动手学 task03 过拟合、欠拟合及其解决方案+梯度消失、梯度爆炸+循环神经网络进阶
过拟合、欠拟合及其解决方案
过拟合和欠拟合
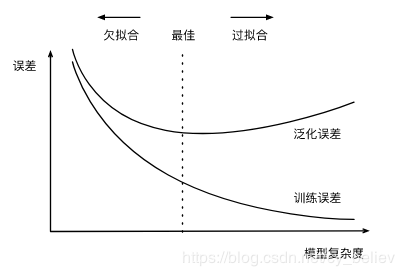
一类是模型无法得到较低的训练误差,我们将这一现象称作欠拟合(underfitting); 另一类是模型的训练误差远小于它在测试数据集上的误差,我们称该现象为过拟合(overfitting)。 在实践中,我们要尽可能同时应对欠拟合和过拟合。虽然有很多因素可能导致这两种拟合问题,在这里我们重点讨论两个因素:模型复杂度和训练数据集大小。模型复杂度与过拟合、欠拟合的关系如下图:
训练数据集大小:
影响欠拟合和过拟合的另一个重要因素是训练数据集的大小。一般来说,如果训练数据集中样本数过少,特别是比模型参数数量(按元素计)更少时,过拟合更容易发生。此外,泛化误差不会随训练数据集里样本数量增加而增大。因此,在计算资源允许的范围之内,我们通常希望训练数据集大一些,特别是在模型复杂度较高时,例如层数较多的深度学习模型。
权重衰减等价于