《动手学pytorch》Task:过拟合、欠拟合及其解决方案;梯度消失、梯度爆炸;循环神经网络
一、过拟合和欠拟合
训练误差和测试误差都大,欠拟合 underfitting。模型复杂度不够。
训练误差小于测试误差,过拟合 overfitting。

影响因素之一:训练数据集大小
影响欠拟合和过拟合的另一个重要因素是训练数据集的大小。一般来说,如果训练数据集中样本数过少,特别是比模型参数数量(按元素计)更少时,过拟合更容易发生。此外,泛化误差不会随训练数据集里样本数量增加而增大。因此,在计算资源允许的范围之内,我们通常希望训练数据集大一些,特别是在模型复杂度较高时,例如层数较多的深度学习模型。
过拟合解决方案
增加数据; 正则化; 减少特征维度,features; 优化超参数; 降低模型复杂度; 用Bagging方法欠拟合解决方案;
尝试更复杂模型,如二次函数拟合不够,用三次函数拟合; 用更多特征,features; 优化参数 用boosting方法L2正则化

**丢弃法:**训练用,测试一般不用

二、梯度消失、梯度爆炸

Xavier随机初始化

三、循环神经网络
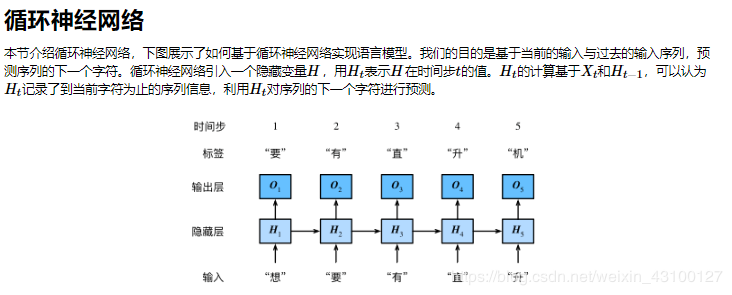

循环神经网络的简介实现
定义模型
我们使用Pytorch中的nn.RNN来构造循环神经网络。在本节中,我们主要关注nn.RNN的以下几个构造函数参数:
‘relu’. Default: ‘tanh’ batch_first – If True, then the input and output tensors are provided
as (batch_size, num_steps, input_size). Default: False
这里的batch_first决定了输入的形状,我们使用默认的参数False,对应的输入形状是 (num_steps, batch_size, input_size)。
forward函数的参数为:
input of shape (num_steps, batch_size, input_size): tensor containingthe features of the input sequence. h_0 of shape (num_layers * num_directions, batch_size, hidden_size):
tensor containing the initial hidden state for each element in the
batch. Defaults to zero if not provided. If the RNN is bidirectional,
num_directions should be 2, else it should be 1.
forward函数的返回值是:
output of shape (num_steps, batch_size, num_directions *hidden_size): tensor containing the output features (h_t) from the
last layer of the RNN, for each t. h_n of shape (num_layers * num_directions, batch_size, hidden_size):
tensor containing the hidden state for t = num_steps.
class RNNModel(nn.Module):
def __init__(self, rnn_layer, vocab_size):
super(RNNModel, self).__init__()
self.rnn = rnn_layer
self.hidden_size = rnn_layer.hidden_size * (2 if rnn_layer.bidirectional else 1)
self.vocab_size = vocab_size
self.dense = nn.Linear(self.hidden_size, vocab_size)
def forward(self, inputs, state):
# inputs.shape: (batch_size, num_steps)
X = to_onehot(inputs, vocab_size)
X = torch.stack(X) # X.shape: (num_steps, batch_size, vocab_size)
hiddens, state = self.rnn(X, state)
hiddens = hiddens.view(-1, hiddens.shape[-1]) # hiddens.shape: (num_steps * batch_size, hidden_size)
output = self.dense(hiddens)
return output, state
参考资料:《动手学深度学习》
作者:weixin_43100127