Java学习之 手撕String
java.lang包,不需要import导入。
继承关系除默认继承java.lang.Object类外,无其它任何继承关系。
实现了Serializable, CharSequence, Comparable这三个接口。
String是一个非常特殊的引用数据类型,可以像基本数据类型一样赋值创建,也可以通过new的方式调用构造方法创建String对象。
String s1 = "abc";
String s2 = new String("abc");
但是要注意,两种方式创建的String对象是有着本质区别的。
通过直接赋值的方式创建的String对象虽然不是常量,但可以视为常量,它被放在常量缓冲区内。而通过new构造出来的String对象放在推内存里。
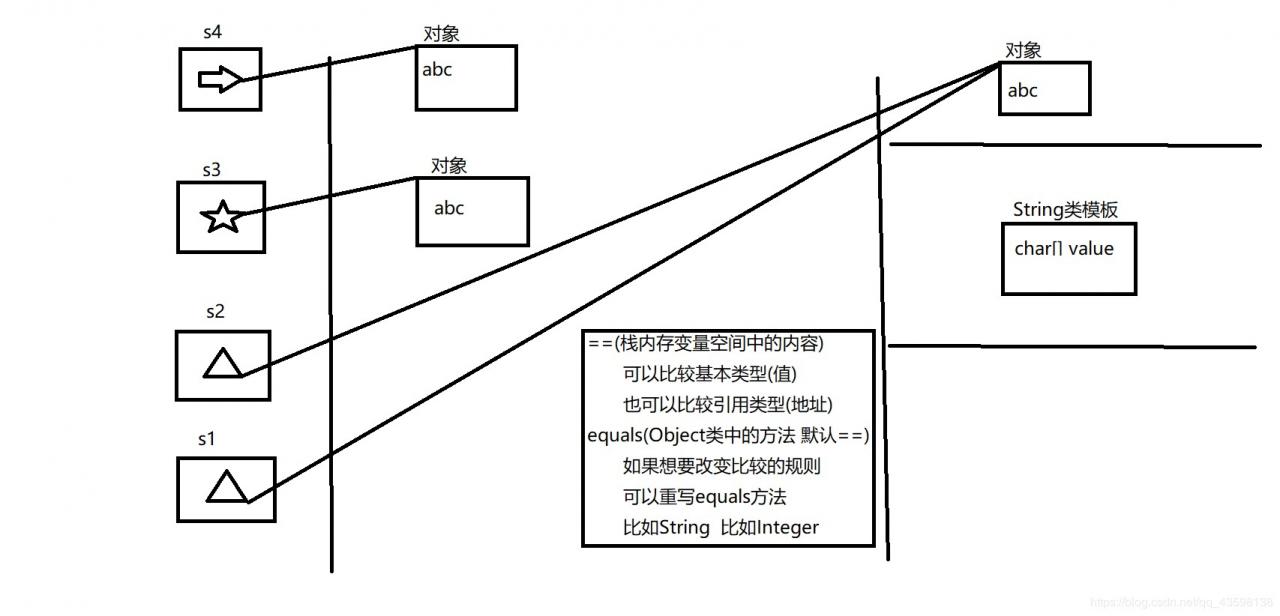
明白了它的存储方式,我们再来看看下面代码的执行结果:
public static void main(String[] args) {
String s1 = "abc";
String s2 = "abc";
String s3 = new String("abc");
String s4 = new String("abc");
System.out.println(s1==s2);//true
System.out.println(s1==s3);//false
System.out.println(s3==s4);//false
System.out.println(s1.equals(s2));//true
System.out.println(s1.equals(s3));//true
System.out.println(s3.equals(s4));//true
}
最后三个输出的都是true,是由于String类重写了Object类中的equals方法,它比较的不是对象的引用,而是字符串的值。
String类的其他构建方式:
String str = new String(byte[] )
byte[] b = new byte[]{65,97,48,57};
String s = new String(b);
System.out.println(s);//Aa09
将数组中的每一个char字符拼接成String:String str = new String(char[] )
char[] crr = new char[]{'a','c','e'};
String s1 = new String(crr);
System.out.println(s1);//ace
String类的特性
String类的不可变性
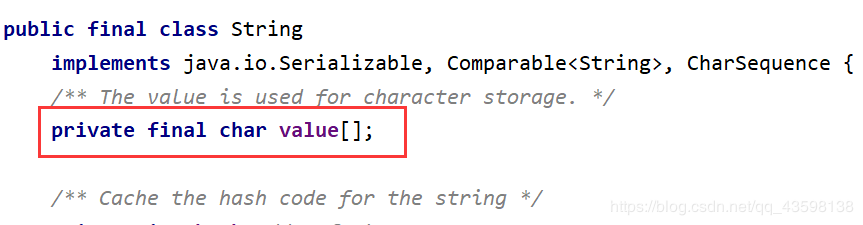
有三个关键点:final,数组[],private
String对象的内容底层使用的是一个名为value的数组来存储。
这个数组使用private修饰—>不能在外部访问
使用final修饰—>它的地址不能改变
使用数组[]存储—>长度不可改变
也就是说,String的不可变性,体现在两个地方:长度和内容。
长度—>final修饰的数组,数组长度本身不变 , final修饰数组,它的地址也不变 private修饰的属性,不能在类的外部访问 String类中常用的方法(20+个) equals()重写自Object 类的方法,用来比较两个字串中的字面值是否相等。
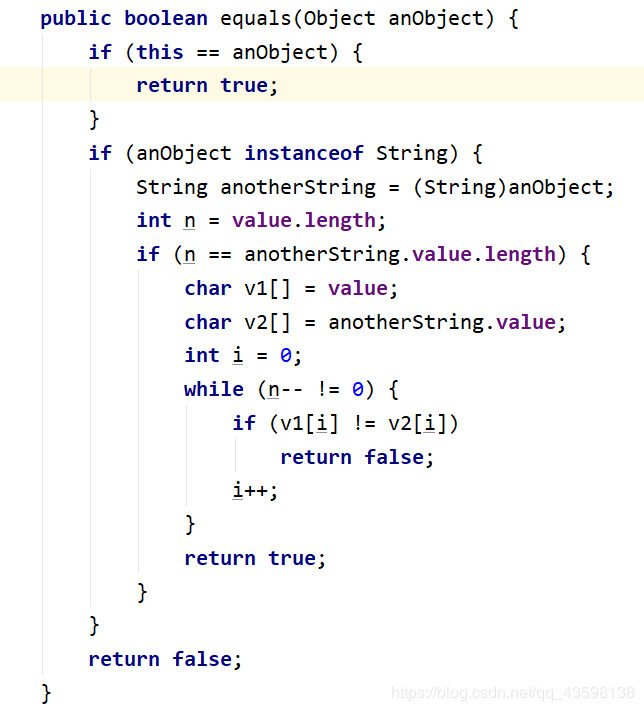
它的比较过程是:先用 == 比较地址,如果地址相等,直接返回true,地址不相等,接着往下比,然后使用 instanceof 关键字判断比较的对象是不是属于String类型,如果不属于直接返回false,如果属于String则接着比较,首先造型(把待比较对象造型成String),然后比较两个字符串的长度,如果长度不相等,返回false,长度相等,接着比较,用char数组接收每个字符串的value属性(该属性本身就是char数组),再利用while循环不断比较每个字符是否相等,如果有一个字符不相等,直接返回false,直到while循环执行完毕,所有字符都相等,则返回true。
