使用Python对英雄联盟英雄数据进行聚类等分析 (字符串离散化)
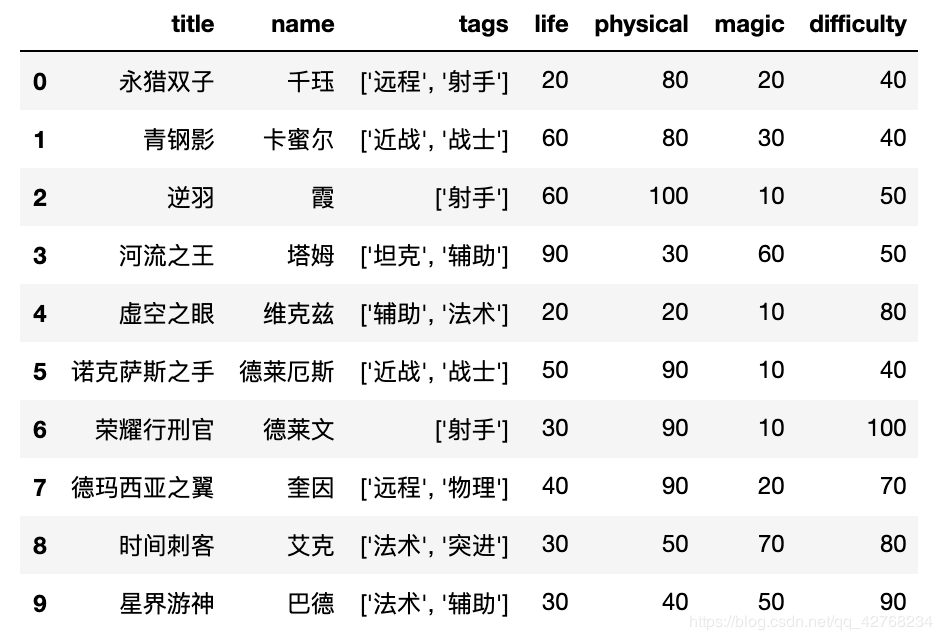
上图是我们本次需要分析的数据, 有一个 tags 标签, 它代表每个英雄的属性, 每英雄的属性有多个, 他们房子一个列表里 (类型是字符串) 我们第一步做的就是将它拆分, 将数据变为 宽数据
首先我们需要将 tag 中所有的类别提取出来, 然后再创建一个与原数据同长, 与类别同宽的全为 0 的数组, 然后遍历原数据中的 tags 对应位置上的 0 改为 1import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv(r"lol_hero.csv", index_col=0)
temp_list = [eval(x) for x in df["tags"].tolist()] # 将tags提取出来
tag_all = set([j for i in temp_list for j in i]) # set(将所有属性遍历出来)
print(tag_all)
# 输出的结果
{'刺客','坦克','射手','战士',
'打野','控制','法师','法术',
