深度学习(三)————过拟合、欠拟合及其解决方案;梯度消失、梯度爆炸;循环神经网络进阶
目录
过拟合、欠拟合及其解决方案
训练误差和泛化误差
过拟合和欠拟合的概念
模型复杂度和误差之间的关系
解决过拟合的方案
梯度消失及梯度爆炸
循环神经网络进阶
GRU
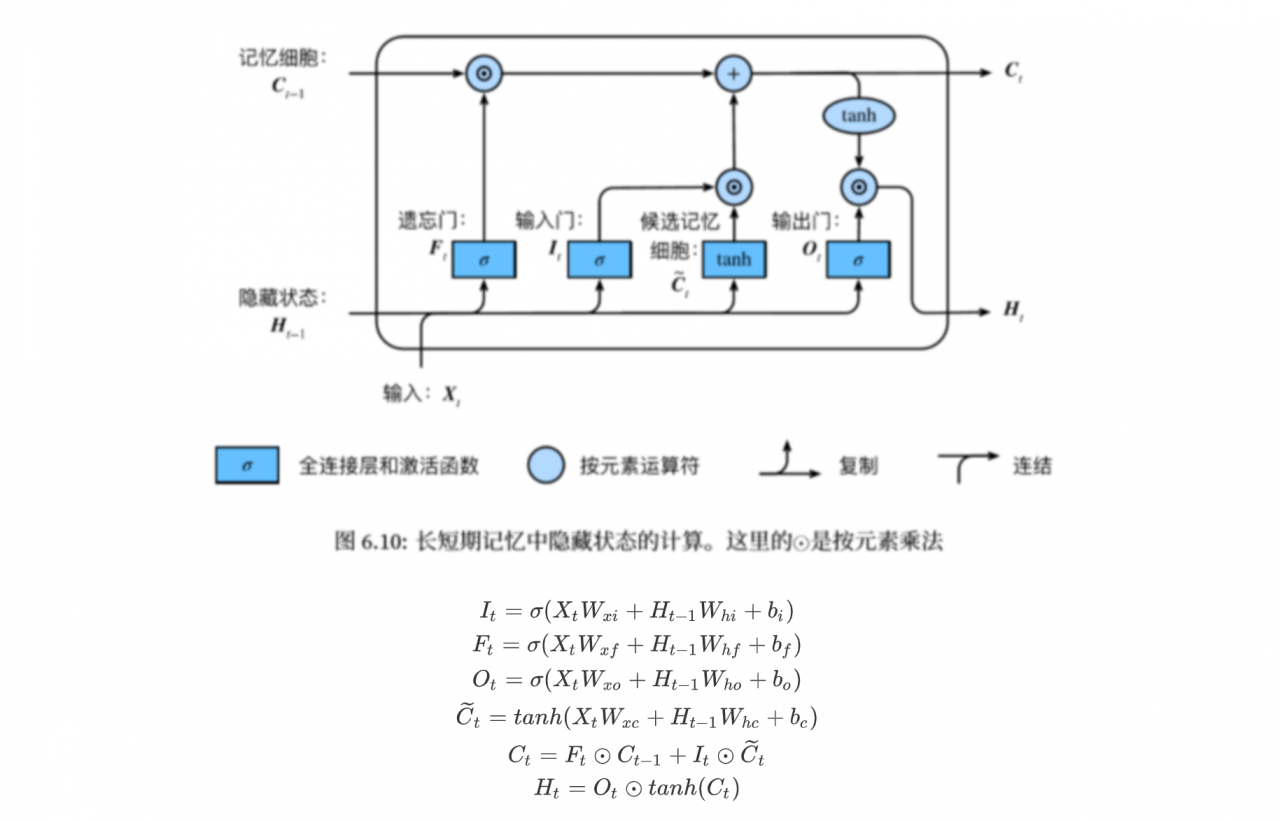
LSTM
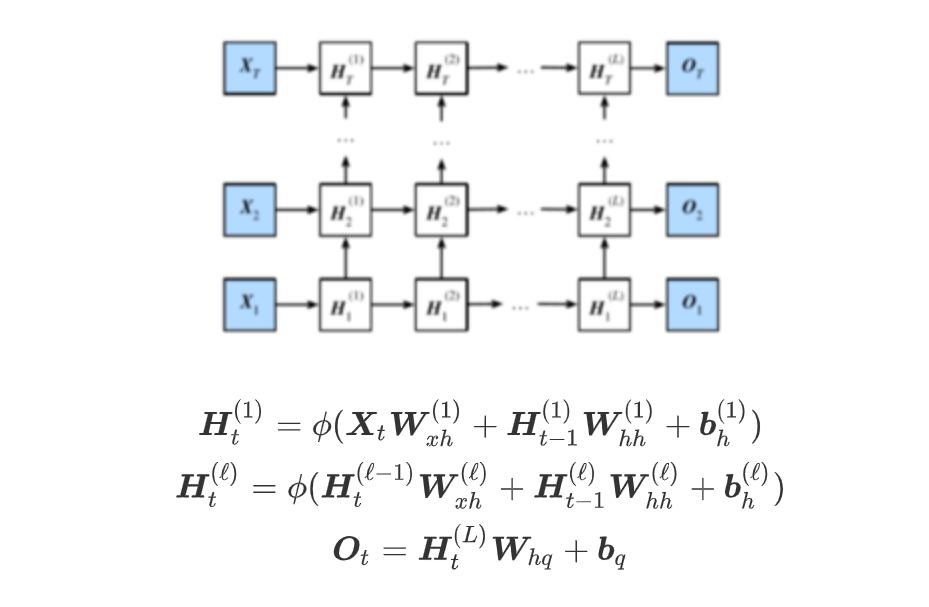
深度神经网络
过拟合、欠拟合及其解决方案 训练误差和泛化误差在解释上述现象之前,我们需要区分训练误差(training error)和泛化误差(generalization error)。通俗来讲,前者指模型在训练数据集上表现出的误差,后者指模型在任意一个测试数据样本上表现出的误差的期望,并常常通过测试数据集上的误差来近似。