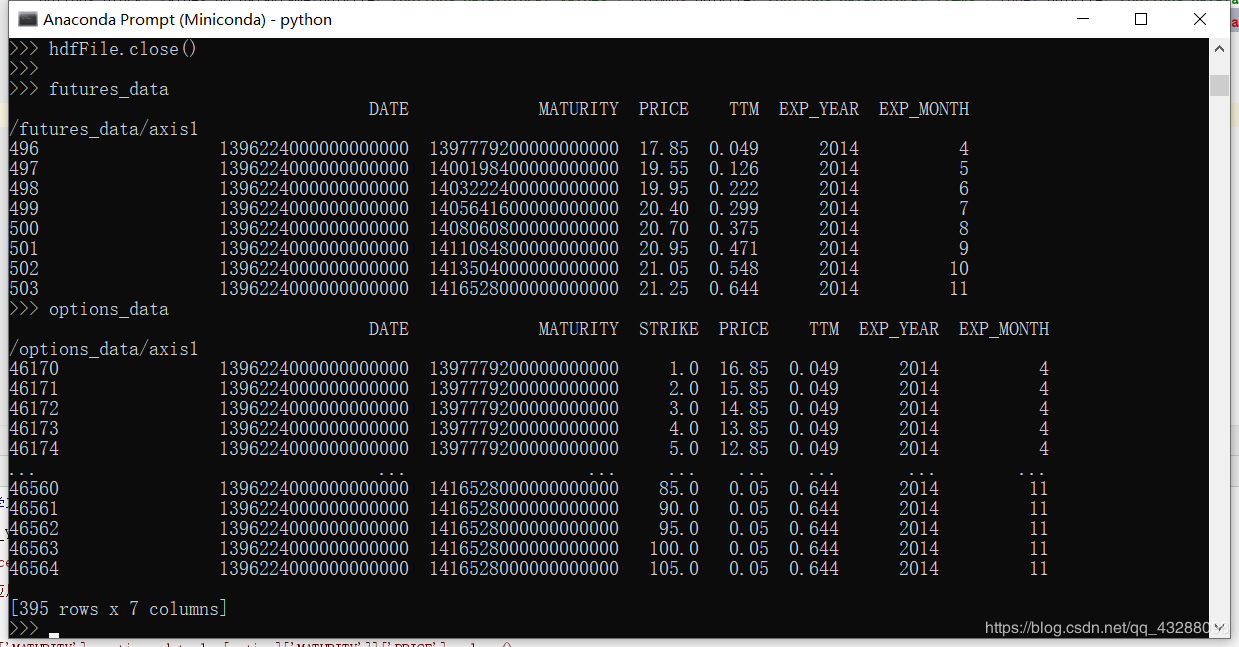
print(futures_data)
hdfFile.close()
结果:
>>> print(futures_data)
b'DATE' b'MATURITY' b'PRICE' b'TTM' b'EXP_YEAR' b'EXP_MONTH'
/futures_data/axis1
496 1396224000000000000 1397779200000000000 17.85 0.049 2014 4
497 1396224000000000000 1400198400000000000 19.55 0.126 2014 5
498 1396224000000000000 1403222400000000000 19.95 0.222 2014 6
499 1396224000000000000 1405641600000000000 20.40 0.299 2014 7
500 1396224000000000000 1408060800000000000 20.70 0.375 2014 8
501 1396224000000000000 1411084800000000000 20.95 0.471 2014 9
502 1396224000000000000 1413504000000000000 21.05 0.548 2014 10
503 1396224000000000000 1416528000000000000 21.25 0.644 2014 11
>>> hdfFile.close()
但是name 带有b,还有字符串怎么以日期形式显示,待解决。。。
更新于2020/03/30
直接用了重命名的方式解决了列命名问题,日期的话用pandas.to_datetime函数进行了转换,下面把整个项目的代码完整贴上来:
#Python在金融场景的应用
#例子1:隐含波动率
#一般使用Newton等梯度下降方法求解
#期权公式:t=0时Python计算公式
def bsm_call_value(S0,K,T,r,sigma):
from math import log,sqrt,exp
from scipy import stats
S0=float(S0) #对数据进行转换:转换成浮点数据
d1=(log(S0/K)+(r+0.5*sigma**2)*T)/(sigma*sqrt(T))
d2=(log(S0/K)+(r-0.5*sigma**2)*T)/(sigma*sqrt(T))
value=(S0*stats.norm.cdf(d1,0.0,1.0))-K*exp(-r*T)*stats.norm.cdf(d2,0.0,1.0)
return value
def bsm_vega(S0,K,T,r,sigma): #即梯度;期权定价公式关于波动率的一阶导数称为期权的Vega
from math import log,sqrt
from scipy import stats
S0=float(S0)
d1=(log(S0/K)+(r+0.5*sigma**2)*T)/(sigma*sqrt(T))
vega=S0*stats.norm.pdf(d1,0.0,1.0)*sqrt(T)
return vega
def bsm_call_imp_vol(S0,K,T,r,C0,sigma_est,it=100):#C0期权初始价格,sigma_est初始值,it即循环次数,默认100
for i in range(it):
sigma_est-=((bsm_call_value(S0,K,T,r,sigma_est)-C0)/bsm_vega(S0,K,T,r,sigma_est))
return sigma_est
V0=17.6639
r=0.01
#读取源数据
# Columns: [b'DATE', b'EXP_YEAR', b'EXP_MONTH', b'PRICE', b'MATURITY', b'TTM']
import pandas as pd
import h5py
from pandas import to_datetime
hdfFile=h5py.File('D:/机器学习算法/Python与金融应用/Python/sources/vstoxx_data_31032014.hdf5','r')
#futures_data=pd.DataFrame(columns=hdfFile['/futures_data/axis0'],index=hdfFile['/futures_data/axis1'])
block0_values=pd.DataFrame(hdfFile['/futures_data/block0_values'],columns=hdfFile['/futures_data/block0_items'],index=hdfFile['/futures_data/axis1'])
block1_values=pd.DataFrame(hdfFile['/futures_data/block1_values'],columns=hdfFile['/futures_data/block1_items'],index=hdfFile['/futures_data/axis1'])
block2_values=pd.DataFrame(hdfFile['/futures_data/block2_values'],columns=hdfFile['/futures_data/block2_items'],index=hdfFile['/futures_data/axis1'])