'爆发','物理','突进','辅助',
'输出','近战','远程','魔法'}
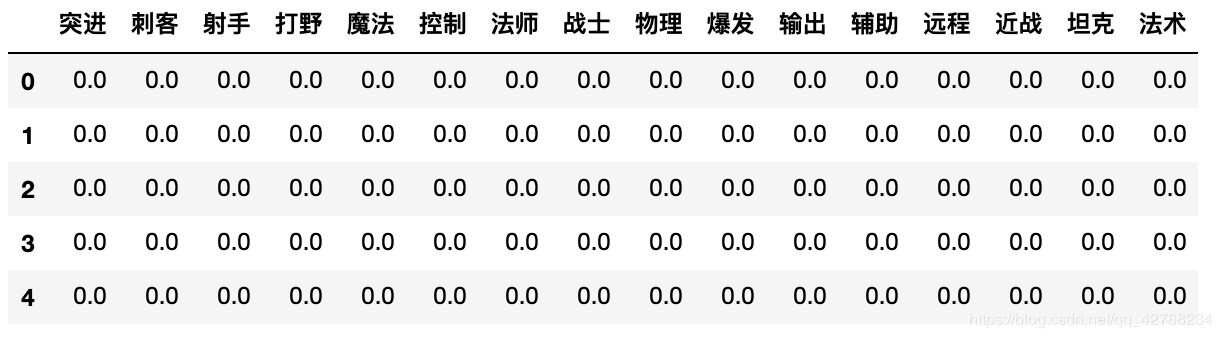
创建为 0 的数组
zeros_data = pd.DataFrame(np.zeros((df.shape[0], len(tag_all))), columns=list(tag_all))
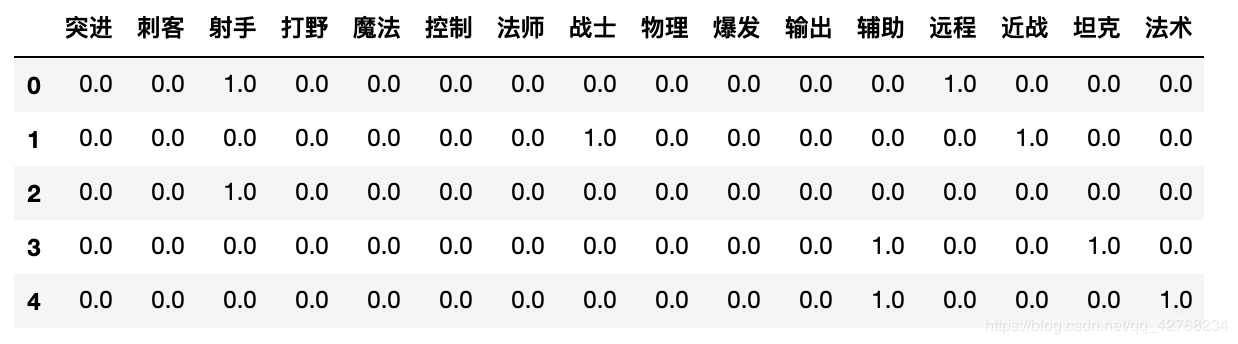
遍历原数据并赋值
for i in range(df.shape[0]):
zeros_data.loc[i, temp_list[i]] = 1
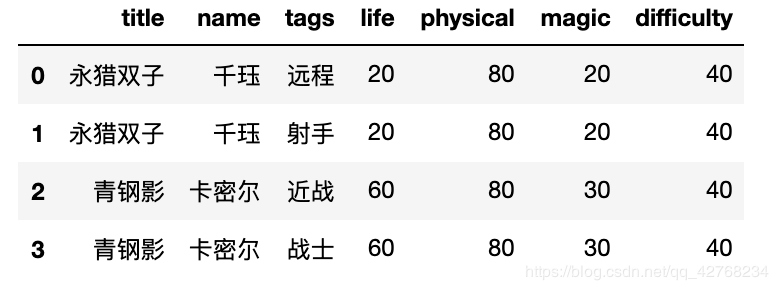
将两个数据集合并
data = pd.concat([df, zeros_data], axis=1).drop(labels="tags", axis=1)
现在我们就得到了 宽数据 如下图 :

 特点分析: 长数据 往往不会记录缺失值, 而 宽数据 为了保持数据的一致性则需要记录, 对于长数据而言, 对于 维护性 (增减观测值) 非常方便, 数据的增减只需要处理一行数据, 那么宽数据需要操作列, 比如英雄属性新增了一个属性, 