飞桨学院-Python从小白逆袭大神-Day5-综合大作业
七日的打卡营,这次第五次的作业了,也是最后一次的作业了,小编看了一下啊,其实这次的作业是之前4次作业的大融合,集文件处理,爬虫,还有数据可视化,以及paddlehub的使用。但是这次还是有些难度的,因为嘛,这次的作业没有之前的写好的代码,全靠自己。还好上课老师还有代码参考,不然的话真是难倒我了。
综合大作业第一步:爱奇艺《青春有你2》评论数据爬取(参考链接:https://www.iqiyi.com/v_19ryfkiv8w.html#curid=15068699100_9f9bab7e0d1e30c494622af777f4ba39)
爬取任意一期正片视频下评论
评论条数不少于1000条
第二步:词频统计并可视化展示
数据预处理:清理清洗评论中特殊字符(如:@#¥%、emoji表情符),清洗后结果存储为txt文档
中文分词:添加新增词(如:青你、奥利给、冲鸭),去除停用词(如:哦、因此、不然、也好、但是)
统计top10高频词
可视化展示高频词
第三步:绘制词云
根据词频生成词云
可选项-添加背景图片,根据背景图片轮廓生成词云
第四步:结合PaddleHub,对评论进行内容审核
下面我将分享我理解的和做题的过程。
因为AiStudio是基于Linux操作系统,所以下面的命令是Linux命令。
!pip install jieba #这是一个分词库
!pip install wordcloud #这是一个词云库
# Linux系统默认字体文件路径
!ls /usr/share/fonts/
# 查看系统可用的ttf格式中文字体
!fc-list :lang=zh | grep ".ttf"
#!wget https://mydueros.cdn.bcebos.com/font/simhei.ttf # 下载中文字体
# #创建字体目录fonts
#!mkdir .fonts
# # 复制字体文件到该路径
!cp simhei.ttf .fonts/
!ls .fonts/
!ls .cache/
!rm -rf .cache/matplotlib
#安装模型
!hub install porn_detection_lstm==1.1.0
!pip install --upgrade paddlehub
导入库
from __future__ import print_function
import requests
import json
import re #正则匹配
import time #时间处理模块
import jieba #中文分词
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import matplotlib.font_manager as font_manager
from PIL import Image
from wordcloud import WordCloud #绘制词云模块
import paddlehub as hub
数据爬取
#请求爱奇艺评论接口,返回response信息
def getMovieinfo(url):
'''
请求爱奇艺评论接口,返回response信息
参数 url: 评论的url
:return: response信息
'''
headers={
'Host': 'sns-comment.iqiyi.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; rv:75.0) Gecko/20100101 Firefox/75.0 Chrome/49.0.2623.221',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1'
}
session = requests.Session()
response = session.get(url, headers = headers)
if response.status_code is 200:
return response.text
return None
#解析json数据,获取评论
def saveMovieInfoToFile(lastId,arr):
'''
解析json数据,获取评论
参数 lastId:最后一条评论ID arr:存放文本的list
:return: 新的lastId
'''
url = "https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&\
agent_version=9.11.5&authcookie=null&business_type=17&content_id=15068699100&hot_size=0&\
last_id=240634156221&page=&page_size=20&types=time&callback=jsonp_1587986745841_61260"
url += "&last_id=" + str(lastId)
response_text = getMovieinfo(url)
js = json.loads(response_text[31:-14])
comments = js['data']['comments']
for comment in comments:
if 'content' in comment.keys():
arr.append(comment['content'])
lastId = str(comment['id'])
return lastId
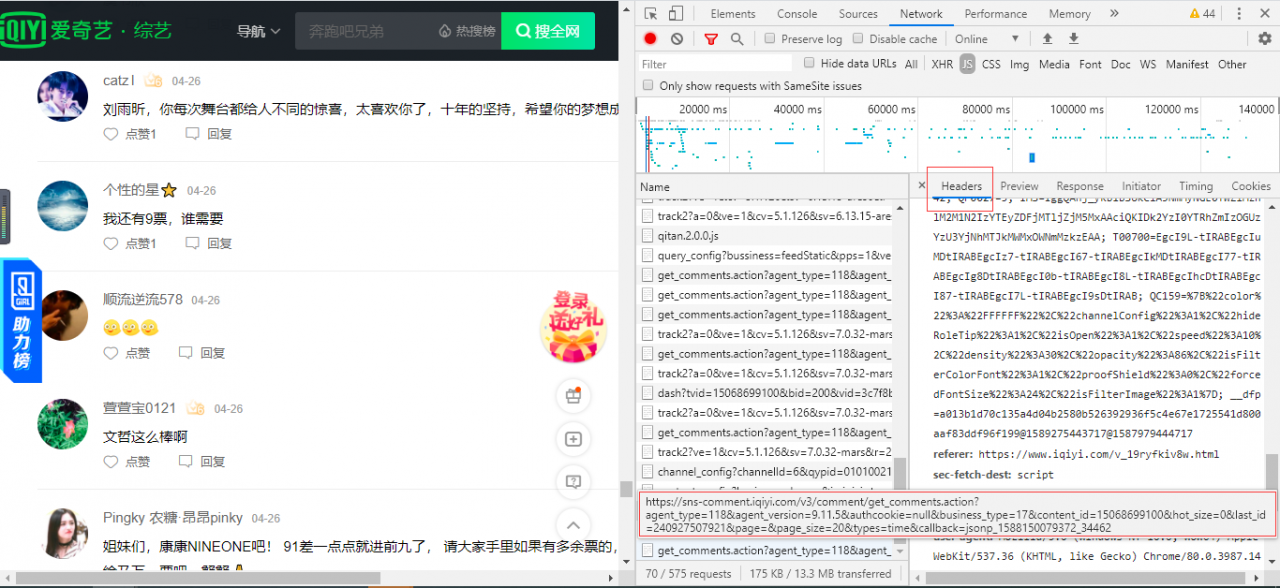
爬虫爬取数据通常较灵活,在爬取评论的时候,我们就要看看实际情况,像爱奇艺的评论爬取就不同。站点分析在这里:
 原创文章 7获赞 11访问量 949
关注
私信
展开阅读全文
原创文章 7获赞 11访问量 949
关注
私信
展开阅读全文
作者:Miller_em