Pytorch 如何训练网络时调整学习率
为了得到更好的网络,学习率通常是要调整的,即刚开始用较大的学习率来加快网络的训练,之后为了提高精确度,需要将学习率调低一点。
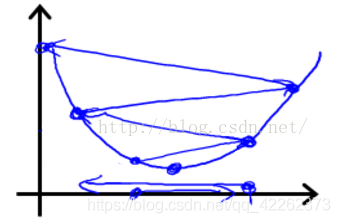
如图所示,步长(学习率)太大容易跨过最优解。
表示每20个epoch学习率调整为之前的10%
optimizer = optim.SGD(gan.parameters(),
lr=0.1,
momentum=0.9,
weight_decay=0.0005)
lr = optimizer.param_groups[0]['lr'] * (0.1 ** (epoch // 20))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
print(optimizer.param_groups[0]['lr'])
补充:Pytorch 在训练过程中实现学习率衰减
在网络的训练过程中,学习率是一个非常重要的超参数,它直接影响了网络的训练效果。
但过大的学习率将会导致网络无法达到局部最小点,使得训练结果震荡,准确率无法提升,而过小的学习率将会导致拟合速度过慢,浪费大量的时间和算力。
因此我们希望在训练之初能够有较大的学习率加快拟合的速率,之后降低学习率,使得网络能够更好的达到局部最小,提高网络的效率。
torch.optim.lr_scheduler.LambdaLR()
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1)
其中optimizer就是包装好的优化器, lr_lambda即为操作学习率的函数。
将每个参数组的学习速率设置为初始的lr乘以一个给定的函数。
当last_epoch=-1时,将初始lr设置为lr。
torch.optim.lr_scheduler.StepLR()
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)
其中optimizer就是包装好的优化器,step_size (int) 为学习率衰减期,指几个epoch衰减一次。gamma为学习率衰减的乘积因子。 默认为0.1 。当last_epoch=-1时,将初始lr设置为lr。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持软件开发网。
相关文章
Iris
2021-08-03
Dolly
2021-04-26
Manda
2020-08-09
Cynthia
2020-09-01
Tani
2023-05-27
Tanisha
2023-05-27
Kande
2023-05-27
Tricia
2023-05-27
Pandora
2023-07-07
Tallulah
2023-07-17
Janna
2023-07-20
Ophelia
2023-07-20
Natalia
2023-07-20
Xylona
2023-07-20
Radinka
2023-07-20
Dorothy
2023-07-20
Irma
2023-07-20
Kirima
2023-07-20