HashMap原理分析及性能优化
文章目录一.HashMap是什么二.HashMap继承类对比分析三.HashMap源码相关单词含义四.HashMap如何确定哈希桶数组索引位置五. HashMap 的 put 方法分析六.HashMap扩容机制七.HashMap线程安全性
一.HashMap是什么
HashMap是Java程序员使用频率最高的用于映射(键值对)处理的数据类型。
 ① HashMap :它
① HashMap :它
 注意:
注意:
作者:辰兮要努力
HashMap是一个用于存储Key-Value键值对的集合,每一个键值对也叫做Entry。这些个键值对(Entry)分散存储在一个数组当中,这个数组就是HashMap的主干。
数据结构(JDK1.8):Node[] table; 数组+链表+红黑树
二.HashMap继承类对比分析
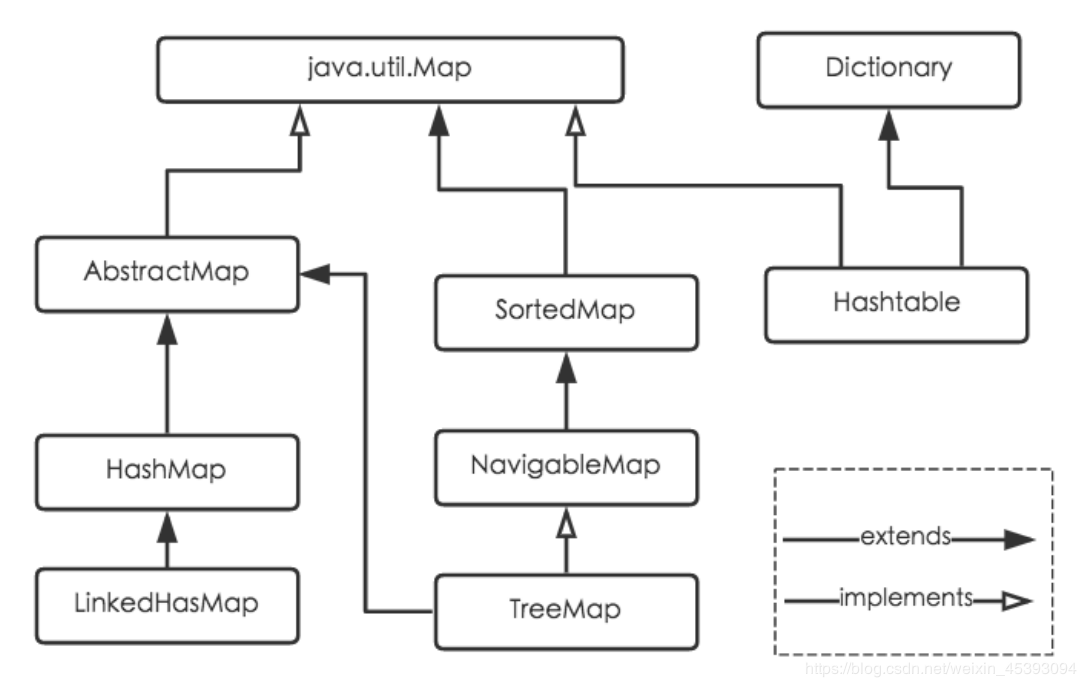
Java为数据结构中的映射定义了一个接口java.util.Map,此接口主要有四个常用的实现类,分别是HashMap、Hashtable、LinkedHashMap和TreeMap,
类继承关系如下图所示:
① HashMap :它根据键的hashCode值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的。 HashMap最多只允许一条记录的键为null,允许多条记录的值为null。HashMap非线程安全,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致。如果需要满足线程安全,可以CollectionssynchronizedMap方法使HashMap具有线程安全的能力,或者使用ConcurrentHashMap。
②Hashtable :Hashtable是遗留类,很多映射的常用功能与HashMap类似,不同的是它承自Dictionary类,并且是线程安全的,任一时间只有一个线程能写Hashtable,并发性不如ConcurrentHashMap,因为ConcurrentHashMap引入了了分段锁。Hashtable不建议在新代码中使⽤用,不需要线程安全的场合可以⽤用HashMap替换,需要线程安全的场合可以用ConcurrentHashMap替换。
