PyTorch 深度学习新手入门指南
原标题 | Starter Pack for Deep Learning Projects in PyTorch — for Extreme Beginners — by a beginner!
作 者 | Nikhila Munipalli
翻 译 | 天字一号(郑州大学)、Ryan(西安理工大学)、申影(山东大学)、邺调(江苏科技大学)、Loing(华中科技大学)
审 校 | 唐里、鸢尾、skura
来 源 | AI开发者
欢迎深度学习的学习者,这篇文章是为想开始用pytorch来进行深度学习项目研究的人准备的。预备知识:为了更好的理解这些知识,你需要确定自己满足下面的几点要求:1. 如果在领英上,你也许会说自己是一个深度学习的狂热爱好者,但是你只会用 keras 搭建模型,那么,这篇文章非常适合你。2. 你可能对理解 tensorflow 中的会话,变量和类等有困扰,并且计划转向 pytorch,很好,你来对地方了。3. 如果你能够用 pytorch 构建重要、复杂的模型,并且现在正在找寻一些实现细节,不好意思,你可以直接跳到最后一部分。 让我们开始吧!既然都看到这里了,说明你的确对深度学习有兴趣!老生常谈的话题:什么是 pytorch,它和 keras 之间的区别是什么?初学者很容易通过以下两行指令,通过添加dense层和一些dropouts层去建立一个神经网络:
from keras.models import Sequential from keras.layers import Dense, Dropout就像这样:如果你需要处理 tensor,建立足够复杂的模型,创建一些用户损失函数,或者需要理解在每一层究竟发生了什么,pytorch 这时候可以派上用场了,它是一个对n维数据处理来说绝好的工具,它不仅能够加载大量有用的文档,同时也具备 keras 的简便性。它对初学者非常友好!pytorch 因其出色的调试能力,对多种平台的支持和容易上手而闻名,它并没有涉及到类似keras中的大量计算。
开始设置 步骤1:硬件设置:深度学习模型总是伴随着大量的数据。显然,GPU是必须的。有关cuda和nvidia的设置:请查看:https://missinglink.ai/guides/deep-learning-frameworks/complete-guide-deep-learning-gpus/。 步骤2:安装:Pytorch几分钟就装好了,在他们的官方网站上有一行ctrl+C——ctrl+V。转到他们的网站(https://pytorch.org/),向下滚动,选择你的设置参数,复制该链接并粘贴到你的终端!搞定了!可以准备使用它啦!还可以安装tensorboardX 来显示结果。有关安装的说明,请参阅此 GitHub repo(https://github.com/lanpa/tensorboardX)。步骤3:基本步骤: 这有关于 udemy 的很好的课程,讨论基本的语法,用法和功能。pytorch不需要那么大的努力!它非常类似于Numpy,并且有许多预定义的函数。一旦你开始编码,你就可以发现一些东西。 接下来是有趣的部分! 步骤4:引入必须库:这些是任何模式的深度学习所必需的库。nn模块具有所有必要的损失函数、层数、时序模型、激活函数等。其余部分将随着你的进一步深入而进行讨论。第二个问题: TorchTensor (张量)和 Variable(变量)之间有什么区别? 你一定注意到我们从torch.autograd 导入了Variable库。Tensors只是n维阵列。对于像反向传播的功能,张量必须与它们的关联梯度耦合。对一个 torch Variable 来说也是如此。它是一个具有相应梯度的张量,使得所有张量操作都非常简单!有关详细信息,请查看此q&a(https://discuss.pytorch.org/t/what-is-the-difference-between-tensors-and-variables-in-pytorch/4914)。在所有这些基础上,我们可以开始构建我们的模型了!
