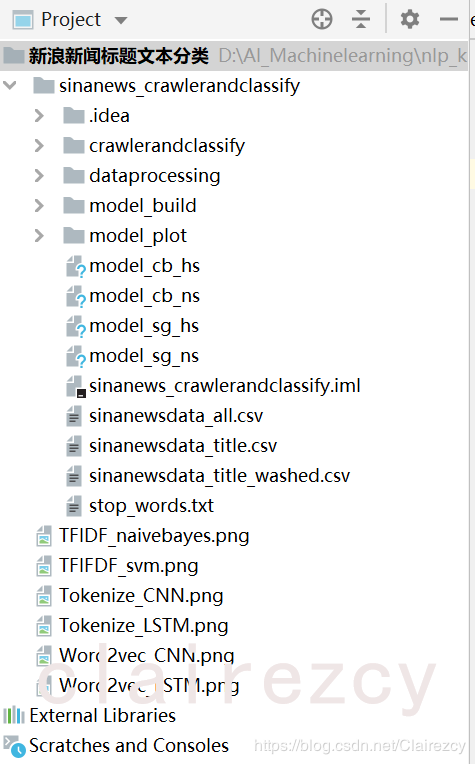
【爬虫+文本分类】--新浪各类新闻标题,并用各类算法进行文本分类
自己设计的小项目,初始想法很简单,检验自己爬虫和nlp基本技能(分词、词向量(tokenize\onehot\tfidf\word2vec))和各类算法(朴素贝叶斯、svm、CNN、LSTM)掌握情况,进一步查漏补缺,提升工程能力和算法应用能力:)
**
**
分析新浪网各类新闻网页结构,应用requests库,爬取并解析新浪各类新闻,包括汽车、教育、金融、娱乐、体育、科技共六类,
对于有“滚动”新闻链接的板块(如sport、tech、entertaimment),通过滚动新闻爬取数据:此类数据多为动态链接,需要异步加载,即自行分析json格式获取其中新闻url
对于没有“滚动”新闻链接的板块(如finance、edu、auto),通过层层解析各层banner,获取最终新闻url
爬取内容包括time,title,source,comments, 爬取后整理为‘title category’格式,每类新闻共爬取3000条标题样本
sinanews_all.py代码如下:
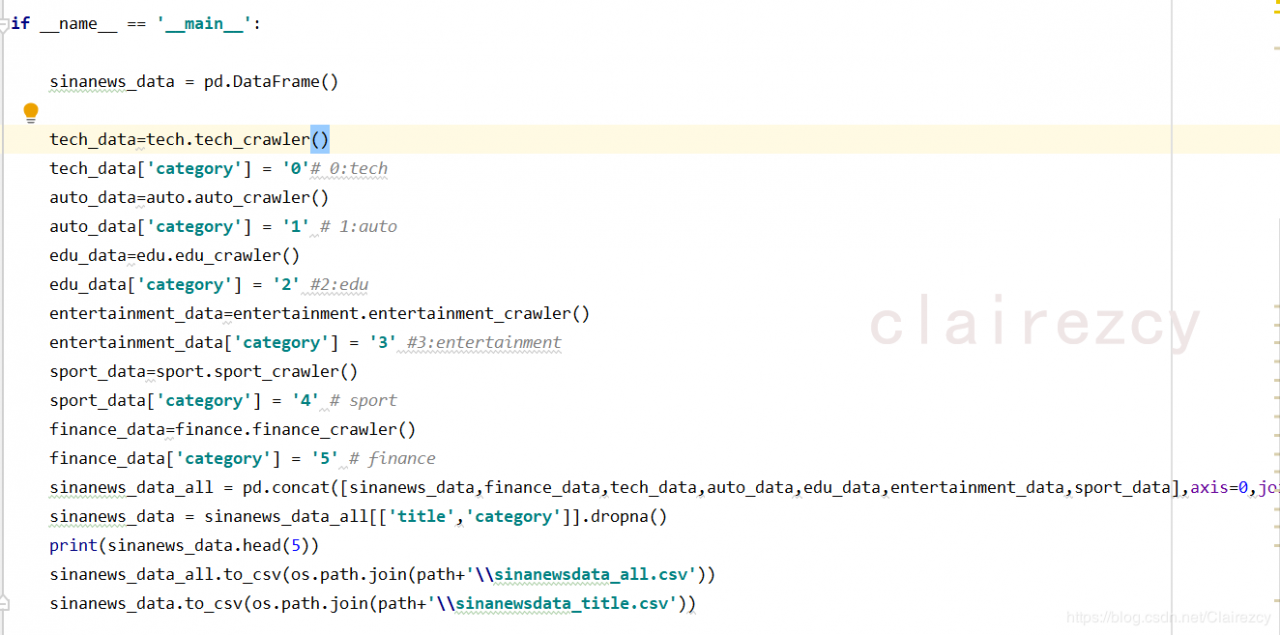
文本如下:

**
**
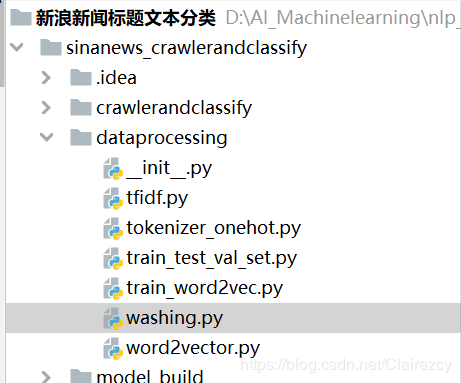 (一)进行数据清洗:
(一)进行数据清洗:
1、删除空行(将空行前后的文本split为两个text,用“,”连接起来);
2、删除乱码和特殊符号;
3、删除英文字符;
4、分词后删除停用词(包括标点符号)
之后进行shuffle,生成最终建模文本:最终样本分布情况如下:
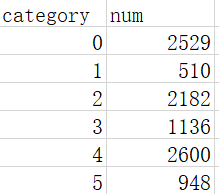
(二)生成各种词向量:关于词向量之间的思考见之前写的文章‘’
1、用sklearn库:
from sklearn.feature_extraction.text import CountVectorizer,TfidfTransformer--------生成tfidf表示的文本标题
