Task02 循环神经网络基础
循环神经网络
作者:l_yiyu
本节介绍循环神经网络,下图展示了如何基于循环神经网络实现语言模型。
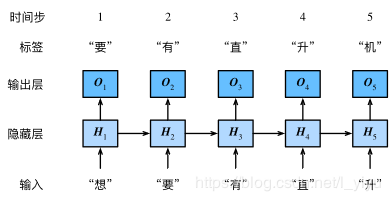
循环神经网络中较容易出现梯度衰减或梯度爆炸,这会导致网络几乎无法训练。裁剪梯度(clip gradient)是一种应对梯度爆炸的方法。假设我们把所有模型参数的梯度拼接成一个向量 g ,并设裁剪的阈值是 θ 。裁剪后的梯度
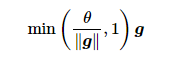
的 L2 范数不超过 θ 。
我们通常使用困惑度(perplexity)来评价语言模型的好坏。回忆一下“softmax回归”一节中交叉熵损失函数的定义。困惑度是对交叉熵损失函数做指数运算后得到的值。特别地,
▪最佳情况下,模型总是把标签类别的概率预测为1,此时困惑度为1;
▪最坏情况下,模型总是把标签类别的概率预测为0,此时困惑度为正无穷;
▪基线情况下,模型总是预测所有类别的概率都相同,此时困惑度为类别个数。
显然,任何一个有效模型的困惑度必须小于类别个数。在本例中,困惑度必须小于词典大小vocab_size。
import time
import math
import numpy as np
import torch
from torch import nn, optim
import torch.nn.functional as F
import sys
sys.path.append(".")
import d2lzh_pytorch as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
(corpus_indices, char_to_idx, idx_to_char, vocab_size) = d2l.load_data_jay_lyrics()
定义一个完整的基于循环神经网络的语言模型 RNNModel
class RNNModel(nn.Module):
def __init__(self, rnn_layer, vocab_size):
super(RNNModel, self).__init__()
self.rnn = rnn_layer
self.hidden_size = rnn_layer.hidden_size * (2 if rnn_layer.bidirectional else 1)
self.vocab_size = vocab_size
self.dense = nn.Linear(self.hidden_size, vocab_size)
def forward(self, inputs, state):
# inputs.shape: (batch_size, num_steps)
X = to_onehot(inputs, vocab_size)
X = torch.stack(X) # X.shape: (num_steps, batch_size, vocab_size)
hiddens, state = self.rnn(X, state)
hiddens = hiddens.view(-1, hiddens.shape[-1]) # hiddens.shape: (num_steps * batch_size, hidden_size)
output = self.dense(hiddens)
return output, state
实现一个预测函数 predict_rnn_pytorch
def predict_rnn_pytorch(prefix, num_chars, model, vocab_size, device, idx_to_char,
char_to_idx):
state = None
output = [char_to_idx[prefix[0]]] # output记录prefix加上预测的num_chars个字符
for t in range(num_chars + len(prefix) - 1):
X = torch.tensor([output[-1]], device=device).view(1, 1)
(Y, state) = model(X, state) # 前向计算不需要传入模型参数
if t < len(prefix) - 1:
output.append(char_to_idx[prefix[t + 1]])
else:
output.append(Y.argmax(dim=1).item())
return ''.join([idx_to_char[i] for i in output])
使用权重为随机值的模型来预测一次
model = RNNModel(rnn_layer, vocab_size).to(device)
out = predict_rnn_pytorch('分开', 10, model, vocab_size, device, idx_to_char, char_to_idx)
print(out)
运行结果:“分开虽峡雅泣漂水区幽峡远”