模块 1:网络类步骤1:继承。要构建神经网络模型,必须创建继承自 nn.module 的类,其中nn.module 给出了创建自己网络的结构。示例代码如下:class Network(nn.Module): def __init__(self): super(Network, self).__init__()步骤2:网络层。nn.module中定义有不同的网络层,如linear, LSTM, dropout等。如果你习惯Keras顺序模型,nn.sequential就是这样。就个人而言,我不建议使用nn.sequential ,因为它不能发挥出pytorch的真实意图。向模型中添加层的更好方法是用nn创建一个层,并将其分配给网络类的私有成员。示例代码如下:在网络类的init方法中将所有层声明为类变量。步骤3:前向传播函数。这是网络的核心和灵魂。当你调用网络模型进行训练或预测时,都会执行你在forward函数中编写的步骤。因此,我们重写nn.module类中的forward函数,确切地告诉网络模型要做什么。如果forward函数使用了除类变量之外的参数,那每次调用模型时都必须给forward函数传递这些参数。def forward(self,x): out = self.linear1(x) out = self.linear2(out) return out创建了两层的神经网络,传递张量或变量。步骤4:附加函数:通过上述步骤,所有需要做的工作都已经完成了!有时,当模型具有 LSTM 层时,需要初始化隐藏图层的功能。同样,如果你尝试构建玻尔兹曼机时,则需要对隐藏节点和可见节点进行采样。因此,可以在我们的网络类里创建和使用新的成员函数。步骤5:类的参数:使用类构建网络时,请确保使用的是最小值或没有硬编码值。初始化类时,可以忽略学习速率、隐藏图层的大小。如果你成功理解了上述所有步骤,并且能够直观地显示网络,接下来,让我们完成下一个小但重要的功能模块。
模块 2:自定义数据加载器在你的数据上,你是否从头做过训练集、测试集的划分,batch size的设置,shuffles等操作?Keras 具有参数" batchsize",用于处理不规则的batch大小。但是,如果你想在Pytorch中实现它,需要相当多的努力。别担心!自定义数据加载器在这里!DataLoader是一个术语,用于从给定数据中创建训练、测试和验证数据,具有自动批处理大小、随机打乱顺序等功能。pytorch具有默认数据加载器类,可以使用 torch.utils.dataloader 导入该类。这样,你可以直接使你的数据模型!与使用默认数据加载程序相比,根据你的要求很容易构建自定义数据加载器。让我们看看怎么做!你是否还记得importingdata from torch.utils?构建自定义数据加载器非常简单,只需执行以下步骤:第1步:继承 :类似于我们构建网络类是需要继承 nn.Module的,同样我们将继承数据。DataLoader需要继承Dataset类,但可以不必像以前那样调用 init 构造函数,只需要这样:步骤 2:sequences和labels:data.Dataset类具有称为sequences的成员,这些成员 与X 数据或训练数据相对应, labels 与y相对应。你可以创建名为partition的选项,根据该选项将返回其相应的数据。例如:class dataset(data.Dataset): def __init__(self, partition): if partition==’train’: self.sequences = X_train self.labels = y_train步骤3:len 方法:_len_()是一个data.Dataset函数,需要重写才能在我们dataloader中生效,返回的是sequences 的长度。步骤4 :getitem 方法 :__getitem__ (self, index)是在给定索引处返回sequences 和 labels的方法。这个函数也必须重写。步骤5:generators 和 parameterdict:通过上述步骤,创建自定义数据加载器类完成。现在,可以使用它了!数据,由dataloader发送,以generators的形式使用。因此,基于生产的数据,一个参数dict必须创建。包含键:batch_size、shuffle,num_workers。数据加载器类的对象将被实例化,并随参数 dict 一起传递给生成器:params= {‘batch_size’ : 10, ‘shuffle’ : True, ‘num_workers’ : 20} training_set = dataset(X, y, ‘train ) training_generator = torch.utils.data.dataloader(training_set, **params)在官方文件中可以了解更多参数(https://pytorch.org/docs/stable/_modules/torch/utils/data/dataloader.html)。获得数据是不是毫不费力?!如果是,现在,我们有了网络结构和数据,我们的模型已经准备好试验!因此,让我们继续我们的第三个模块!