2、用keras库:
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences---------生成tokenize表示的文本标题
from keras.utils import to_categorical-------生成onehot表示的文本标题
3、用gensim库:
from gensim.models import word2vec --------以及爬取的文本生成word2vec model
4、人工拆分数据集为训练集(64%)、验证集(16%)和测试集(20%)
**
第三部分:分类算法模型**
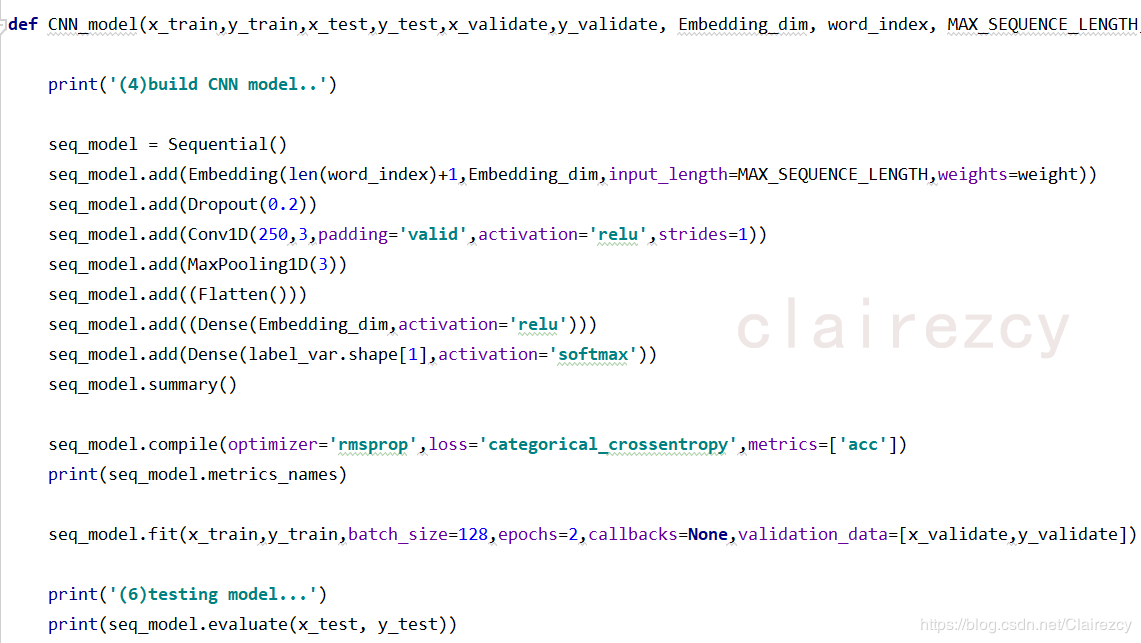
1、CNN:用keras库构建简单的sequential模型(嵌入层-卷积层-池化层-全连接层构成)
2、LSTM(用keras库构建简单的sequential模型(嵌入层-LSTM层-全连接层))

3、朴素贝叶斯(sklearn.naive_bayes)
4、SVM(sklearn.svm)
(此处选择朴素贝叶斯和SVM,没有用softmax和决策树与神经网络进行对比,主要考虑因素是,
1)朴素贝叶斯属于生成式模型,在这种样本量较小的情况下,因该是效果较好的,与其他判别式模型对比,正好看看效果差别,让自己今后选择模型有更直观的认识;
2)在判别式分类模型中,softmax是以线性模型为基础的,因此单个softmax模型对于非线性的分类边界拟合就是一条直线,效果不好;
3)决策树模型的分类边界是与坐标轴平行的,对于与坐标轴不平行的数据类别边界的分类效果不好,或者说对于连续型数据分类效果不如类别型数据效果好,最后对分类边界的拟合是平行于坐标轴的各种十字框,虽然十字框可以对部分非线性进行拟合,但对于大部分非线性边界还是效果不好;
