动手学深度学习 Task03 过拟合、欠拟合及其解决方案;梯度消失、梯度爆炸;循环神经网络进阶
【一】过拟合、欠拟合及其解决方案
过拟合模型的训练误差远小于它在测试数据集上的误差,我们称该现象为过拟合(overfitting)。 欠拟合
当模型无法得到较低的训练误差时,我们将这一现象称作欠拟合(underfitting)。 在实践中,我们要尽可能同时应对欠拟合和过拟合。虽然有很多因素可能导致这两种拟合问题,在这里重点讨论两个因素: 模型复杂度和训练数据集大小。
1.模型复杂度
为了解释模型复杂度,我们以多项式函数拟合为例。给定一个由标量数据特征 x 和对应的标量标签 y 组成的训练数据集,多项式函数拟合的目标是找一个 K 阶多项式函数y^=b+∑k=1Kxkwk\hat{y} = b + \sum_{k=1}^K x^k w_ky^=b+k=1∑Kxkwk来近似 y 。在上式中, wkw_kwk 是模型的权重参数, b 是偏差参数。与线性回归相同,多项式函数拟合也使用平方损失函数。特别地,一阶多项式函数拟合又叫线性函数拟合。
给定训练数据集,模型复杂度和误差之间的关系:

2.训练数据集大小
影响欠拟合和过拟合的另一个重要因素是训练数据集的大小。一般来说,如果训练数据集中样本数过少,特别是比模型参数数量(按元素计)更少时,过拟合更容易发生。此外,泛化误差不会随训练数据集里样本数量增加而增大。因此,在计算资源允许的范围之内,我们通常希望训练数据集大一些,特别是在模型复杂度较高时,例如层数较多的深度学习模型。
线性函数拟合(欠拟合)
fit_and_plot(features[:n_train, :], features[n_train:, :], labels[:n_train], labels[n_train:])
final epoch: train loss 781.689453125 test loss 329.79852294921875
weight: tensor([[26.8753]])
bias: tensor([6.1426])
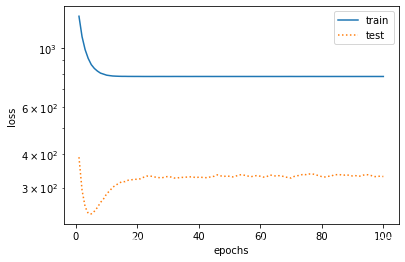
训练样本不足(过拟合)
fit_and_plot(poly_features[0:2, :], poly_features[n_train:, :], labels[0:2], labels[n_train:])
final epoch: train loss 6.23520565032959 test loss 409.9844665527344
weight: tensor([[ 0.9729, -0.9612, 0.7259]])
bias: tensor([1.6334])
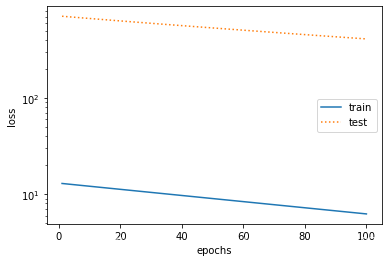
权重衰减
权重衰减等价于 L2L_2L2 范数正则化(regularization)。正则化通过为模型损失函数添加惩罚项使学出的模型参数值较小,是应对过拟合的常用手段。 范数正则化L2 (regularization)
L2L_2L2 范数正则化在模型原损失函数基础上添加 L2 范数惩罚项,从而得到训练所需要最小化的函数。 L2L_2L2范数惩罚项指的是模型权重参数每个元素的平方和与一个正的常数的乘积。以线性回归中的线性回归损失函数为例ℓ(w1,w2,b)=1n∑i=1n12(x1(i)w1+x2(i)w2+b−y(i))2\ell(w_1, w_2, b) = \frac{1}{n} \sum_{i=1}^n \frac{1}{2}\left(x_1^{(i)} w_1 + x_2^{(i)} w_2 + b - y^{(i)}\right)^2ℓ(w1,w2,b)=n1i=1∑n21(x1(i)w1+x2(i)w2+b−y(i))2其中w1,w2w_1,w_2w1,w2 是权重参数, b 是偏差参数,样本 i 的输入为 x1(i),x2(i)x_1^{(i)}, x_2^{(i)}x1(i),x2(i) ,标签为y(i)y^{(i)}y(i) ,样本数为 n 。将权重参数用向量 w=[w1,w2w_1, w_2w1,w2] 表示,带有 L2L_2L2范数惩罚项的新损失函数为ℓ(w1,w2,b)+λ2n∣w∣2,\ell(w_1, w_2, b) + \frac{\lambda}{2n} |\boldsymbol{w}|^2,ℓ(w1,w2,b)+2nλ∣w∣2,其中超参数 λ>0 。当权重参数均为0时,惩罚项最小。当 λ 较大时,惩罚项在损失函数中的比重较大,这通常会使学到的权重参数的元素较接近0。当 λ 设为0时,惩罚项完全不起作用。上式中 L2L_2L2 范数平方∣w∣2|\boldsymbol{w}|^2∣w∣2 展开后得到 w12+w22w_1^2 + w_2^2w12+w22 。 有了 L2L_2L2 范数惩罚项后,在小批量随机梯度下降中,我们将线性回归一节中权重 w1w_1w1和w2w_2w2 的迭代方式更改为