训练模型接下来实现训练函数,这里只使用了相邻采样。
def train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes):
loss = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
model.to(device)
for epoch in range(num_epochs):
l_sum, n, start = 0.0, 0, time.time()
data_iter = d2l.data_iter_consecutive(corpus_indices, batch_size, num_steps, device) # 相邻采样
state = None
for X, Y in data_iter:
if state is not None:
# 使用detach函数从计算图分离隐藏状态
if isinstance(state, tuple): # LSTM, state:(h, c)
state[0].detach_()
state[1].detach_()
else:
state.detach_()
(output, state) = model(X, state) # output.shape: (num_steps * batch_size, vocab_size)
y = torch.flatten(Y.T)
l = loss(output, y.long())
optimizer.zero_grad()
l.backward()
d2l.grad_clipping(model.parameters(), clipping_theta, device)
optimizer.step()
l_sum += l.item() * y.shape[0]
n += y.shape[0]
if (epoch + 1) % pred_period == 0:
print('epoch %d, perplexity %f, time %.2f sec' % (
epoch + 1, math.exp(l_sum / n), time.time() - start))
for prefix in prefixes:
print(' -', predict_rnn_pytorch(
prefix, pred_len, model, vocab_size, device, idx_to_char,
char_to_idx))
训练模型
num_steps = 35
num_epochs, batch_size, lr, clipping_theta = 250, 32, 1e-3, 1e-2
pred_period, pred_len, prefixes = 50, 50, ['分开', '不分开']
train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes)
训练结果:
epoch 50, perplexity 11.040127, time 0.09 sec
- 分开 一场悲剧 我不能 想你我不 我想 我不你我想 你想要你不多 我不你这样 我不能再想 我不能再想 我
- 不分开 我想你的可爱 我想要你 你 你 我不了 我 你不了我想 我不要再想 我不要再想 我不要再想 我不
epoch 100, perplexity 1.303758, time 0.10 sec
- 分开 我开始的可 静说就是你场那口 不知道 一定会呵护著你 也逗你笑 你对我 想这样骑担车 我 想和
- 不分开 我这样没着 手不会不家不 是谁是你 心有轻重爱写 河愿前 纪录那最原始看美丽 纪录第一次遇见的
epoch 150, perplexity 1.067593, time 0.09 sec
- 分开 我开始的可 我说你怎么人已经 对我妈爸你 你不我 多你怎么离不是我想你 我不开不了不是不是你 想
- 不分开 我这样没着 的手不会不家听 一着了痛人 找不 我想要你的那 人已经不了我 你一定实现听错弄错
epoch 200, perplexity 1.036132, time 0.09 sec
- 分开 我开始的怒 我知道你已经离开始 不知不觉 我跟了这节奏 后知后觉 又过了一个秋 后知后觉 我该好
- 不分开 我这样的着口 泥知道 安排的雨 随时准备来袭 我怀念起国小的课桌椅 用铅笔写日记 纪录那最原始的美
epoch 250, perplexity 1.021187, time 0.09 sec
- 分开 我小碰听一 不要 这样的模样就 像说 没爱你人 以 想要再一个风 对你都很 不想 你说了这样牵着
- 不分开 我只多拿着 手了这怎么都也 有你 说你怎么面对 所有回忆对着我进攻 伤口 你拆封 誓言太
pytorch 全部代码
import time
import math
import numpy as np
import torch
from torch import nn, optim
import torch.nn.functional as F
import sys
sys.path.append(".")
