PyTorch学习笔记(四)调整学习率
Environment
OS: macOS Mojave Python version: 3.7 PyTorch version: 1.4.0 IDE: PyCharm 文章目录0. 写在前面1. StepLR1.1 scheduler 常用的属性1.2 scheduler 常用的方法2. MultiStepLR3. ExponentialLR4. ReduceLROnPlateau5. LambdaLR0. 写在前面
PyTorch 在 torch.optim.lr_scheduler 中提供了十种调整学习率的类,它们的基类为 torch.optim.lr_scheduler._LRScheduler。
这里记常用的一些。详尽的参考 PyTorch 官方文档。
StepLR 类,按固定间隔调整学习率
lr=lr×gamma
lr = lr \times gamma
lr=lr×gamma
import matplotlib.pyplot as plt
import seaborn as sns
import torch
from torch.optim import SGD
from torch.optim.lr_scheduler import StepLR
# config
learning_rate = 1.
num_epochs = 50
# create weight, optimizer and scheduler
weight = torch.randn((1,), dtype=torch.float32)
optimizer = SGD([weight], lr=learning_rate, momentum=0.9)
scheduler = StepLR(
optimizer=optimizer,
step_size=10, # 设定间隔数
gamma=0.1, # 系数
last_epoch=-1
)
# train-like iteration
lrs, epochs = [], []
for epoch in range(num_epochs):
lrs.append(scheduler.get_lr())
epochs.append(epoch)
pass # iter and train here
scheduler.step()
# visualize
sns.set_style('whitegrid')
plt.figure(figsize=(10, 6))
plt.plot(epochs, lrs, label='StepLR')
plt.legend()
plt.show()

以 StepLR 类为例,记一下 scheduler 重要的属性和方法
scheduler.optimizer 关联优化器
print(scheduler.optimizer == optimizer) # True
print(id(scheduler.optimizer) == id(optimizer)) # True
scheduler.base_lrs 存储各组的初始学习率
print(scheduler.base_lrs) # [1.0]
scheduler.last_epoch 记录 epoch 数,应该是可以用在断点续训练中(但尚未用到)
print(scheduler.last_epoch) # 0
1.2 scheduler 常用的方法
scheduler.step() 更新至下一个 epoch 的学习率
scheduler.get_lr() 获得当前各组的学习率,个别优化器类的实例没有该方法(如 ReduceLROnPlateau)
import torch
from torch.optim import SGD
from torch.optim.lr_scheduler import StepLR
# create weight, optimizer and scheduler
weight = torch.randn((1,), dtype=torch.float32)
optimizer = SGD([weight], lr=1., momentum=0.9)
scheduler = StepLR(optimizer, step_size=10, gamma=0.1)