w1←(1−ηλ∣B∣)w1−η∣B∣∑i∈Bx1(i)(x1(i)w1+x2(i)w2+b−y(i)),w2←(1−ηλ∣B∣)w2−η∣B∣∑i∈Bx2(i)(x1(i)w1+x2(i)w2+b−y(i)).\begin{aligned} w_1 &\leftarrow \left(1- \frac{\eta\lambda}{|\mathcal{B}|} \right)w_1 - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}}x_1^{(i)} \left(x_1^{(i)} w_1 + x_2^{(i)} w_2 + b - y^{(i)}\right),\\ w_2 &\leftarrow \left(1- \frac{\eta\lambda}{|\mathcal{B}|} \right)w_2 - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}}x_2^{(i)} \left(x_1^{(i)} w_1 + x_2^{(i)} w_2 + b - y^{(i)}\right). \end{aligned}w1w2←(1−∣B∣ηλ)w1−∣B∣ηi∈B∑x1(i)(x1(i)w1+x2(i)w2+b−y(i)),←(1−∣B∣ηλ)w2−∣B∣ηi∈B∑x2(i)(x1(i)w1+x2(i)w2+b−y(i)).可见, L2L_2L2范数正则化令权重 w1w_1w1和w2w_2w2 先自乘小于1的数,再减去不含惩罚项的梯度。因此,L2L_2L2范数正则化又叫权重衰减。权重衰减通过惩罚绝对值较大的模型参数为需要学习的模型增加了限制,这可能对过拟合有效。 高维线性回归实验从零开始的实现
下面,我们以高维线性回归为例来引入一个过拟合问题,并使用权重衰减来应对过拟合。设数据样本特征的维度为 p 。对于训练数据集和测试数据集中特征为 x1,x2,…,xpx_1, x_2, \ldots, x_px1,x2,…,xp的任一样本,我们使用如下的线性函数来生成该样本的标签:y=0.05+∑i=1p0.01xi+ϵy = 0.05 + \sum_{i = 1}^p 0.01x_i + \epsilony=0.05+i=1∑p0.01xi+ϵ 其中噪声项 ϵ 服从均值为0、标准差为0.01的正态分布。为了较容易地观察过拟合,我们考虑高维线性回归问题,如设维度 p=200 ;同时,我们特意把训练数据集的样本数设低,如20。
%matplotlib inline
import torch
import torch.nn as nn
import numpy as np
import sys
sys.path.append("/home/kesci/input")
import d2lzh1981 as d2l
print(torch.__version__)
初始化模型参数
n_train, n_test, num_inputs = 20, 100, 200
true_w, true_b = torch.ones(num_inputs, 1) * 0.01, 0.05
features = torch.randn((n_train + n_test, num_inputs))
labels = torch.matmul(features, true_w) + true_b
labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()), dtype=torch.float)
train_features, test_features = features[:n_train, :], features[n_train:, :]
train_labels, test_labels = labels[:n_train], labels[n_train:]
# 定义参数初始化函数,初始化模型参数并且附上梯度
def init_params():
w = torch.randn((num_inputs, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
return [w, b]
定义L2范数惩罚项
ef l2_penalty(w):
return (w**2).sum() / 2
定义训练和测试
atch_size, num_epochs, lr = 1, 100, 0.003
net, loss = d2l.linreg, d2l.squared_loss
dataset = torch.utils.data.TensorDataset(train_features, train_labels)
train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True)
def fit_and_plot(lambd):