忽略大小写比较字符串,比较机制与equals()相同
hashCode()重写自Object 类的方法(默认情况下内存地址调用一个本地的native方法进行计算),将当前字符串的每一个char元素拆开,乘以31求和,返回值是int型。


首先,字符串有一个int型的hash属性(属性的默认值为0),它的hashCode()方法执行过程为:
先把该字符串的属性hash复制给变量h,判断h是否为0,如果是0则代表该字符串已经计算过hash,并且同时该字符串的长度大于0,就不再重新计算,直接把hash原封不动地返回(显而易见,空串的hash值没有经过计算,取的是默认值0),如果以上条件不满足,就开始计算hash值,首先拿到字符串的char数组,然后依次遍历每一个字符,将31乘以h的值加上该字符的Unicode码再赋值到h变量中,不断累加,最终计算出整个字符串的hash值。
System.out.println("a".hashCode());//31*0+97 = 97
System.out.println("ab".hashCode());//(31*0+97)*31+98 = 3105
System.out.println("abc".hashCode());//((31*0+97)*31+98)*31 + 99 = 3105*31+99 = 96354
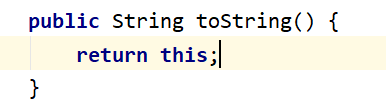
toString()
重写自Object 类的方法,不再输出 类名@hashCode,而是输出字符串中的字面值。
实现自Comparable接口的方法, 按照字典(Unicode编码)索引的顺序比较,并返回一个int值。

它比较字符串的计算过程是:首先拿到两个字符串各自的长度,用变量接收这两个长度,取长度最小值赋值给变量lim,利用while循环,循环lim次(也就是最短的字符串中的每个字符肯定遍历完了),比较相同索引下两个字符串的char数组里面的字符值,如果字符值不一致,返回两个字符值的Unicode差值。如果遍历结束后,发现遍历到的每个字符都一样,则返回两个字符串长度的差值。
System.out.println("abc".compareTo("abc"));//0
System.out.println("abc".compareTo("abb"));//1 -->c - b = 99 - 98 = 1
System.out.println("abb".compareTo("abc"));//-1 -->b - c = 98 - 99 = -1
System.out.println("abc".compareTo("ab"));//1 -->length1 - length2 = 3-2 = 1
compareToIgnoreCase()
忽略大小写比较字符串,比较机制与compareTo()相同
int = charAt(int index)返回给定index对应位置的那个char值
String str = "abcdef";
for (int i = 0;i<str.length();i++){
System.out.println(str.charAt(i));
}
int = codePointAt(int index)
返回给定index对应位置的那个char所对应的Unicode码
String str = "abcdef";//-->123456
String result = "";
for(int i=0;i<str.length();i++){
int value = str.codePointAt(i);
result += (char)(value-48);//密钥 U盾
}
System.out.println(result);//123456
length()
返回字符串的长度