print('Default learning_rate:', optimizer.defaults['lr'])
print('Original learning_rate:', optimizer.param_groups[0]['lr'])
print()
for epoch in range(20):
scheduler.step()
if (epoch + 1) % 5 == 0:
print('scheduler.step() run', epoch + 1, 'times')
print('Current learning_rate:', optimizer.param_groups[0]['lr'])
print('Current learning_rate:', scheduler.get_lr())
print()
打印出
Default learning_rate: 1.0
Original learning_rate: 1.0
scheduler.step() run 5 times
Current learning_rate: 1.0
Current learning_rate: [1.0]
scheduler.step() run 10 times
Current learning_rate: 0.1
Current learning_rate: [0.1]
scheduler.step() run 15 times
Current learning_rate: 0.1
Current learning_rate: [0.1]
scheduler.step() run 20 times
Current learning_rate: 0.010000000000000002
Current learning_rate: [0.010000000000000002]
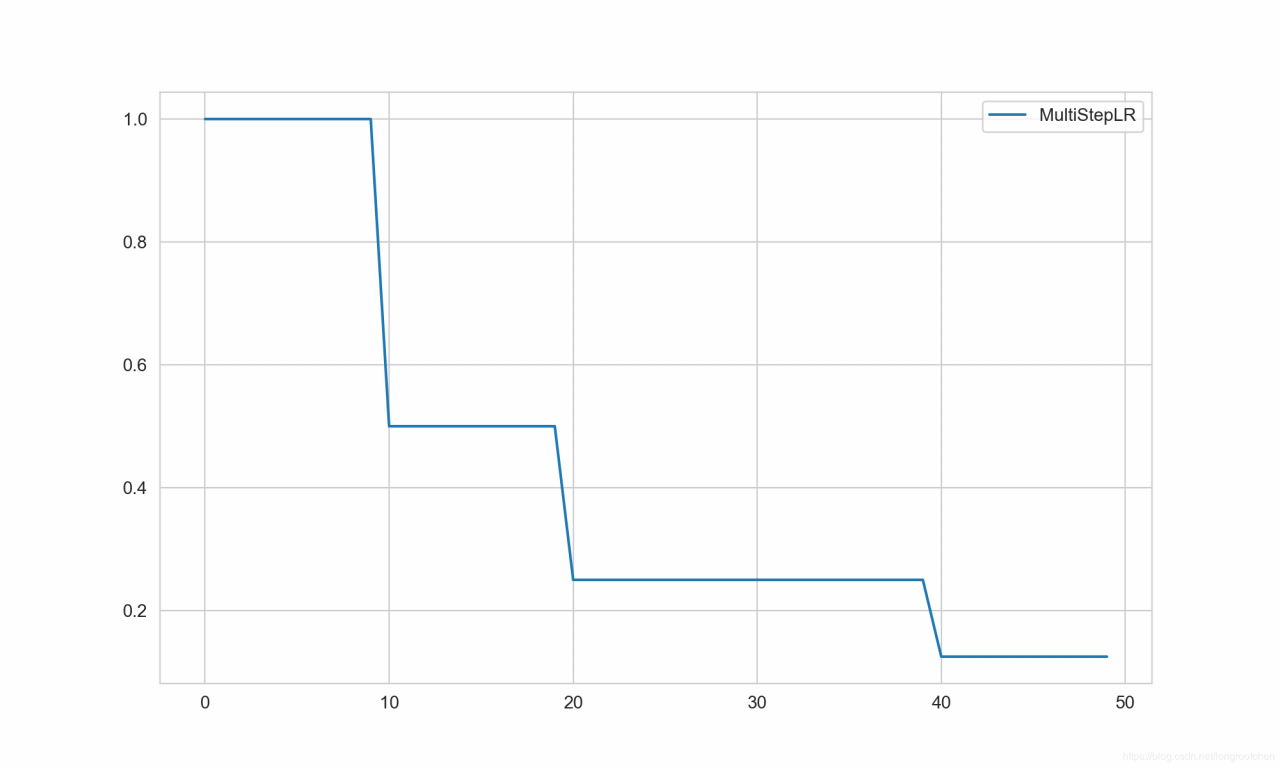
2. MultiStepLR
MultiStepLR 类,给定间隔调整学习率
lr=lr×gamma
lr = lr \times gamma
lr=lr×gamma
import matplotlib.pyplot as plt
import seaborn as sns
import torch
from torch.optim import SGD
from torch.optim.lr_scheduler import MultiStepLR
# config
learning_rate = 1.
num_epochs = 50
# create weight, optimizer and scheduler
weight = torch.randn((1,), dtype=torch.float32)
optimizer = SGD([weight], lr=learning_rate, momentum=0.9)
scheduler = MultiStepLR(
optimizer=optimizer,
milestones=[10, 20, 40], # 设定调整的间隔数
gamma=0.5, # 系数
last_epoch=-1
)
# train-like iteration
lrs, epochs = [], []
for epoch in range(num_epochs):
lrs.append(scheduler.get_lr())
epochs.append(epoch)
pass # iter and train here
scheduler.step()
# visualize
sns.set_style('whitegrid')
plt.figure(figsize=(10, 6))
plt.plot(epochs, lrs, label='MultiStepLR')
plt.legend()
plt.show()
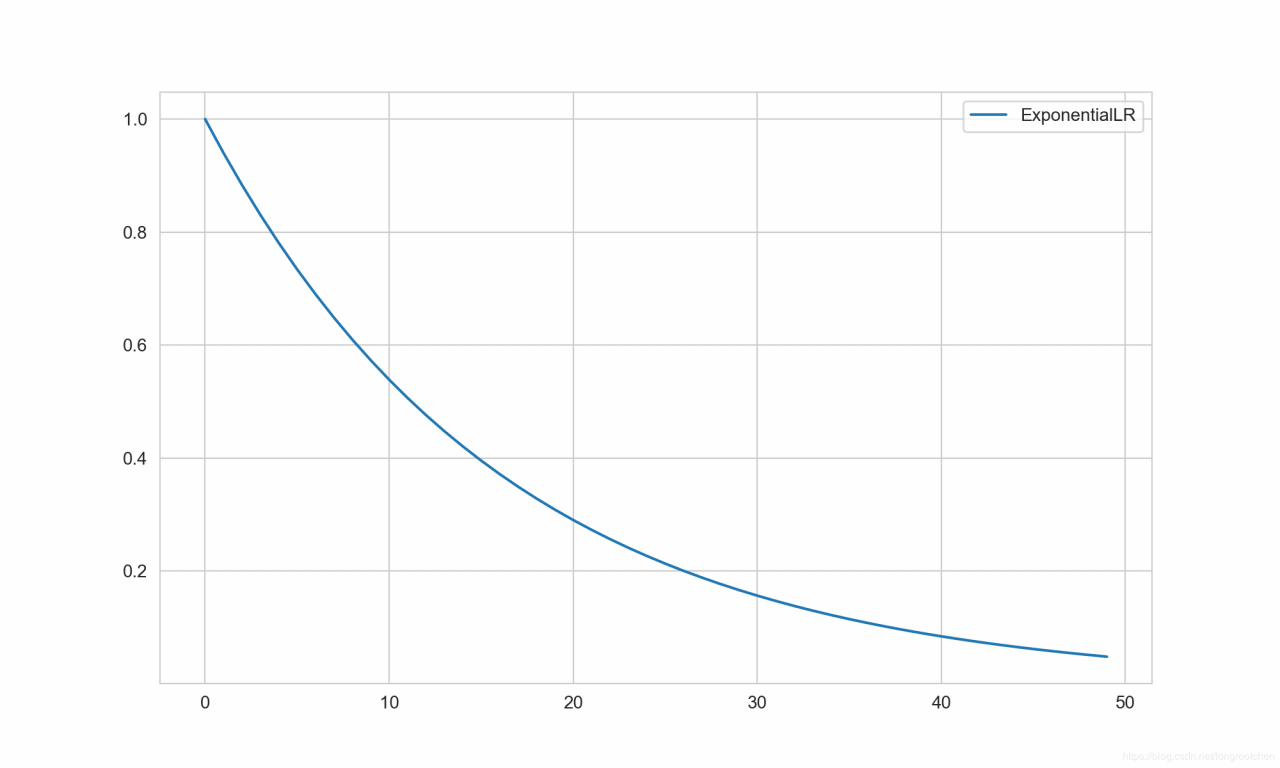
ExponentialLR 类,按指数衰减调整学习率
lr=lr×gammaepoch
lr = lr \times gamma^{epoch}
lr=lr×gammaepoch
import matplotlib.pyplot as plt
import seaborn as sns
import torch
from torch.optim import SGD