w, b = init_params()
train_ls, test_ls = [], []
for _ in range(num_epochs):
for X, y in train_iter:
# 添加了L2范数惩罚项
l = loss(net(X, w, b), y) + lambd * l2_penalty(w)
l = l.sum()
if w.grad is not None:
w.grad.data.zero_()
b.grad.data.zero_()
l.backward()
d2l.sgd([w, b], lr, batch_size)
train_ls.append(loss(net(train_features, w, b), train_labels).mean().item())
test_ls.append(loss(net(test_features, w, b), test_labels).mean().item())
d2l.semilogy(range(1, num_epochs + 1), train_ls, 'epochs', 'loss',
range(1, num_epochs + 1), test_ls, ['train', 'test'])
print('L2 norm of w:', w.norm().item())
观察过拟合
fit_and_plot(lambd=0)
L2 norm of w: 11.6444091796875
使用权重衰减
fit_and_plot(lambd=3)
L2 norm of w: 0.04063604772090912
丢弃法
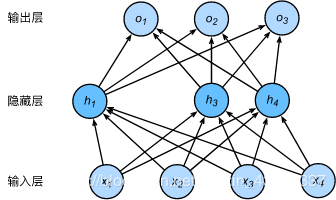
多层感知机中神经网络图描述了一个单隐藏层的多层感知机。其中输入个数为4,隐藏单元个数为5,且隐藏单元hih_ihi( i=1,…,5 )的计算表达式为hi=ϕ(x1w1i+x2w2i+x3w3i+x4w4i+bi)h_i = \phi\left(x_1 w_{1i} + x_2 w_{2i} + x_3 w_{3i} + x_4 w_{4i} + b_i\right)hi=ϕ(x1w1i+x2w2i+x3w3i+x4w4i+bi)这里 ϕ 是激活函数, x1,…,x4 是输入,隐藏单元 i 的权重参数为 w1i,…,w4iw_{1i}, \ldots, w_{4i}w1i,…,w4i,偏差参数为bib_ibi 。当对该隐藏层使用丢弃法时,该层的隐藏单元将有一定概率被丢弃掉。设丢弃概率为 p ,那么有 p 的概率 hih_ihi会被清零,有 1−p 的概率hih_ihi会除以 1−p 做拉伸。丢弃概率是丢弃法的超参数。具体来说,设随机变量ξi\xi_iξi为0和1的概率分别为 p 和 1−p 。使用丢弃法时我们计算新的隐藏单元hi′h_i'hi′
hi′=ξi1−phih_i' = \frac{\xi_i}{1-p} h_ihi′=1−pξihi由于 E(ξi)=1−pE(\xi_i) = 1-pE(ξi)=1−p ,因此E(hi′)=E(ξi)1−phi=hiE(h_i') = \frac{E(\xi_i)}{1-p}h_i = h_iE(hi′)=1−pE(ξi)hi=hi即丢弃法不改变其输入的期望值。让我们对之前多层感知机的神经网络中的隐藏层使用丢弃法,一种可能的结果如图所示,其中h2h_2h2 和h5h_5h5被清零。这时输出值的计算不再依赖h2h_2h2 和h5h_5h5 ,在反向传播时,与这两个隐藏单元相关的权重的梯度均为0。由于在训练中隐藏层神经元的丢弃是随机的,即 h1,…,h5h_1, \ldots, h_5h1,…,h5都有可能被清零,输出层的计算无法过度依赖 h1,…,h5h_1, \ldots, h_5h1,…,h5中的任一个,从而在训练模型时起到正则化的作用,并可以用来应对过拟合。在测试模型时,我们为了拿到更加确定性的结果,一般不使用丢弃法
总结
欠拟合现象:模型无法达到一个较低的误差
过拟合现象:训练误差较低但是泛化误差依然较高,二者相差较大
∗注:发生欠拟合的时候在训练集上训练误差不能达到一个比较低的水平,所以过拟合和欠拟合不可能同时发生。*注:发生欠拟合的时候在训练集上训练误差不能达到一个比较低的水平,所以过拟合和欠拟合不可能同时发生。∗注:发生欠拟合的时候在训练集上训练误差不能达到一个比较低的水平,所以过拟合和欠拟合不可能同时发生。
【二】梯度消失、梯度爆炸
∗深度模型有关数值稳定性的典型问题是消失(vanishing)和爆炸(explosion)。*深度模型有关数值稳定性的典型问题是消失(vanishing)和爆炸(explosion)。∗深度模型有关数值稳定性的典型问题是消失(vanishing)和爆炸(explosion)。
当神经网络的层数较多时,模型的数值稳定性容易变差。
