DL基于Pytorch Day3 循环神经网络进阶
1.GRU
作者:skymacro
RNN存在的问题:梯度较容易出现衰减或爆炸(BPTT)
⻔控循环神经⽹络:捕捉时间序列中时间步距离较⼤的依赖关系
RNN:
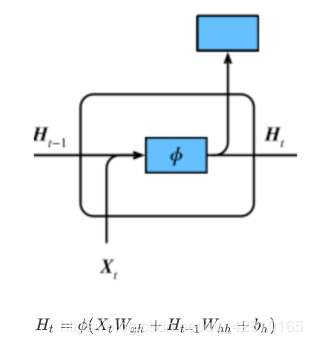
GRU:
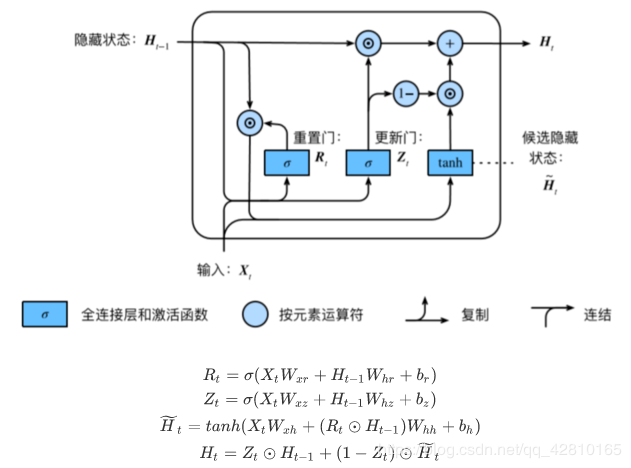
• 重置⻔有助于捕捉时间序列⾥短期的依赖关系;
• 更新⻔有助于捕捉时间序列⾥⻓期的依赖关系。
import os
os.listdir('/home/kesci/input')
Out[1]:
['d2lzh1981', 'houseprices2807', 'jaychou_lyrics4703', 'd2l_jay9460']
In [3]:
import numpy as np
import torch
from torch import nn, optim
import torch.nn.functional as F
In [4]:
import sys
sys.path.append("../input/")
import d2l_jay9460 as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
(corpus_indices, char_to_idx, idx_to_char, vocab_size) = d2l.load_data_jay_lyrics()
初始化参数
num_inputs, num_hiddens, num_outputs = vocab_size, 256, vocab_size
print('will use', device)
def get_params():
def _one(shape):
ts = torch.tensor(np.random.normal(0, 0.01, size=shape), device=device, dtype=torch.float32) #正态分布
return torch.nn.Parameter(ts, requires_grad=True)
def _three():
return (_one((num_inputs, num_hiddens)),
_one((num_hiddens, num_hiddens)),
torch.nn.Parameter(torch.zeros(num_hiddens, device=device, dtype=torch.float32), requires_grad=True))
W_xz, W_hz, b_z = _three() # 更新门参数
W_xr, W_hr, b_r = _three() # 重置门参数
W_xh, W_hh, b_h = _three() # 候选隐藏状态参数
# 输出层参数
W_hq = _one((num_hiddens, num_outputs))
b_q = torch.nn.Parameter(torch.zeros(num_outputs, device=device, dtype=torch.float32), requires_grad=True)
return nn.ParameterList([W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q])
def init_gru_state(batch_size, num_hiddens, device): #隐藏状态初始化
return (torch.zeros((batch_size, num_hiddens), device=device), )
//will use cpu
GRU模型
def gru(inputs, state, params):
W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
for X in inputs:
Z = torch.sigmoid(torch.matmul(X, W_xz) + torch.matmul(H, W_hz) + b_z)
R = torch.sigmoid(torch.matmul(X, W_xr) + torch.matmul(H, W_hr) + b_r)
H_tilda = torch.tanh(torch.matmul(X, W_xh) + R * torch.matmul(H, W_hh) + b_h)
H = Z * H + (1 - Z) * H_tilda
Y = torch.matmul(H, W_hq) + b_q
outputs.append(Y)
return outputs, (H,)
##训练模型
num_epochs, num_steps, batch_size, lr, clipping_theta = 160, 35, 32, 1e2, 1e-2
pred_period, pred_len, prefixes = 40, 50, ['分开', '不分开']
