Task02:文本预处理;语言模型;循环神经网络基础
摘要:自然语言处理NLP(Natural Language Processing),顾名思义,就是使用计算机对语言文字进行处理的相关技术。在对文本做分析时,我们一大半的时间都会花在文本预处理上,而中文和英文的预处理流程稍有不同。
文本是一类序列数据,一篇文章可以看作是字符或单词的序列,本节将介绍文本数据的常见预处理步骤,预处理通常包括四个步骤:
1. 读入文本
2. 分词
3. 建立字典,将每个词映射到一个唯一的索引(index)
4. 将文本从词的序列转换为索引的序列,方便输入模型
用一部英文小说,即H. G. Well的Time Machine,作为示例,展示文本预处理的具体过程。
import collections
import re
def read_time_machine():
with open('/home/kesci/input/timemachine7163/timemachine.txt', 'r') as f:
# strip()去掉前后的空白字符,lower()将字符全部转换为小写
# sub()为正则表达式的替换函数,正则表达式为非小写英文字符构成的子串,被替换成空格
lines = [re.sub('[^a-z]+', ' ', line.strip().lower()) for line in f]
return lines
lines = read_time_machine()
print('# sentences %d' % len(lines)) #输出此文件的行数
# print(lines)
# sentences 3221
1.2 分词
接下来对每个句子进行分词,也就是把一个句子划分成若干个词(token),转换为一个词的序列
#定义用于分词的函数: sentences(列表)句子字符串,token为分词的级别
def tokenize(sentences, token='word'):
"""Split sentences into word or char tokens"""
if token == 'word':
#以句子中的空格符作为分割符
#二维列表,第一维是句子,第二维表示句子的单词序列
return [sentence.split(' ') for sentence in sentences]
elif token == 'char':
#字符级别的分词,直接转换为列表
#二维列表的第一维表示句子,第二维表示句子的字符序列
return [list(sentence) for sentence in sentences]
else:
print('ERROR: unkown token type '+token)
tokens = tokenize(lines)
tokens[0:2]
#[['the', 'time', 'machine', 'by', 'h', 'g', 'wells', ''], ['']]
1.3 建立字典
为了方便模型处理,我们需要将字符串转换为数字。因此我们需要先构建一个字典(vocabulary),将每个词映射到一个唯一的索引编号。
#定义一个类,功能是给这个对象的词都分配一个唯一的索引编号
class Vocab(object):
'''构造函数:tokens: 即前面处理得到的二维单词列表(即单词全集)
min_freq: 阈值,用于消除出现次数较少的词
use_special_tokens:标志是否使用特殊的tokens
'''
'''基本步骤:1、去重;
2、去除不需要的词
3、添加特殊的tokens(根据需求而定)
4、进行索引和token的映射
'''
def __init__(self, tokens, min_freq=0, use_special_tokens=False):
#去重以及统计词频
counter = count_corpus(tokens) # 字典:记录每个单词的词频
self.token_freqs = list(counter.items()) # 将字典转换为列表
self.idx_to_token = [] # 初始化 单词的索引
#添加特殊tokens
if use_special_tokens:
# padding, begin of sentence, end of sentence, unknown
# 为特殊tokens创建索引
self.pad, self.bos, self.eos, self.unk = (0, 1, 2, 3)
self.idx_to_token += ['', '', '', '']
'''
:用于填充训练时的二维矩阵
:用于表示一个特殊句子的开始和结束
:用于替换未登录词(即未在语料库出现的词语)
'''
else:
self.unk = 0
self.idx_to_token += ['']
#枚举语料库的每个词以及词频,如果不小于阈值且未定义则添加到映射列表(列表下标即为索引)
#构建index到token的映射
self.idx_to_token += [token for token, freq in self.token_freqs
if freq >= min_freq and token not in self.idx_to_token]
#构建词到index的映射字典
self.token_to_idx = dict()
for idx, token in enumerate(self.idx_to_token):
self.token_to_idx[token] = idx
#返回字典的大小
def __len__(self):