那么我们就需要新加一列, 在常见的数据库里, 这种操作相对来说比较难实现, 所以宽类型数据几乎不会在数据库中使用, 从 占用内存 的角度分析, 长数据 在存储中, 会多出很多 “无效” 数据, 当然, 内存的差异往往在较大的数据中才会体现, 宽数据在较大数据时的性能比较好, 同时存储在硬盘里也会更小
二、数据初探
特点分析: 长数据 往往不会记录缺失值, 而 宽数据 为了保持数据的一致性则需要记录, 对于长数据而言, 对于 维护性 (增减观测值) 非常方便, 数据的增减只需要处理一行数据, 那么宽数据需要操作列, 比如英雄属性新增了一个属性, 那么我们就需要新加一列, 在常见的数据库里, 这种操作相对来说比较难实现, 所以宽类型数据几乎不会在数据库中使用, 从 占用内存 的角度分析, 长数据 在存储中, 会多出很多 “无效” 数据, 当然, 内存的差异往往在较大的数据中才会体现, 宽数据在较大数据时的性能比较好, 同时存储在硬盘里也会更小
二、数据初探
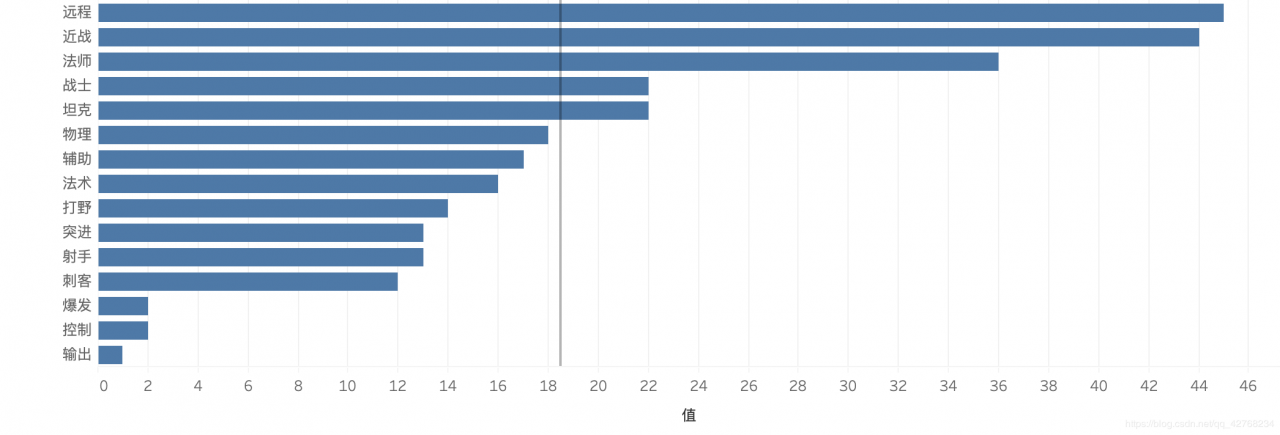
得到了字符串离散化的数据我们可以统计每种属性对应英雄的数量
将英雄 操作难度 和 防御级别 分级看看可以获得什么信息