计算训练误差和泛化误差可以使用之前介绍过的损失函数,例如线性回归用到的平方损失函数和softmax回归用到的交叉熵损失函数。
机器学习模型应关注降低泛化误差。
过拟合和欠拟合的概念 一类是模型无法得到较低的训练误差,我们将这一现象称作欠拟合(underfitting); 另一类是模型的训练误差远小于它在测试数据集上的误差,我们称该现象为过拟合(overfitting)。 在实践中,我们要尽可能同时应对欠拟合和过拟合。虽然有很多因素可能导致这两种拟合问题,在这里我们重点讨论两个因素:模型复杂度和训练数据集大小 模型复杂度和误差之间的关系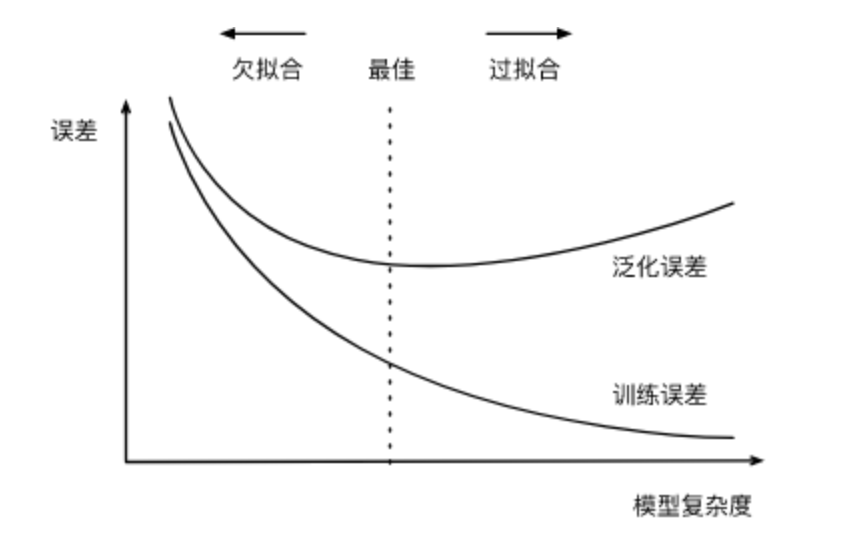
权重衰减(又称L2范式正则化)