d2l.train_and_predict_rnn(gru, get_params, init_gru_state, num_hiddens,
vocab_size, device, corpus_indices, idx_to_char,
char_to_idx, False, num_epochs, num_steps, lr,
clipping_theta, batch_size, pred_period, pred_len,
prefixes)
简洁实现
num_hiddens=256
num_epochs, num_steps, batch_size, lr, clipping_theta = 160, 35, 32, 1e2, 1e-2
pred_period, pred_len, prefixes = 40, 50, ['分开', '不分开']
lr = 1e-2 # 注意调整学习率
gru_layer = nn.GRU(input_size=vocab_size, hidden_size=num_hiddens)
model = d2l.RNNModel(gru_layer, vocab_size).to(device)
d2l.train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes)
2.LSTM
长短期记忆long short-term memory :
遗忘门:控制上一时间步的记忆细胞 输入门:控制当前时间步的输入
输出门:控制从记忆细胞到隐藏状态
记忆细胞:⼀种特殊的隐藏状态的信息的流动
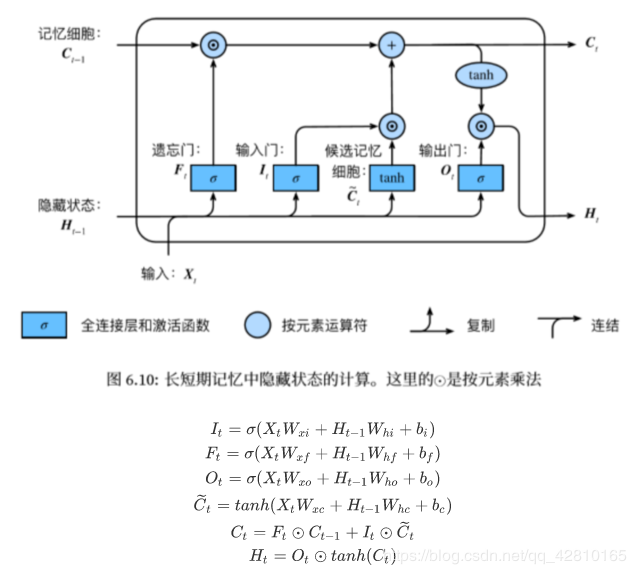
num_inputs, num_hiddens, num_outputs = vocab_size, 256, vocab_size
print('will use', device)
def get_params():
def _one(shape):
ts = torch.tensor(np.random.normal(0, 0.01, size=shape), device=device, dtype=torch.float32)
return torch.nn.Parameter(ts, requires_grad=True)
def _three():
return (_one((num_inputs, num_hiddens)),
_one((num_hiddens, num_hiddens)),
torch.nn.Parameter(torch.zeros(num_hiddens, device=device, dtype=torch.float32), requires_grad=True))
W_xi, W_hi, b_i = _three() # 输入门参数
W_xf, W_hf, b_f = _three() # 遗忘门参数
W_xo, W_ho, b_o = _three() # 输出门参数
W_xc, W_hc, b_c = _three() # 候选记忆细胞参数
# 输出层参数
W_hq = _one((num_hiddens, num_outputs))
b_q = torch.nn.Parameter(torch.zeros(num_outputs, device=device, dtype=torch.float32), requires_grad=True)
return nn.ParameterList([W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q])
def init_lstm_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device),
torch.zeros((batch_size, num_hiddens), device=device))
//will use cpu
LSTM模型
def lstm(inputs, state, params):
[W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q] = params
(H, C) = state
outputs = []
for X in inputs:
I = torch.sigmoid(torch.matmul(X, W_xi) + torch.matmul(H, W_hi) + b_i)
F = torch.sigmoid(torch.matmul(X, W_xf) + torch.matmul(H, W_hf) + b_f)
O = torch.sigmoid(torch.matmul(X, W_xo) + torch.matmul(H, W_ho) + b_o)
C_tilda = torch.tanh(torch.matmul(X, W_xc) + torch.matmul(H, W_hc) + b_c)
C = F * C + I * C_tilda
H = O * C.tanh()
Y = torch.matmul(H, W_hq) + b_q