temp_data=pd.merge(block0_values, block1_values,left_index=True,right_index=True,how='outer')
futures_data=pd.merge(temp_data,block2_values,left_index=True,right_index=True,how='outer')
futures_data.columns=['DATE' ,'MATURITY' ,'PRICE' ,'TTM' ,'EXP_YEAR' ,'EXP_MONTH']
print(futures_data.columns.values)
#options data
options_block0_values=pd.DataFrame(hdfFile['/options_data/block0_values'],columns=hdfFile['/options_data/block0_items'],index=hdfFile['/options_data/axis1'])
options_block1_values=pd.DataFrame(hdfFile['/options_data/block1_values'],columns=hdfFile['/options_data/block1_items'],index=hdfFile['/options_data/axis1'])
options_block2_values=pd.DataFrame(hdfFile['/options_data/block2_values'],columns=hdfFile['/options_data/block2_items'],index=hdfFile['/options_data/axis1'])
# options_block3_values=pd.DataFrame(hdfFile['/options_data/block3_values'],columns=hdfFile['/options_data/block3_items'],index=hdfFile['/options_data/axis1'])
options_temp_data1=pd.merge(options_block0_values, options_block1_values,left_index=True,right_index=True,how='outer')
options_data=pd.merge(options_temp_data1,options_block2_values,left_index=True,right_index=True,how='outer')
options_data.columns=['DATE' ,'MATURITY','STRIKE' ,'PRICE' ,'TTM' ,'EXP_YEAR' ,'EXP_MONTH']
print(options_data.columns.values)
hdfFile.close()
import numpy as np
options_data['IMP_VOL']=0.0 #添加一列隐含波动率
#对每一个期权合约求imp_vol
#要求期权的执行价格不超出forward price
#否则出现定价错误
tol=0.5
for option in options_data.index:
forward=futures_data[futures_data['MATURITY']==options_data.loc[option]['MATURITY']]['PRICE'].values[0] #找到到期期权的价格
if (forward*(1-tol)<options_data.loc[option]['STRIKE'] 0]
maturities = sorted(set(options_data['MATURITY'])) # 得到到期日集合
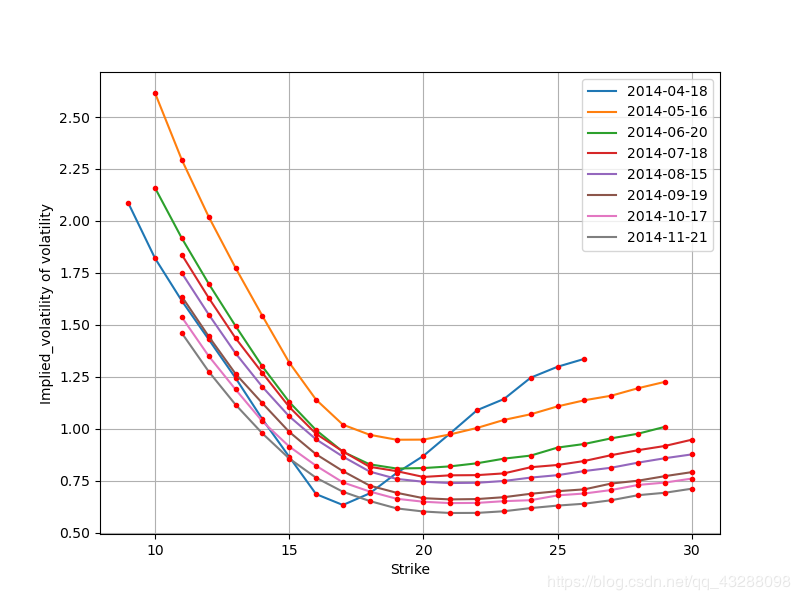
import matplotlib.pyplot as plt
#% matplotlib inline
plt.figure(figsize=(8, 6))
for maturity in maturities:
data = plot_data[options_data.MATURITY == maturity]
plt.plot(data['STRIKE'], # x轴
data['IMP_VOL'], # y轴
label=maturity.date(), lw=1.5)
plt.plot(data['STRIKE'], data['IMP_VOL'], 'r.')
plt.grid()
plt.xlabel('Strike')
plt.ylabel('Implied_volatility of volatility')
plt.legend()
plt.show()
图片结果如下:
 其他注意点以及想法:
其他注意点以及想法:
1.视频里面画图的时候label=maturities.date(),发现报错,所以改成了maturity.date()
2.读取hdf5文件的时候,有没有pd.DataFrame([hdfFile[’/futures_data/block0_values’],hdfFile[‘futures_data/block1_values’]…])类似这样的语法可以批量把dataset读进一个DataFrame里面?
作者:chau.z