Chemistry.AI | 基于循环神经网络(RNN)预测分子性质
Chemistry.AI | 基于卷积神经网络(CNN)预测分子特性
环境准备 Python版本:Python 3.6.8 PyTorch版本:PyTorch1.1.0 RDKit版本:RDKit 2020.03.1 基于循环神经网络(RNN)预测分子性质导入库
from rdkit import Chem
from rdkit.Chem.Crippen import MolLogP
import numpy as np
import torch
import time
载入数据,计算分子指纹和描述符
maxlen = 64
with open('smiles.txt') as f:
smiles = f.readlines()[:]
smiles = [s.strip() for s in smiles]
smiles = [s.split()[1] for s in smiles]
smiles = [s for s in smiles if len(s)<maxlen]
#Characters of smiles
all_smiles=''
for s in smiles: all_smiles+=s
chars = sorted(list(set(list(all_smiles))))
c_to_i = {c:i for i,c in enumerate(chars)}
print ('Max len:', maxlen)
print ('Number of chars:', len(chars))
print (chars)
print (c_to_i)
Max len: 64
Number of chars: 45
['#', '(', ')', '+', '-', '.', '/', '1', '2', '3', '4', '5', '6', '7', '=', '@', 'B', 'C', 'F', 'G', 'H', 'I', 'K', 'L', 'M', 'N', 'O', 'P', 'S', 'V', 'Z', '[', '\\', ']', 'a', 'c', 'e', 'g', 'i', 'l', 'n', 'o', 'r', 's', 'u']
{'#': 0, '(': 1, ')': 2, '+': 3, '-': 4, '.': 5, '/': 6, '1': 7, '2': 8, '3': 9, '4': 10, '5': 11, '6': 12, '7': 13, '=': 14, '@': 15, 'B': 16, 'C': 17, 'F': 18, 'G': 19, 'H': 20, 'I': 21, 'K': 22, 'L': 23, 'M': 24, 'N': 25, 'O': 26, 'P': 27, 'S': 28, 'V': 29, 'Z': 30, '[': 31, '\\': 32, ']': 33, 'a': 34, 'c': 35, 'e': 36, 'g': 37, 'i': 38, 'l': 39, 'n': 40, 'o': 41, 'r': 42, 's': 43, 'u': 44}
计算每个分子的分子指纹和描述符
Y = []
num_data = 20000
st = time.time()
for s in smiles[:num_data]:
m = Chem.MolFromSmiles(s)
logp = MolLogP(m)
Y.append(logp)
#Y.append(1)
end = time.time()
print (f'Time:{(end-st):.3f}')
数据批处理
#Dataset
from torch.utils.data import Dataset, DataLoader
class MolDataset(Dataset):
def __init__(self, smiles, properties, c_to_i, maxlen):
self.c_to_i = c_to_i
self.maxlen = maxlen
self.smiles = smiles
self.properties = properties
def __len__(self):
return len(self.smiles)
def __getitem__(self, idx):
s = self.smiles[idx]
i = torch.from_numpy(np.array([c_to_i[c] for c in s]))
sample = dict()
sample['X'] = i
sample['L'] = len(s)
sample['Y'] = self.properties[idx]
return sample
#Collate fn
def my_collate(batch):
sample = dict()
X = torch.nn.utils.rnn.pad_sequence([b['X'] for b in batch], batch_first=True, padding_value = 45)
Y = torch.Tensor([b['Y'] for b in batch])
L = torch.Tensor([b['L'] for b in batch])
sample['X'] = X
sample['Y'] = Y
sample['L'] = L
return sample
定义RNN模型
#Model
import torch
import torch.nn as nn
import torch.nn.functional as F
class RNNRegressor(torch.nn.Module):
def __init__(self, n_feature=128, n_rnn_layer = 1, n_char=46):
super(RNNRegressor, self).__init__()
self.rnn = nn.GRU(input_size=n_feature, hidden_size=n_feature, num_layers=n_rnn_layer)
self.fc = nn.Linear(n_feature, 1)
self.embedding = nn.Embedding(n_char, n_feature)
def forward(self, x, l):
x = self.embedding(x)
x = x.permute((1,0,2))
output, h = self.rnn(x)
selected = []
for i in range(len(l)):
valid_h = h[:l[i]-1,i]
valid_h = torch.mean(valid_h, 0)
selected.append(valid_h)
selected = torch.stack(selected)
retval = self.fc(selected)