outputs.append(Y)
return outputs, (H, C)
###训练模型
In [12]:
num_epochs, num_steps, batch_size, lr, clipping_theta = 160, 35, 32, 1e2, 1e-2
pred_period, pred_len, prefixes = 40, 50, ['分开', '不分开']
d2l.train_and_predict_rnn(lstm, get_params, init_lstm_state, num_hiddens,
vocab_size, device, corpus_indices, idx_to_char,
char_to_idx, False, num_epochs, num_steps, lr,
clipping_theta, batch_size, pred_period, pred_len,
prefixes)
简洁实现
num_hiddens=256
num_epochs, num_steps, batch_size, lr, clipping_theta = 160, 35, 32, 1e2, 1e-2
pred_period, pred_len, prefixes = 40, 50, ['分开', '不分开']
lr = 1e-2 # 注意调整学习率
lstm_layer = nn.LSTM(input_size=vocab_size, hidden_size=num_hiddens)
model = d2l.RNNModel(lstm_layer, vocab_size)
d2l.train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes)
3.深度循环神经网络
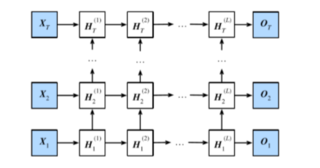
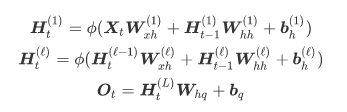
num_hiddens=256
num_epochs, num_steps, batch_size, lr, clipping_theta = 160, 35, 32, 1e2, 1e-2
pred_period, pred_len, prefixes = 40, 50, ['分开', '不分开']
lr = 1e-2 # 注意调整学习率
gru_layer = nn.LSTM(input_size=vocab_size, hidden_size=num_hiddens,num_layers=2)
model = d2l.RNNModel(gru_layer, vocab_size).to(device)
d2l.train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes)
gru_layer = nn.LSTM(input_size=vocab_size, hidden_size=num_hiddens,num_layers=6)
model = d2l.RNNModel(gru_layer, vocab_size).to(device)
d2l.train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes)
4.双向循环神经网络
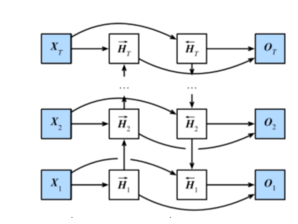
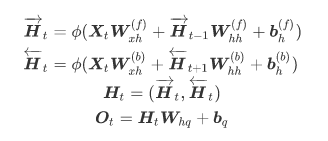
num_hiddens=128
num_epochs, num_steps, batch_size, lr, clipping_theta = 160, 35, 32, 1e-2, 1e-2
pred_period, pred_len, prefixes = 40, 50, ['分开', '不分开']
lr = 1e-2 # 注意调整学习率
gru_layer = nn.GRU(input_size=vocab_size, hidden_size=num_hiddens,bidirectional=True)
model = d2l.RNNModel(gru_layer, vocab_size).to(device)
d2l.train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes)
作者:skymacro
相关文章
Heidi
2020-03-04
Connie
2020-01-15
Cynthia
2020-09-01
Tia
2023-04-20
Kara
2023-04-22
Fawn
2023-05-12
Crystal
2023-05-12
Adelaide
2023-05-13
Tani
2023-05-27
Tanisha
2023-05-27
Kande
2023-05-27
Tricia
2023-05-27
Ida
2023-07-20
Irma
2023-07-20
Xylona
2023-07-20
Samira
2023-07-20
Radinka
2023-07-20