假设一个层数为 L 的多层感知机的第 l 层 H(l)\boldsymbol{H}^{(l)}H(l) 的权重参数为 W(l)\boldsymbol{W}^{(l)}W(l) ,输出层H(l)\boldsymbol{H}^{(l)}H(l) 的权重参数为W(l)\boldsymbol{W}^{(l)}W(l) 。为了便于讨论,不考虑偏差参数,且设所有隐藏层的激活函数为恒等映射(identity mapping) ϕ(x)=x 。给定输入 X ,多层感知机的第 l 层的输出 H(l)=XW(1)W(2)…W(l)\boldsymbol{H}^{(l)} = \boldsymbol{X} \boldsymbol{W}^{(1)} \boldsymbol{W}^{(2)} \ldots \boldsymbol{W}^{(l)}H(l)=XW(1)W(2)…W(l)。此时,如果层数 l 较大, H(l) 的计算可能会出现衰减或爆炸。举个例子,假设输入和所有层的权重参数都是标量,如权重参数为0.2和5,多层感知机的第30层输出为输入 X 分别与 0.230≈1×10−210.2^{30} \approx 1 \times 10^{-21}0.230≈1×10−21 (消失)和 530≈9×10205^{30} \approx 9 \times 10^{20}530≈9×1020(爆炸)的乘积。当层数较多时,梯度的计算也容易出现消失或爆炸。
考虑环境因素
这里假设,虽然输入的分布可能随时间而改变,但是标记函数,即条件分布P(y∣x)不会改变。虽然这个问题容易理解,但在实践中也容易忽视。
统计学家称这种协变量变化是因为问题的根源在于特征分布的变化(即协变量的变化)。数学上,我们可以说P(x)改变了,但P(y∣x)保持不变。尽管它的有用性并不局限于此,当我们认为x导致y时,协变量移位通常是正确的假设。 标签偏移
当我们认为导致偏移的是标签P(y)上的边缘分布的变化,但类条件分布是不变的P(x∣y)时,就会出现相反的问题。当我们认为y导致x时,标签偏移是一个合理的假设。标签偏移可以简单理解为测试时出现了训练时没有的标签 概念偏移
另一个相关的问题出现在概念转换中,即标签本身的定义发生变化的情况。这听起来很奇怪,毕竟猫就是猫。的确,猫的定义可能不会改变,但我们能不能对软饮料也这么说呢?事实证明,如果我们周游美国,按地理位置转移数据来源,我们会发现,即使是如图所示的这个简单术语的定义也会发生相当大的概念转变。
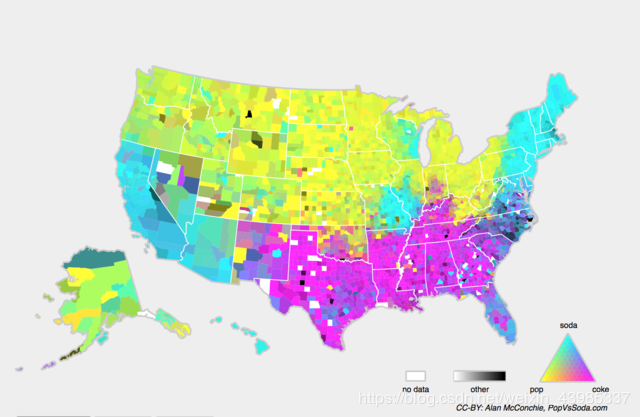
如果我们要建立一个机器翻译系统,分布P(y∣x)可能因我们的位置而异。这个问题很难发现。另一个可取之处是P(y∣x)通常只是逐渐变化。
【三】循环神经网络进阶
GRU
RNN存在的问题:梯度较容易出现衰减或爆炸(BPTT)
⻔控循环神经⽹络:捕捉时间序列中时间步距离较⼤的依赖关系
RNN:
GRU:
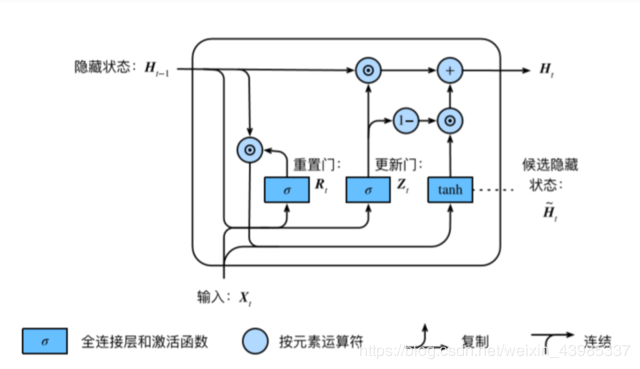 Rt=σ(XtWxr+Ht−1Whr+br)Zt=σ(XtWxz+Ht−1Whz+bz)H~t=tanh(XtWxh+(Rt⊙Ht−1)Whh+bh)Ht=Zt⊙Ht−1+(1−Zt)⊙H~tR_{t} = σ(X_tW_{xr} + H_{t−1}W_{hr} + b_r)\\
Z_{t} = σ(X_tW_{xz} + H_{t−1}W_{hz} + b_z)\\
\widetilde{H}_t = tanh(X_tW_{xh} + (R_t ⊙H_{t−1})W_{hh} + b_h)\\
H_t = Z_t⊙H_{t−1} + (1−Z_t)⊙\widetilde{H}_tRt=σ(XtWxr+Ht−1Whr+br)Zt=σ(XtWxz+Ht−1Whz+bz)Ht=tanh(XtWxh+(Rt⊙Ht−1)Whh+bh)Ht=Zt⊙Ht−1+(1−Zt)⊙Ht• 重置⻔有助于捕捉时间序列⾥短期的依赖关系;
Rt=σ(XtWxr+Ht−1Whr+br)Zt=σ(XtWxz+Ht−1Whz+bz)H~t=tanh(XtWxh+(Rt⊙Ht−1)Whh+bh)Ht=Zt⊙Ht−1+(1−Zt)⊙H~tR_{t} = σ(X_tW_{xr} + H_{t−1}W_{hr} + b_r)\\
Z_{t} = σ(X_tW_{xz} + H_{t−1}W_{hz} + b_z)\\
\widetilde{H}_t = tanh(X_tW_{xh} + (R_t ⊙H_{t−1})W_{hh} + b_h)\\
H_t = Z_t⊙H_{t−1} + (1−Z_t)⊙\widetilde{H}_tRt=σ(XtWxr+Ht−1Whr+br)Zt=σ(XtWxz+Ht−1Whz+bz)Ht=tanh(XtWxh+(Rt⊙Ht−1)Whh+bh)Ht=Zt⊙Ht−1+(1−Zt)⊙Ht• 重置⻔有助于捕捉时间序列⾥短期的依赖关系;
• 更新⻔有助于捕捉时间序列⾥⻓期的依赖关系。
载入数据集
import os