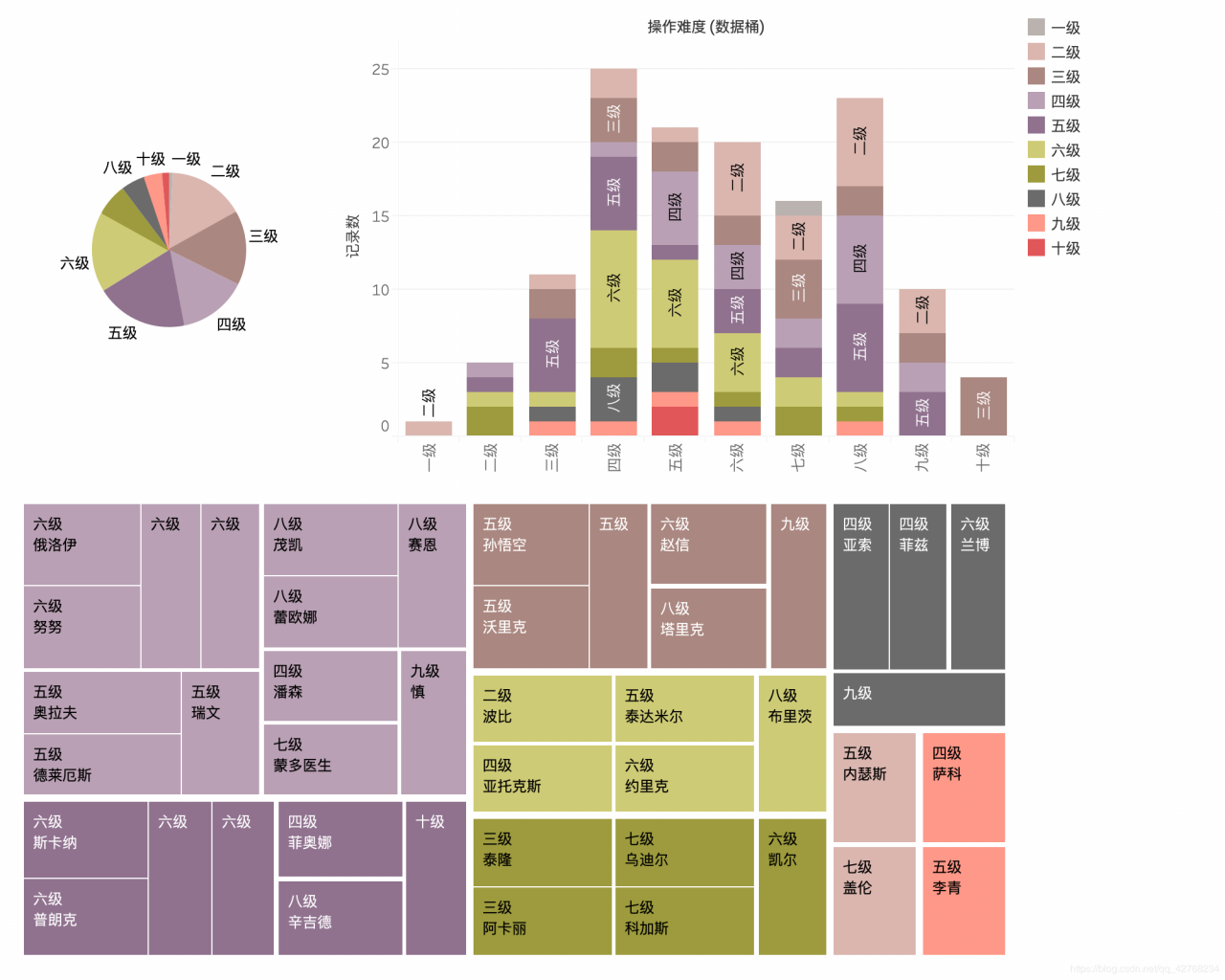
条形图: 横着代码操作难度级别, 颜色代码防御级别, 下图颜色表示 操作难度 分级
我们可以看到操作难度有十级的英雄他们有一个共同的特征, 就是防御属性都为 三级 也就是小脆皮 防御力高的英雄难度大部分分布在 四级-六级 之间
我们试一试使用 k-means 能否得到满意的结果
import pandas as pd
from sklearn.cluster import KMeans
df = pd.read_csv(r"lol_hero.csv", index_col=0)
df1 = data[["life", "physical", "magic", "difficulty"]]
kmodel = KMeans(n_clusters=10, n_jobs=4)
kmodel.fit(df1)
temp_label = kmodel.labels_.tolist()
df["type"] = temp_label
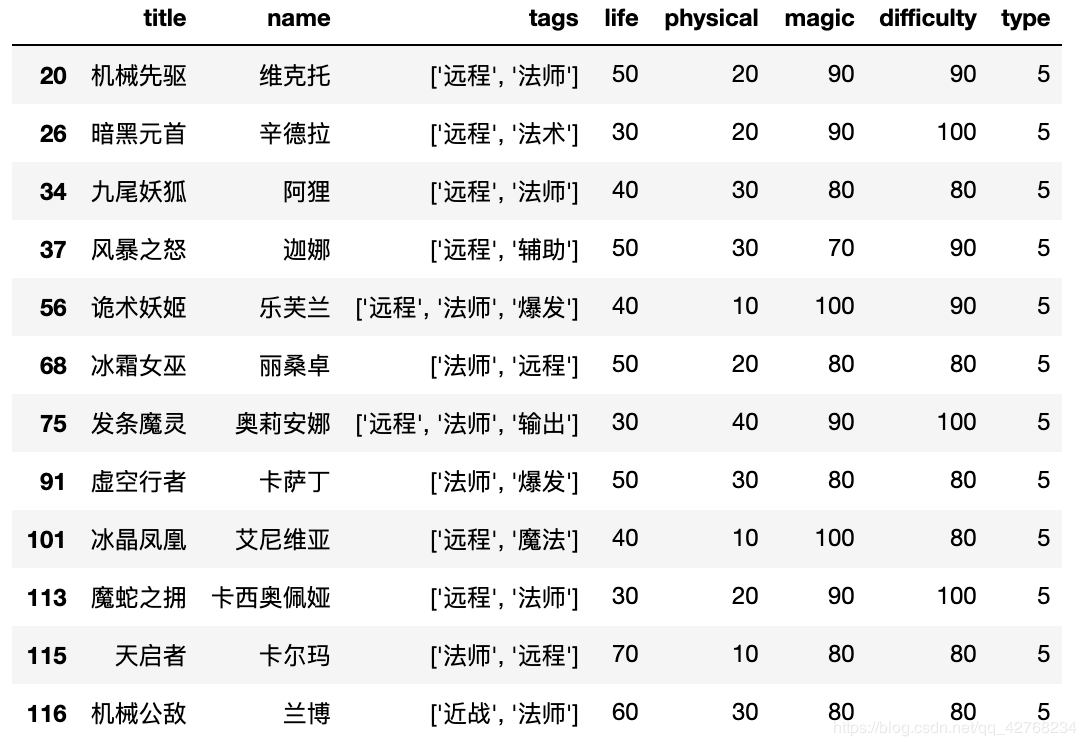
print(df[df["type"] == 1])
随便输出一类发现这类的特点都属于 AP 加成比较高的英雄
作者:Fantasy!