4)SVM是以支持向量为基础,计算与支持向量距离最大的边作为分类边界,不同的核函数可以将分类边界拟合为不同的曲线,因此对非线性边界的拟合效果是最好的,但是比较适合小样本【由于SVM是借助二次规划来求解支持向量,而求解二次规划将涉及m阶矩阵的计算(m为样本的个数),当m数目很大时该矩阵的存储和计算将耗费大量的机器内存和运算时间。】------SVM的数学推导看了很多遍,对算法过程和思想比较理解了,但对数学公式和推导依然晕乎乎,后面有机会再看看,唉)
那么对于神经网络这个非线性拟合高手来说,softmax和决策树太弱了,就让朴素贝叶斯、SVM来与之一决高下吧:)
**
第四部分:不同词向量-不同算法-画图 组合**
对于多分类问题:
1)每一类别的roc曲线:
构建将类别进行二值化(类似onehot)的真实Y值矩阵,即标签矩阵;
根据模型预测得到的预测Y值各类别概率的矩阵;------根据概率矩阵,生成预测Y值对应的二值化矩阵(即将概率最大的类别位置置为1,其他类别对应位置置为0),即预测矩阵
根据各类别的标签矩阵及预测矩阵,可以计算出各个阈值下的假正例率(FPR)和真正例率(TPR),从而绘制出一条ROC曲线,即该类别对应的ROC曲线。
2)总体模型的roc曲线:
方法一:上述N条ROC曲线取平均,即可得到最终的ROC曲线----记为ROC[‘macro’]。
方法二:首先,对于一个测试样本:1)标签只由0和1组成,1的位置表明了它的类别(可对应二分类问题中的‘’正’’),0就表示其他类别(‘’负‘’);2)要是分类器对该测试样本分类正确,则该样本标签中1对应的位置在概率矩阵P中的值是大于0对应的位置的概率值的。基于这两点,将标签矩阵和预测矩阵分别按行平铺展开,转置后形成两列,这就得到了一个二分类的结果。根据这两列直接得到最终的ROC曲线----记为ROC[‘micro’]
各【词向量+模型】分类效果如下:

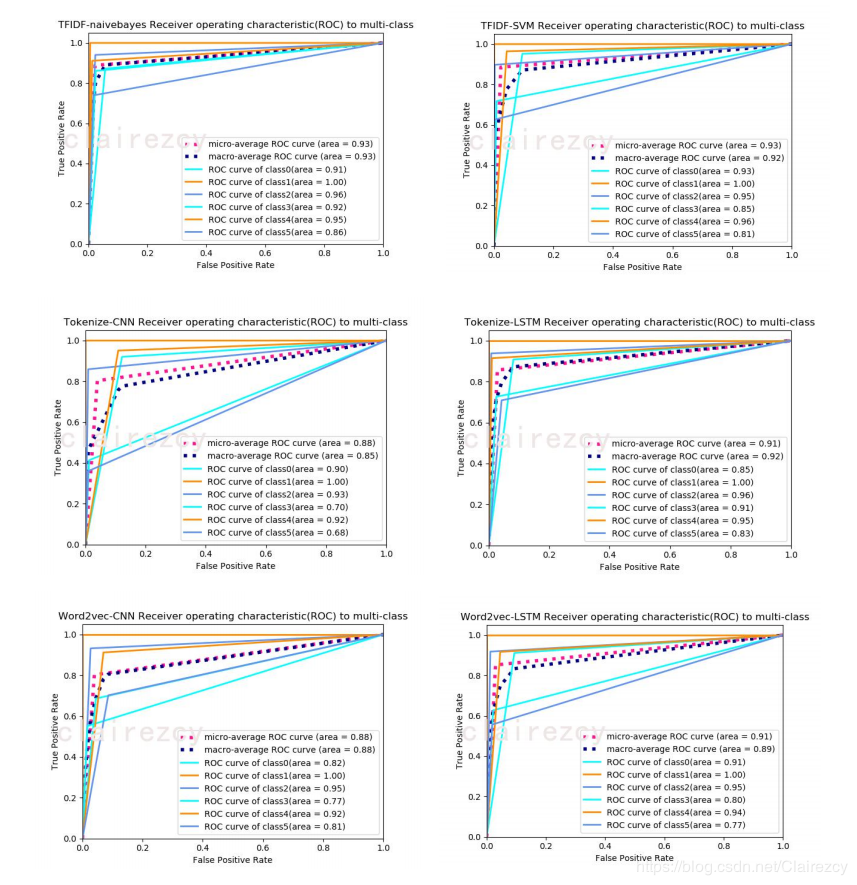
由上面六张roc图可以看出:对于小样本数据:
1)tfidf-朴素贝叶斯,无论是单标签分类还是整体模型,效果都是最好的,其次是tfidf-svm模型,其次是LSTM,最后是CNN
2)由于用目前仅由的样本数据训练的word2vec,效果并没有显现出来,与一般tokenize后embedding的效果相差不大
作者:Clairezcy