from torch.optim.lr_scheduler import ExponentialLR
# config
learning_rate = 1.
num_epochs = 50
# create weight, optimizer and scheduler
weight = torch.randn((1,), dtype=torch.float32)
optimizer = SGD([weight], lr=learning_rate, momentum=0.9)
scheduler = ExponentialLR(
optimizer=optimizer,
gamma=0.94, # 指数的底,通常设为一个接近于 1 的数
last_epoch=-1
)
# train-like iteration
lrs, epochs = [], []
for epoch in range(num_epochs):
lrs.append(scheduler.get_lr())
epochs.append(epoch)
pass # iter and train here
scheduler.step()
# visualize
sns.set_style('whitegrid')
plt.figure(figsize=(10, 6))
plt.plot(epochs, lrs, label='MultiStepLR')
plt.legend()
plt.show()
ReduceLROnPlateau类,当某监控指标不再变化时调整学习率。注意,该类并没有实例方法 get_lr()。
import matplotlib.pyplot as plt
import seaborn as sns
import torch
from torch.optim import SGD
from torch.optim.lr_scheduler import ReduceLROnPlateau
# config
learning_rate = 1.
num_epochs = 50
# create weight, optimizer and scheduler
weight = torch.randn((1,), dtype=torch.float32)
optimizer = SGD([weight], lr=learning_rate, momentum=0.9)
scheduler = ReduceLROnPlateau(
optimizer,
mode='min', # 默认为 'min',表示监控指标不再减小则调整学习率;传入 'max' 反之,不再增大则调整
factor=0.1, # 调整系数,即 StepLR 中的 gamma
patience=10, # 监控的指标几轮没有变化(减小 / 增大)则调整
verbose=True, # 是否打印出学习率的变化
threshold=0.0001, # 变化(减小 / 增大)的量,小于此量则认为不变化(减小 / 增大)
threshold_mode='rel', # 结合 mode='min' 或 mode='max',不同的监测公式
cooldown=0, # 调整后停止监控几波,过了这段之后再继续监控
min_lr=0, # 学习率下限
eps=1e-08 # 学习率衰减的最小值
)
# create a initial loss that fails to lower
loss = 0.5
# train-like iteration
for epoch in range(num_epochs):
pass # iter and train here
scheduler.step(loss) # input the loss
损失十轮不下降,则调整学习率。打印出
Epoch 11: reducing learning rate of group 0 to 1.0000e-01.
Epoch 22: reducing learning rate of group 0 to 1.0000e-02.
Epoch 33: reducing learning rate of group 0 to 1.0000e-03.
Epoch 44: reducing learning rate of group 0 to 1.0000e-04.