return len(self.idx_to_token)
#获取tokens的index,tokens可以是列表,元组,字典
def __getitem__(self, tokens):
#如果是字典,则返回映射字典中的值(映射字典没有的话返回)
if not isinstance(tokens, (list, tuple)):
return self.token_to_idx.get(tokens, self.unk)
#对列表和元组进行遍历,转换之后,返回一个列表或者元组
return [self.__getitem__(token) for token in tokens]
#获取index的token
def to_tokens(self, indices):
if not isinstance(indices, (list, tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[index] for index in indices]
def count_corpus(sentences):
tokens = [tk for st in sentences for tk in st] #将二维列表展平为一维
return collections.Counter(tokens) # 使用Counter返回一个字典,记录每个词的出现次数
例子:这里我们尝试用Time Machine作为语料构建字典
vocab = Vocab(tokens)
print(list(vocab.token_to_idx.items())[0:10])
# [('', 0), ('the', 1), ('time', 2), ('machine', 3), ('by', 4), ('h', 5), ('g', 6), ('wells', 7), ('', 8), ('i', 9)]
1.4 将词转为索引
使用字典,我们可以将原文本中的句子从单词序列转换为索引序列
for i in range(8, 10):
print('words:', tokens[i])
print('indices:', vocab[tokens[i]])
'''
words: ['the', 'time', 'traveller', 'for', 'so', 'it', 'will', 'be', 'convenient', 'to', 'speak', 'of', 'him', '']
indices: [1, 2, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 0]
words: ['was', 'expounding', 'a', 'recondite', 'matter', 'to', 'us', 'his', 'grey', 'eyes', 'shone', 'and']
indices: [20, 21, 22, 23, 24, 16, 25, 26, 27, 28, 29, 30]
'''
1.5 用现有工具进行分词
我们前面介绍的分词方式非常简单,它至少有以下几个缺点:
标点符号通常可以提供语义信息,但是我们的方法直接将其丢弃了
类似“shouldn't", "doesn't"这样的词会被错误地处理
类似"Mr.", "Dr."这样的词会被错误地处理
我们可以通过引入更复杂的规则来解决这些问题,但是事实上,有一些现有的工具可以很好地进行分词,我们在这里简单介绍其中的两个:spaCy和NLTK。
下面是一个简单的例子:
text = "Mr. Chen doesn't agree with my suggestion."
spaCy:
import spacy
nlp = spacy.load('en_core_web_sm')
doc = nlp(text)
print([token.text for token in doc])
# ['Mr.', 'Chen', 'does', "n't", 'agree', 'with', 'my', 'suggestion', '.']
NLTK:
from nltk.tokenize import word_tokenize
from nltk import data
print(word_tokenize(text))
# ['Mr.', 'Chen', 'does', "n't", 'agree', 'with', 'my', 'suggestion', '.']
2、语言模型
2.1 定义
语言模型本质上是在回答一个问题:出现的语句是否合理。
在历史的发展中,语言模型经历了专家语法规则模型(至80年代),统计语言模型(至00年),神经网络语言模型(到目前)。
专家语法规则模型
在计算机初始阶段,随着计算机编程语言的发展,归纳出的针对自然语言的语法规则。但是自然语言本身的多样性、口语化,在时间、空间上的演化,及人本身强大的纠错能力,导致语法规则急剧膨胀,不可持续。
统计语言模型
统计语言模型就是计算一个句子的概率大小的这种模型。形式化讲,统计语言模型的作用是为一个长度为 m 的字符串确定一个概率分布 P(w1; w2; :::; wm),表示其存在的可能性,其中 w1 到 wm 依次表示这段文本中的各个词。
自然语言处理中最常见的数据是文本数据。我们可以把一段自然语言文本看作一段离散的时间序列。假设一段长度为T的文本中的词依次为w1,w2,…,wT,那么在离散的时间序列中,wt(1≤t≤T)可看作在时间步(time step)t的输出或标签。给定一个长度为T的词的序列w1,w2,…,wT,语言模型将计算该序列的概率:
P(w1,w2,…,wT).