String = concat(String str)将给定的字符串拼接在当前字符串之后
【注意】:方法执行完毕需要接收返回值(由于String的不可变特性)。
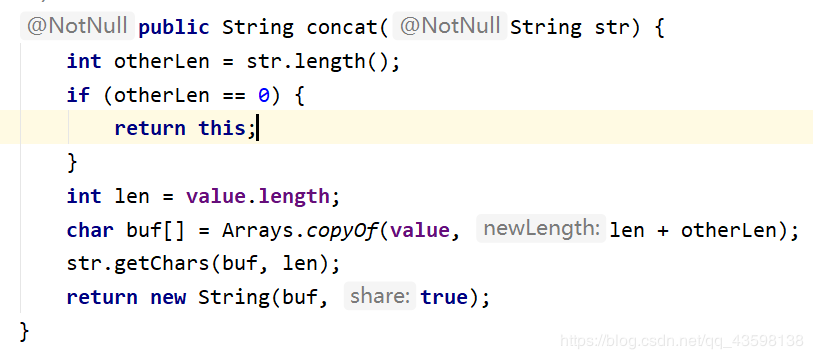
用concat()拼接字符串的速度比用加号拼接字符串快!
例如,用加号拼接:
String str = "a"+"b"+"c"+"d"+"e";
每一个双引号代表一个String对象,而拼接的过程,会产生一个新的String对象。
“ab” = “a”+“b”;—>“abc” = “ab”+“c”;—>“abcd” = “abc”+“d”;······
因此每一个加号,都会临时创建一个新的对象用来字符串的拼接。
所以上面的一行代码,涉及到9个String对象和一个str变量。空间复杂度比较高,执行起来相对慢。
而concat()方法,会在底层不断创建小数组,来拼接字符串。
一般而言,concat()的效率比 + 高。
我们拼接20万个字符串,来对比两程序的运行时间:
String str = "a";
long time1 = System.currentTimeMillis();
for(int i = 1;i<=200000;i++){
str+="a";
}
long time2 = System.currentTimeMillis();
System.out.println("利用+号拼接字符串的时间:"+(time2-time1));//6492毫秒
String str = "a";
long time1 = System.currentTimeMillis();
for(int i = 1;i<=200000;i++){
str = str.concat("a");
}
long time2 = System.currentTimeMillis();
System.out.println("利用concat拼接字符串的时间:"+(time2-time1));//3846毫秒
【注意】:虽然concat()的性能优于 + ,但是在开发中如果遇到频繁的拼接字符串,我们通常使用的是StringBuilder / StringBuffer。
StringBuilder 和StringBuffer它们叫做可变字符串,它们底层的那个数组不是final修饰的,可以通过自己的方式扩容,在拼接字符串时不会产生新的对象,因此效率更高。
区别:StringBuffer是线程安全的,操作起来效率比较低但是安全性比较高,而StringBuilder刚好相反,它的效率很高,但是同一时间有很多人可以操作它,由此带来了多线程的安全隐患问题。
判断给定的子串是否在字符串中存在
String str = "abcdefg";
//判断此字符串中是否含有de
boolean value = str.contains("de");
System.out.println(value);//true
boolean = startsWith(String prefix)
判断当前字符串是否以prefix开头
String str = "TestString.java";
boolean value = str.startsWith("Test");
System.out.println(value);//true
boolean = endsWith(String suffix);
判断当前字符串是否以suffix结尾
String str = "TestString.java";
boolean value = str.endsWith(".java");
System.out.println(value);//true
byte[] = getBytes()
将当前字符串转化成byte[]数组
String str = "abcdef";
for(int v:str.getBytes()){
System.out.print(v+" ");//97 98 99 100 101 102
}
方法重载:getBytes(String charsetName)
