普通链表和循环链表的逆置
首先是普通链表:
template
void LinkList::Reverse()
{
Node* p; Node* q;
p = first->next;
first->next = NULL;
while (p)
{
q = p;
p = p->next;
q->next = first->next;//前驱变后继
first->next = q;
}
}
其次是循环链表:
template
void LinkList::Reverse()
{
Node* p,*q,*r;
q = first;
p = first->next; //有头结点
q->next = first;//构成空循环链表
while (p != first) //循环单链表
{
r = p->next;
p->next = q->next; //前驱变后继
q->next = p;
p = r;
} //准备处理下一结点
}
虽说很清楚,循环链表不过是普通链表的进阶版,但是还是折腾了半天没弄出来。
现在总结一下:
第一步:普通链表构成一个空表(有头结点),循环链表构成一个空循环表(有头结点)
第二步:建立循环,很显然的区别,普通链表是以指针是否为空为条件,循环链表以指针不为头指针为条件
第三步:循环的内容,这是关键部分,怎么把前驱变后继是重中之重。
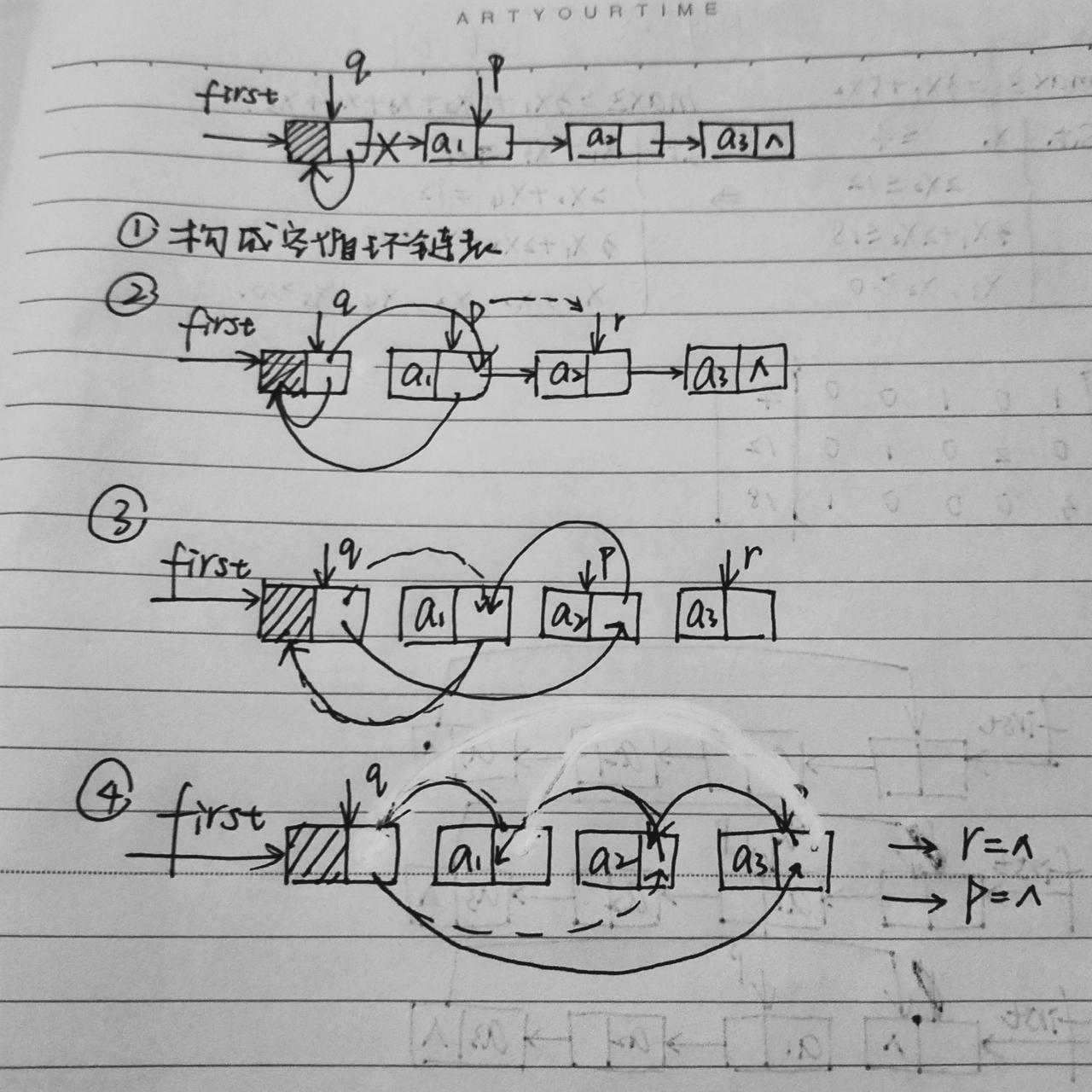
(画了一个相当丑的图示说明循环链表的逆置)
实际上,两种链表都运用了三个指针来解决。
普通链表:(一步步梳理吧)1.first->next每次指向的都是q指向的(待处理)数的前驱,所以每次就直接将first->next指向的数变为q指向的数的后继,就成功完成了前驱变后继这个步骤(把前驱从first那里接来变后继)。2.但是怎么让first->next指向待处理数的前驱呢?实际上!链表本来就是有序的,让first->next每次在结束时都等于q,就是让first->next指向下一个q的前驱。3.但是,非常重要,也容易忽略的问题是!当前p->next已改变,怎么才能找到它原来的后继呢?所以一个永远在链表上q指针之后的p指针,以确保q每次都能顺利地顺序后移。
然后从头捋一遍:从first->next(即a1)开始处理,确定了q的位置之后,p就可以后移了。接下来就交给first->next和q来解决,即将前驱(first->next顺序后移,即指向q)变后继(q->next指向first->next)。
OK!
循环链表的不同之处仅在于一开始要形成空循环链表,相当于普通链表里的两个节点,其他处理都相同。
作者:WMiracleW