权重衰减等价于 L2 范数正则化(regularization)。正则化通过为模型损失函数添加惩罚项使学出的模型参数值较小,是应对过拟合的常用手段。
丢弃法
梯度消失及梯度爆炸里面有详细说明https://blog.csdn.net/u011734144/article/details/80165007
几种解决方法
1、对于RNN,可以通过梯度截断,避免梯度爆炸
2、可以通过添加正则项,避免梯度爆炸
3、使用LSTM等自循环和门控制机制,避免梯度消失,参考:https://www.cnblogs.com/pinking/p/9362966.html
4、优化激活函数,譬如将sigmold改为relu,避免梯度消失
循环神经网络进阶 GRU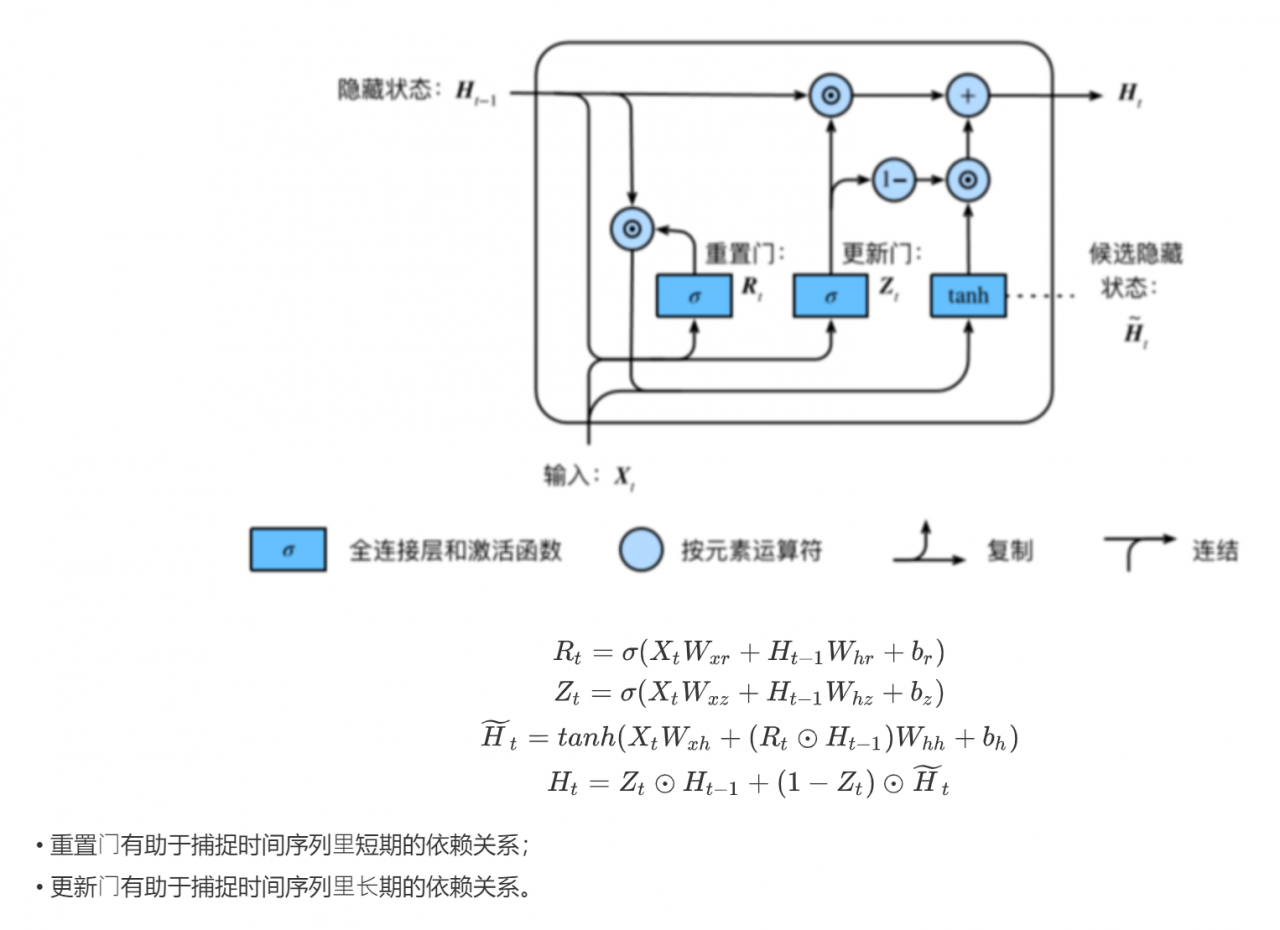

作者:渣渣菜