os.listdir('/home/kesci/input')
['d2lzh1981', 'houseprices2807', 'jaychou_lyrics4703', 'd2l_jay9460']
import numpy as np
import torch
from torch import nn, optim
import torch.nn.functional as F
import sys
sys.path.append("../input/")
import d2l_jay9460 as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
(corpus_indices, char_to_idx, idx_to_char, vocab_size) = d2l.load_data_jay_lyrics()
初始化参数
num_inputs, num_hiddens, num_outputs = vocab_size, 256, vocab_size
print('will use', device)
def get_params():
def _one(shape):
ts = torch.tensor(np.random.normal(0, 0.01, size=shape), device=device, dtype=torch.float32) #正态分布
return torch.nn.Parameter(ts, requires_grad=True)
def _three():
return (_one((num_inputs, num_hiddens)),
_one((num_hiddens, num_hiddens)),
torch.nn.Parameter(torch.zeros(num_hiddens, device=device, dtype=torch.float32), requires_grad=True))
W_xz, W_hz, b_z = _three() # 更新门参数
W_xr, W_hr, b_r = _three() # 重置门参数
W_xh, W_hh, b_h = _three() # 候选隐藏状态参数
# 输出层参数
W_hq = _one((num_hiddens, num_outputs))
b_q = torch.nn.Parameter(torch.zeros(num_outputs, device=device, dtype=torch.float32), requires_grad=True)
return nn.ParameterList([W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q])
def init_gru_state(batch_size, num_hiddens, device): #隐藏状态初始化
return (torch.zeros((batch_size, num_hiddens), device=device), )
GRU模型
def gru(inputs, state, params):
W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
for X in inputs:
Z = torch.sigmoid(torch.matmul(X, W_xz) + torch.matmul(H, W_hz) + b_z)
R = torch.sigmoid(torch.matmul(X, W_xr) + torch.matmul(H, W_hr) + b_r)
H_tilda = torch.tanh(torch.matmul(X, W_xh) + R * torch.matmul(H, W_hh) + b_h)
H = Z * H + (1 - Z) * H_tilda
Y = torch.matmul(H, W_hq) + b_q
outputs.append(Y)
return outputs, (H,)
训练模型
num_epochs, num_steps, batch_size, lr, clipping_theta = 160, 35, 32, 1e2, 1e-2
pred_period, pred_len, prefixes = 40, 50, ['分开', '不分开']
d2l.train_and_predict_rnn(gru, get_params, init_gru_state, num_hiddens,
vocab_size, device, corpus_indices, idx_to_char,
char_to_idx, False, num_epochs, num_steps, lr,
clipping_theta, batch_size, pred_period, pred_len,
prefixes)
作者:周周儿_zHoU