import d2lzh_pytorch as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
(corpus_indices, char_to_idx, idx_to_char, vocab_size) = d2l.load_data_jay_lyrics()
# 模型定义
class RNNModel(nn.Module):
def __init__(self, rnn_layer, vocab_size):
super(RNNModel, self).__init__()
self.rnn = rnn_layer
self.hidden_size = rnn_layer.hidden_size * (2 if rnn_layer.bidirectional else 1)
self.vocab_size = vocab_size
self.dense = nn.Linear(self.hidden_size, vocab_size)
def forward(self, inputs, state):
# inputs.shape: (batch_size, num_steps)
X = d2l.to_onehot(inputs, vocab_size)
X = torch.stack(X) # X.shape: (num_steps, batch_size, vocab_size)
hiddens, state = self.rnn(X, state)
hiddens = hiddens.view(-1, hiddens.shape[-1]) # hiddens.shape: (num_steps * batch_size, hidden_size)
output = self.dense(hiddens)
return output, state
# 实现一个预测函数 predict_rnn_pytorch
def predict_rnn_pytorch(prefix, num_chars, model, vocab_size, device, idx_to_char,
char_to_idx):
state = None
output = [char_to_idx[prefix[0]]] # output记录prefix加上预测的num_chars个字符
for t in range(num_chars + len(prefix) - 1):
X = torch.tensor([output[-1]], device=device).view(1, 1)
(Y, state) = model(X, state) # 前向计算不需要传入模型参数
if t < len(prefix) - 1:
output.append(char_to_idx[prefix[t + 1]])
else:
output.append(Y.argmax(dim=1).item())
return ''.join([idx_to_char[i] for i in output])
num_inputs, num_hiddens, num_outputs = vocab_size, 256, vocab_size
rnn_layer = nn.RNN(input_size=vocab_size, hidden_size=num_hiddens)
#使用权重为随机值的模型来预测一次
model = RNNModel(rnn_layer, vocab_size).to(device)
out = predict_rnn_pytorch('分开', 10, model, vocab_size, device, idx_to_char, char_to_idx)
print(out)
def train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes):
loss = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
model.to(device)
for epoch in range(num_epochs):
l_sum, n, start = 0.0, 0, time.time()
data_iter = d2l.data_iter_consecutive(corpus_indices, batch_size, num_steps, device) # 相邻采样
state = None
for X, Y in data_iter:
if state is not None:
# 使用detach函数从计算图分离隐藏状态
if isinstance(state, tuple): # LSTM, state:(h, c)
state[0].detach_()
state[1].detach_()
else:
state.detach_()
(output, state) = model(X, state) # output.shape: (num_steps * batch_size, vocab_size)
y = torch.flatten(Y.T)
l = loss(output, y.long())
optimizer.zero_grad()
l.backward()
d2l.grad_clipping(model.parameters(), clipping_theta, device)
optimizer.step()
l_sum += l.item() * y.shape[0]
n += y.shape[0]
if (epoch + 1) % pred_period == 0:
print('epoch %d, perplexity %f, time %.2f sec' % (
epoch + 1, math.exp(l_sum / n), time.time() - start))
for prefix in prefixes:
print(' -', predict_rnn_pytorch(
prefix, pred_len, model, vocab_size, device, idx_to_char,
char_to_idx))
# 训练模型
num_steps = 35
num_epochs, batch_size, lr, clipping_theta = 250, 32, 1e-3, 1e-2
pred_period, pred_len, prefixes = 50, 50, ['分开', '不分开']
train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes)
代码中的d2l包中涉及的代码
def one_hot(x, n_class, dtype=torch.float32):
# X shape: (batch), output shape: (batch, n_class)
x = x.long()
res = torch.zeros(x.shape[0], n_class, dtype=dtype, device=x.device)
res.scatter_(1, x.view(-1, 1), 1)
return res
def to_onehot(X, n_class):
# X shape: (batch, seq_len), output: seq_len elements of (batch, n_class)
return [one_hot(X[:, i], n_class) for i in range(X.shape[1])]
def data_iter_consecutive(corpus_indices, batch_size, num_steps, device=None):
if device is None:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
corpus_indices = torch.tensor(corpus_indices, dtype=torch.float32, device=device)
data_len = len(corpus_indices)
batch_len = data_len // batch_size
indices = corpus_indices[0: batch_size*batch_len].view(batch_size, batch_len)
epoch_size = (batch_len - 1) // num_steps
for i in range(epoch_size):
i = i * num_steps
X = indices[:, i: i + num_steps]
Y = indices[:, i + 1: i + num_steps + 1]
yield X, Y
def grad_clipping(params, theta, device):
norm = torch.tensor([0.0], device=device)
for param in params:
norm += (param.grad.data ** 2).sum()
norm = norm.sqrt().item()
if norm > theta:
for param in params:
param.grad.data *= (theta / norm)
小结
•可以用基于字符级循环神经网络的语言模型来生成文本序列,例如创作歌词
•当训练循环神经网络时,为了应对梯度爆炸,可以裁剪梯度
•困惑度是对交叉熵损失函数做指数运算后得到的值,并用于评价语言模型的好坏
作者:l_yiyu