模块 3:训练函数现在已经分别为网络结构和数据建立了两个类,训练函数的作用就是讲这两个类联系起来,让模型能够学习。步骤1:Parameters(参数) :网络类是最重要的参数。然后才是训练生成器和验证生成器。设置这些必要的参数后,epoch、学习率、batch size、clip、loss等参数可以暂时略过。这些参数不要设置一个固定的值,而作为一个参数变量。步骤2:Initialization (初始化):开始训练需要对网络进行初始化,设置训练模式,如下:损失函数和优化器必须使用nnmodule指定,例如初始化值之后,模型就可以训练了。步骤3:the epoch loop (循环次数):开始进行训练循环,该循环是将数据遍历 n 次。在循环结束时,打印损耗(训练和验证)对应于那个epoch的值。步骤4:TQDM循环:循环可能永远运行!尤其是对于有大量数据的深度学习模型!很难弄清楚里面发生了什么,需要多少时间才能完成。TQDM在这里!它是每个迭代的进度条。看看这里的官方文件。迭代器必须分配给TQDM并在循环中使用。对于每一个时代,我们的函数都在批量大小上迭代。这里的迭代器是训练生成器。TQDM循环如下所示:t = tqdm(iter(training_generator), leave=False, total=len(training_generator)) for i, batch in enumerate(t): x_batch, y_batch = next(iter(training_generator))步骤5:GPU可用性:变量、对象等可以通过一个pytorch命令传输到GPU。包括一行:在代码的开头。0表示要使用的GPU编号。当你觉得有必要把一些变量转移到CUDA时,do:x=x.cuda()。但是,不管底层硬件如何,我们的代码都应该运行。如果GPU不存在,就不能将变量传输到CUDA。代码显示该行中的错误。为了摆脱这些依赖关系,考虑一个变量,它保存了GPU可用性的布尔值。你的代码可以调整成这样:if gpu_available: X= X.cuda()步骤6: 训练过程 :设置必要的东西之后,从网络的结构开始进行训练:这里传递的参数是forward 函数中提到的参数。获得输出后,损失计算为 :反向传播为:loss.backward() optimizer.step()Optimizer.step() 是用来更新参数(权重和偏置),这些参数是基于反向传播的损失计算的。通过tqdm 迭代器可以打印损失值:步骤7: 评估:训练结束后需进行模型评估,模型首先应该设置成评估模式。评估之后,确保模型再设置成训练模式,利用net.train()设置。步骤8: 保存模型和参数:成功训练模型后,需要保存模型和参数以便以后使用,这里有两种方法可以使用。1.torch.save(),用这种方法保存整个模型,包括它的目录结构,使用下列语句2.model.state_dict():state_dict函数只保存了模型中的参数(权重和偏差等等),并没有包含模型的结构。要使用这样方法保存的参数,必须创建模型的结构,构建一个结构类的实例,并指定对于的参数。第三个问题:何时使用torch.save()以及何时使用model.state_dict()?如上所述,torch.save保存整个模型。要加载它,不必实例化网络类。在模型应该在完全不同的平台上工作而不考虑底层代码的情况下,torch.save()是非常有利的。相反,如果你正在执行实验,state_dict()非常有利,因为它只保存模型的参数,并且对于任何进一步的修改都是灵活的。查看这些StackOverflow答案了解更多详细信息。恭喜!如果你做到这一步,你几乎把你的模型建立到完美了!为了组织代码和执行实验,我们来看一个最后的模块。顺便说一句,?这也是最后一个模块啦?!
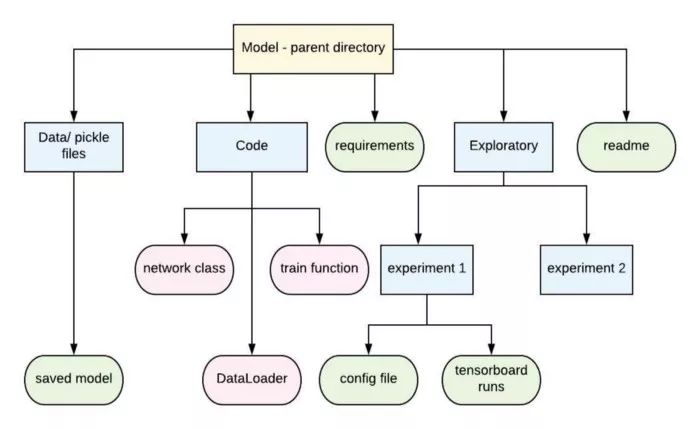
最后:组织在大量的实验中,参数调整通常是在一个深度学习模型上进行的,将它们存储在一个合适的目录结构中是非常重要的。以下是需要遵循的几个步骤:步骤1:配置文件:学习速率、损失函数、周期数等参数都会发生变化。要跟踪所有这些参数,请创建一个配置文件,并包含所有可以使用的参数。在实例化类或调用函数时,你可以将这些变量导入为:并且使用。当必须执行各种尝试和错误方法时,更改配置文件就足够了。步骤2:TensorBoard:还记得从TensorBoardX导入SummaryWriter吗?如前所述,可以用tensorboard 显示损失、精度等。在列车运行前,只需添加一行,即可包含tensorboard :在每个epoch循环中,包括:writer.add_scalar(‘loss’, loss, epoch_number) writer.add_scalar( accuracy , accuracy, epoch_number)你可以使用各种参数添加任意的多个图。在训练函数的结尾,关闭writer请记住更改后面tensorboard 写入的路径,因为图可能被覆盖或重写。步骤 3 :requirements 文件 : 这个东西可能太陈词滥调了,但最好有一个 requirements 文件,其中包含所有库及其版本使用。使用requirements 文件的好处是使用单个命令就可以处理所有依赖项。查看此链接,了解如何冻结所有要求:https://stackoverflow.com/questions/31684375/automatically-create-requirements-txt。第4步:一个readme:经过辛苦的工作之后,你完全有权利吹嘘你的工作,并引导人们使用你的代码!readme 的功能就是这样。通过添加定性和定量的readme来结束你的项目!现在,所有的工作都完成了!!最后,祝贺你成功完成所有四个模块!最后,让我们快速地看一看项目架构:
希望你的项目架构和我们的一样!最后,休息一下,开始建一个网络吧!P.S:感谢 A.ManojGhuhan和Niyati Chhaya的指导并纠正我的错误,使我在这个领域更自信!via https://medium.com/@nikhilamunipalli/starter-pack-for-deep-learning-in-pytorch-for-extreme-beginners-by-a-beginner-330f3fdefcc4封面图来源: https://www.pexels.com/photo/notes-macbook-study-conference-7102/推荐阅读
作者:机器学习算法与Python学习-公众号