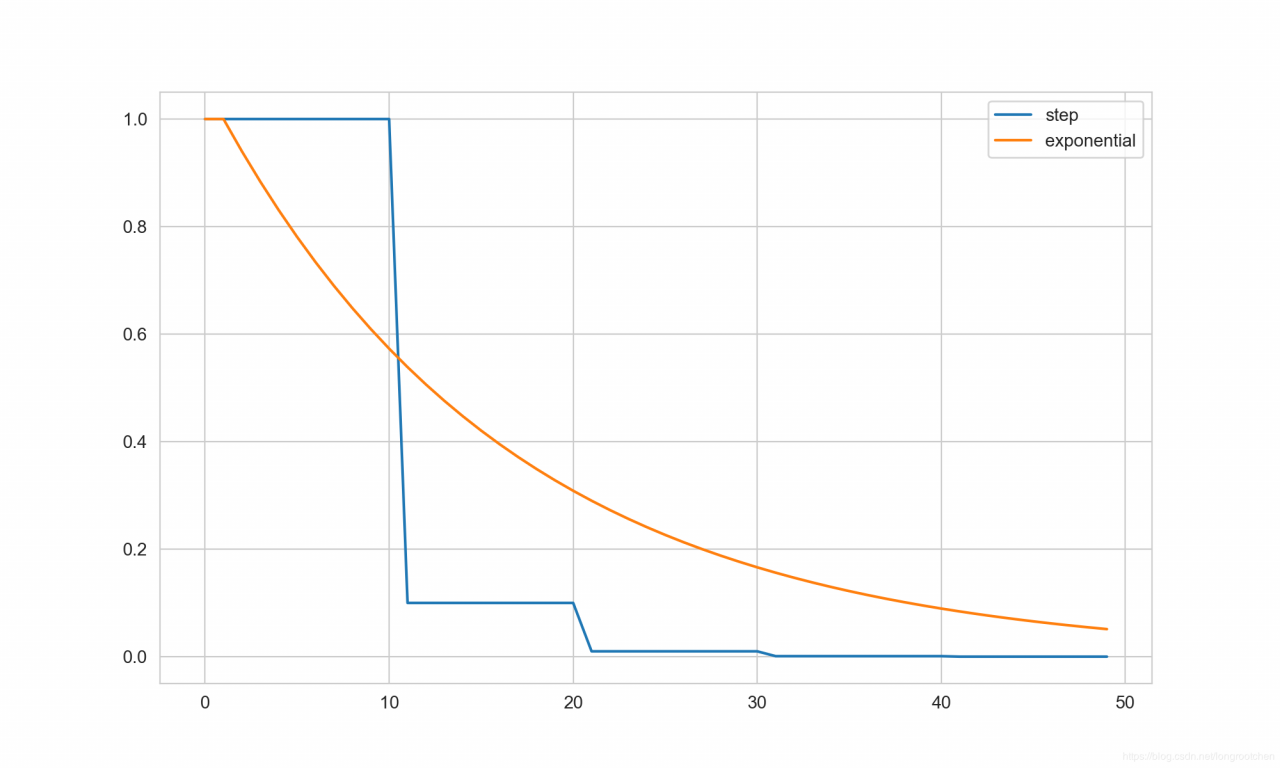
5. LambdaLR
LambdaLR 类,对不同参数组设置不同的调整策略,可用于迁移学习中模型的微调
import matplotlib.pyplot as plt
import seaborn as sns
import torch
from torch.optim import SGD
from torch.optim.lr_scheduler import LambdaLR
# config
learning_rate = 1.
num_epochs = 50
# create weight, optimizer and scheduler
conv_weight = torch.randn((6, 3, 5, 5))
linear_weight = torch.randn((5, 5))
optimizer = SGD([{'params': [conv_weight]}, {'params': [linear_weight]}], lr=learning_rate) # grouped optimizer
# 对于卷积层权重的学习率,每十轮调整为原来的 0.1 倍
conv_lambda = lambda epoch: 0.1 ** (epoch // 10)
# 对于全连接层权重的学习率,每轮调整为原来的 0.94 倍
linear_lambda = lambda epoch: 0.94 ** epoch
scheduler = LambdaLR(
optimizer,
lr_lambda=[conv_lambda, linear_lambda], # 传入一个函数或一个以函数为元素列表,作为学习率调整的策略
last_epoch=-1
)
# train-like iteration
conv_lrs, linear_lrs, epochs = [], [], []
for epoch in range(num_epochs):
conv_lrs.append(scheduler.get_lr()[0])
linear_lrs.append(scheduler.get_lr()[1])
epochs.append(epoch)
pass # iter and train here
scheduler.step(epoch)
# visualize
sns.set_style('whitegrid')
plt.figure(figsize=(10, 6))
plt.plot(epochs, conv_lrs, label='step')
plt.plot(epochs, linear_lrs, label='exponential')
plt.legend()
plt.show()
作者:longrootchen