语言模型可用于提升语音识别和机器翻译的性能。例如,在语音识别中,给定一段“厨房里食油用完了”的语音,有可能会输出“厨房里食油用完了”和“厨房里石油用完了”这两个读音完全一样的文本序列。如果语言模型判断出前者的概率大于后者的概率,我们就可以根据相同读音的语音输出“厨房里食油用完了”的文本序列。在机器翻译中,如果对英文“you go first”逐词翻译成中文的话,可能得到“你走先”“你先走”等排列方式的文本序列。如果语言模型判断出“你先走”的概率大于其他排列方式的文本序列的概率,我们就可以把“you go first”翻译成“你先走”。
2.2 语言模型的计算
假设序列w1,w2,…,wT中的每个词是依次生成的,我们有
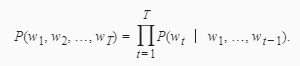
例如,一段含有4个词的文本序列的概率:
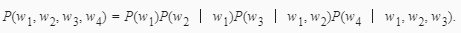
为了计算语言模型,我们需要计算词的概率,以及一个词在给定前几个词的情况下的条件概率,即语言模型参数。设训练数据集为一个大型文本语料库,如维基百科的所有条目。词的概率可以通过该词在训练数据集中的相对词频来计算。例如,P(w1)可以计算为w1在训练数据集中的词频(词出现的次数)与训练数据集的总词数之比。因此,根据条件概率定义,一个词在给定前几个词的情况下的条件概率也可以通过训练数据集中的相对词频计算。例如,P(w2∣w1)可以计算为w1,w2两词相邻的频率与w1词频的比值,因为该比值即P(w1,w2)与P(w1)之比;而P(w3∣w1,w2)同理可以计算为w1、w2和w3三词相邻的频率与w1和w2两词相邻的频率的比值。以此类推。
2.3 n元语法
序列长度增加,计算和存储多个词共同出现的概率的复杂度会呈指数级增加。n元语法通过马尔可夫假设简化模型,马尔科夫假设是指一个词的出现只与前面n个词相关,即n阶马尔可夫链(Markov chain of order n),如果n=1,那么有P(w3∣w1,w2)=P(w3∣w2)。基于n−1阶马尔可夫链,我们可以将语言模型改写为
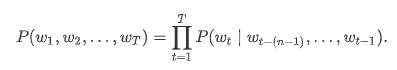
以上也叫n元语法(n-grams)。它是基于:math:n - 1阶马尔可夫链的概率语言模型。当n分别为1、2和3时,我们将其分别称作一元语法(unigram)、二元语法(bigram)和三元语法(trigram)。例如,长度为4的序列w1,w2,w3,w4在一元语法、二元语法和三元语法中的概率分别为
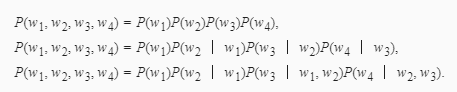
当n较小时,n元语法往往并不准确。例如,在一元语法中,由三个词组成的句子“你走先”和“你先走”的概率是一样的。然而,当n较大时,n元语法需要计算并存储大量的词频和多词相邻频率。
3、循环神经网络基础
n元语法中,时间步t的词wt基于前面所有词的条件概率只考虑了最近时间步的n−1个词。如果要考虑比t−(n−1)更早时间步的词对wt的可能影响,我们需要增大n。但这样模型参数的数量将随之呈指数级增长。
循环神经网络。它并非刚性地记忆所有固定长度的序列,而是通过隐藏状态来存储之前时间步的信息。
下图展示了如何基于循环神经网络实现语言模型。我们的目的是基于当前的输入与过去的输入序列,预测序列的下一个字符。循环神经网络引入一个隐藏变量H,用Ht表示H在时间步t的值。Ht的计算基于Xt和Ht−1,可以认为Ht记录了到当前字符为止的序列信息,利用Ht对序列的下一个字符进行预测。
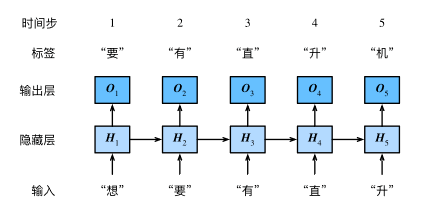
3.1 循环神经网络的构造
先看循环神经网络的具体构造。假设Xt∈Rn×d是时间步t的小批量输入,Ht∈Rn×h是该时间步的隐藏变量,则:
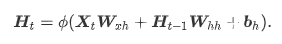
其中,Wxh∈Rd×h,Whh∈Rh×h,bh∈R1×h,ϕ函数是非线性激活函数。由于引入了Ht−1Whh,Ht能够捕捉截至当前时间步的序列的历史信息,就像是神经网络当前时间步的状态或记忆一样。由于Ht的计算基于Ht−1,上式的计算是循环的,使用循环计算的网络即循环神经网络(recurrent neural network)。
在时间步t,输出层的输出为:
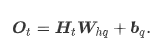
其中Whq∈Rh×q,bq∈R1×q。
参考资料:
http://zh.gluon.ai/chapter_recurrent-neural-networks/lang-model.html
https://www.boyuai.com/elites/course/cZu18YmweLv10OeV/jupyter/UMWZaZZQHRm8vhvwVKagt
https://www.cnblogs.com/dyl222/p/11005948.html
作者:莜莫oO