return retval
训练模型
#Train model
import time
lr = 1e-4
model = RNNRegressor(64, 1, 46).cuda()
#Dataset
train_smiles = smiles[:19000]
test_smiles = smiles[19000:20000]
train_logp = Y[:19000]
test_logp = Y[19000:20000]
train_dataset = MolDataset(train_smiles, train_logp, c_to_i, maxlen)
test_dataset = MolDataset(test_smiles, test_logp, c_to_i, maxlen)
#Dataloader
train_dataloader = DataLoader(train_dataset, batch_size=128, num_workers=1, collate_fn=my_collate)
test_dataloader = DataLoader(test_dataset, batch_size=128, num_workers=1, collate_fn=my_collate)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
#optimizer = torch.optim.SGD(model.parameters(), lr=lr)
loss_fn = nn.MSELoss()
loss_list = []
st = time.time()
for epoch in range(20):
epoch_loss = []
for i_batch, batch in enumerate(train_dataloader):
x, y, l = \
batch['X'].cuda().long(), batch['Y'].cuda().float(), batch['L'].cuda().long()
pred = model(x, l).squeeze(-1)
loss = loss_fn(pred, y)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
loss_list.append(loss.data.cpu().numpy())
epoch_loss.append(loss.data.cpu().numpy())
if True: print (epoch, np.mean(np.array(epoch_loss)))
end = time.time()
print ('Time:', end-st)
0 5.3075666
1 3.9476352
2 3.7014515
3 3.0184703
4 2.3332028
5 1.8761007
6 1.3051379
7 0.9804973
8 0.7861054
9 0.65022063
10 0.5559791
11 0.4898691
12 0.44078177
13 0.40346482
14 0.37828985
15 0.3515944
16 0.33561063
17 0.32390222
18 0.3072901
19 0.2942933
Time: 117.68075275421143
保存模型
#Save model
fn = 'save.pt'
torch.save(model.state_dict(), fn)
加载模型
#Load model
model.load_state_dict(torch.load(fn))
绘制损失曲线
import matplotlib.pyplot as plt
plt.plot(loss_list)
plt.xlabel('Num iteration')
plt.ylabel('Loss')
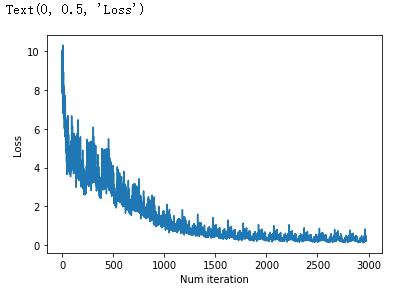
测试模型
#Test model
model.eval()
with torch.no_grad():
y_pred_train, y_pred_test = [], []
loss_train, loss_test = [], []
pred_train, pred_test = [], []
true_train, true_test = [], []
for batch in train_dataloader:
x, y, l = \
batch['X'].cuda().long(), batch['Y'].cuda().float(), batch['L'].cuda().long()
pred = model(x, l).squeeze(-1)
pred_train.append(pred.data.cpu().numpy())
true_train.append(y.data.cpu().numpy())
loss_train.append(loss_fn(y, pred).data.cpu().numpy())
for batch in test_dataloader:
x, y, l = \
batch['X'].cuda().long(), batch['Y'].cuda().float(), batch['L'].cuda().long()
pred = model(x, l).squeeze(-1)
pred_test.append(pred.data.cpu().numpy())
true_test.append(y.data.cpu().numpy())
loss_test.append(loss_fn(y, pred).data.cpu().numpy())
pred_train = np.concatenate(pred_train, -1)
pred_test = np.concatenate(pred_test, -1)
true_train = np.concatenate(true_train, -1)
true_test = np.concatenate(true_test, -1)
print ('Train loss:', np.mean(np.array(loss_train)))
print ('Test loss:', np.mean(np.array(loss_test)))
Train loss: 0.290517
Test loss: 0.21602286
plt.scatter(true_train, pred_train, s=1)
plt.scatter(true_test, pred_test, s=1)
plt.plot([-8,12], [-8,12])
plt.xlabel('True')
plt.ylabel('Pred')
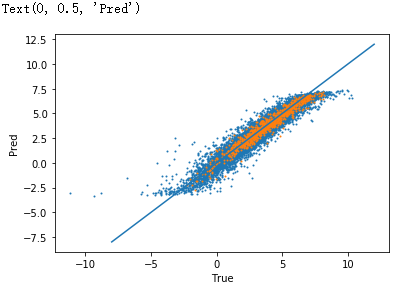
作者:qq2648008726