char[] = toCharArray()将当前字符串转化成char[]数组
String str = "abcdef";
for(char v:str.toCharArray()){
System.out.print(v);//abcdef
}
getBytes()和toCharArray()的注意点
虽然二者功能类似,有时候getBytes()可以代替toCharArray(),toCharArray()也可以代替getBytes(),只要进行数据的强制类型转换即可,但是:
“字节”是byte,“位”是bit ;
1 byte = 8 bit ;
java采用unicode编码,2个字节(16位)来表示一个字符。
char 在java中是2个字节,而byte在java中占1个字节。
Java采用unicode来表示字符,java中的一个char是2个字节,一个中文或英文字符的unicode编码都占2个字节,但如果采用其他编码方式,一个字符占用的字节数则各不相同。
在 GB 2312 编码或 GBK 编码中,一个英文字母字符存储需要1个字节,一个汉子字符存储需要2个字节。
在UTF-8编码中,一个英文字母字符存储需要1个字节,一个汉字字符储存需要3到4个字节。
在UTF-16编码中,一个英文字母字符存储需要2个字节,一个汉字字符储存需要3到4个字节(Unicode扩展区的一些汉字存储需要4个字节)。
在UTF-32编码中,世界上任何字符的存储都需要4个字节。
可参考如下文章: Java一个汉字占几个字节(详解与原理)(转载).
因此,总的来说,不同的编码格式占字节数是不同的,UTF-8编码下一个中文所占字节也是不确定的,可能是2个、3个、4个字节。
这样一来,如果字符串中存储的是汉字,这个字符串调用toCharArray()将其转换成char类型的数组是没有问题的,但是如果调用getBytes()则会出问题。
因为一个汉字最起码占2个字节,而byte类型是存不下的,既然存不下,它就会把汉字拆开。
String str = "我爱你中国";
byte[] b = str.getBytes();
int index = 0;
for(byte v:b){
index++;
System.out.println(index+":"+v);
}

5个汉字的字符串,按照字节拆分,拆成了15份,猜想每个汉字占据3个字节。
接着,我又把字符集加上:
b = str.getBytes("utf-8");
结果和上面的执行结果完全一致,可见它默认就是采用的utf-8的编码。
而至于为什么char类型2个字节却可以存储汉字,应该是它采用的其他编码吧。
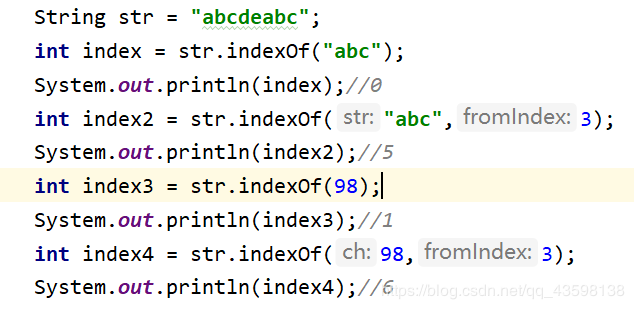
找寻给定的元素在字符串中第一次出现的索引位置,若字符串不存在则返回-1
四个方法重载

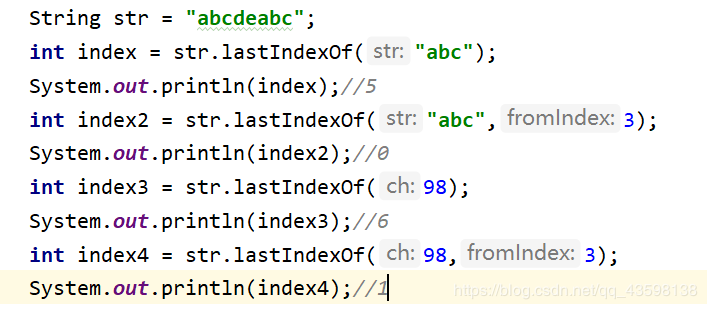
找寻给定的元素在字符串中最后一次出现的索引位置 若不存在则返回-1
四个方法重载

小总结:
indexOf()方法就相比于contains方法就更实用一点,因为它不仅能检测子串在不在字符串里面,还能返回它第一次出现的索引值。
调用indexOf()时如果有参数fromIndex,则检测fromIndex开始到字符串结尾的区间,找寻子串第一次出现的位置,返回相对于整个字符串的索引值。(找的时候看后半部分,返回的索引相对于字符串整体)。
调用lastIndexOf()时如果有参数fromIndex,则检测从索引值0开始到fromIndex结尾的区间,找寻子串最后一次出现的位置,返回相对于整个字符串的索引值。(找的时候看前半部分,返回的索引相对于字符串整体)
也可以这样记忆:
indexOf()从前往后找第一次出现的位置。
lastIndexOf()从后往前找第一次出现的位置。
它有9个方法重载,它是static修饰的静态方法,用来将各种参数转化成字符串的表现形式。
参数可以传的类型有boolean,char,char[],double,float,int,long,Object
boolean b = true;
String ss = String.valueOf(b);
System.out.println(ss);//true
Scanner input = new Scanner(System.in);
String str = String.valueOf(input);
System.out.println(str);//java.util.Scanner[delimiters=\p{javaWhitespace}+][position=0][match valid=false][need input=false][source closed=false][skipped=false]······
isEmpty()
判断当前字符串是否为空字符串 (length是否为0)
注意: 空串与null之间的区别
将给定的字符串替换成另外的字符串
replace(char oldChar, char newChar) replace(CharSequence target, CharSequence replacement)两个方法区别在于第一个只能替换字符串中的一个字符,而第二个重载方法可以替换字符串中一个子串。
String,StringBuffer,StringBuilder都实现了CharSequence 接口,因而replace方法的参数可以是它们三个String类型的任意一个。
String str = "欢迎来到王者荣耀";
str = str.replace("王者荣耀","java的世界");
System.out.println(str);//欢迎来到java的世界
replaceAll()
用法与replace()大同小异,但是它的第一个参数可以传递正则表达式
replaceAll(String regex, String replacement)
regex表示正则表达式
他会替换每一个与正则表达式匹配的子串。
只替换匹配到的第一个子串
同样它的第一个参数也可以是正则表达式
按照给定的表达式将原来的字符串拆分开
limit表示拆分成几段。
String str = "a-b-c-d-f-e";
String [] arr = str.split("-");
for (String v:arr){
System.out.println(v);
}
String = substring(int beginIndex [,int endIndex])
用给定的索引值将当前的字符串截取一部分
从beginIndex开始至endIndex结束 [beginIndex,endIndex)
【注意】:不包含结束位置,截取范围是左闭右开区间。
若endIndex不写 则默认截取到字符串最后。
将全部字符串字母转换成大写
String = toLowerCase()将全部字符串字母转换成小写
String = trim()去掉字符串前后多余的空格,但是不能去掉字符串中的空格。
boolean = matches(String regex)判断当前字符串是否与给定的正则表达式匹配。
regular有规律的 expression表达式
regex 正则表达式
== 与 equals方法的区别==可以比较基本类型 ,也可以比较引用类型比较基本类型的时候比较的是值,比较引用类型的时候比较的是地址
equals只能比较引用类型(方法)
默认比较地址this==obj
如果想要修改其比较规则 可以重写equals方法
通常重写equals方法时会伴随着重写hashCode方法
比如String类 比如Integer *String的不可变特性 String与StringBuffer区别 StringBuffer与StringBuilder区别 String对象的存储
“abc”---->字符串常量池
new String(“abc”)—>堆内存
“a”+“b”+“c”+“d” ; 产生几个对象 *String中常用的方法
作者:发光吖