③LinkedHashMap :LinkedHashMap是HashMap的一个子类,保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的,也可以在构造时带参数,按照访问次序排序。
④TreeMap :TreeMap实现SortedMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator遍历TreeMap时,得到的记录是排过序的。如果使用排序的映射,建议使用TreeMap。在使用TreeMap时,key必须实现Comparable接口或者在构造TreeMap传入自定义的Comparator,否则会在运行时抛出java.lang.ClassCastException类型的异常。
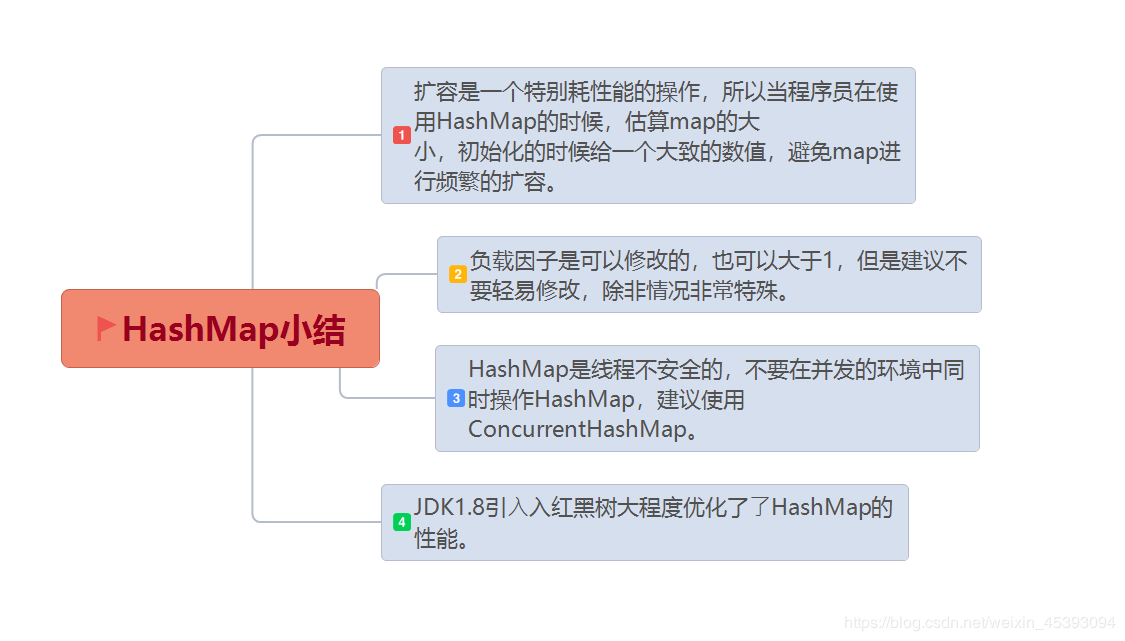
小结:HashMap线程不安全,HashTable安全但是一般不会使用,如果要排序可以使用TreeMap
三.HashMap源码相关单词含义
size,k-v的数量,map集合元素的个数
initialCapacity,初始容量,默认值为16,是一个折中值,不是太小也不是太大
capacity,容量,桶的数量=数组的长度
loadFactor,装载因子=size/ capacity,用来衡量表满的程度,默认为0.75是一个经验值,不会太满,也不会太少
threshold,扩容阀值,当表的size超过threshold时执行扩容操作= capacity * loadFactor
capacity+ loadFactor共同确定了hash表扩容时机
下面功能上会从以下四个方面分析
//⽅法⼀:
static final int hash(Object key) { //jdk1.8 & jdk1.7
int h;
// h = key.hashCode() 为第⼀步 取hashCode值
// h ^ (h >>> 16) 为第⼆步 ⾼位参与运算
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
//⽅法⼆:
static int indexFor(int h, int length) { //jdk1.7的源码,jdk1.8没有这个⽅方法,但是实现原理理⼀样的
return h & (length-1); //第三步 取模运算
}
这里的Hash算法本质上就是三步:取key的hashCode值、高位运算、取模运算
五. HashMap 的 put 方法分析
步骤如图所示
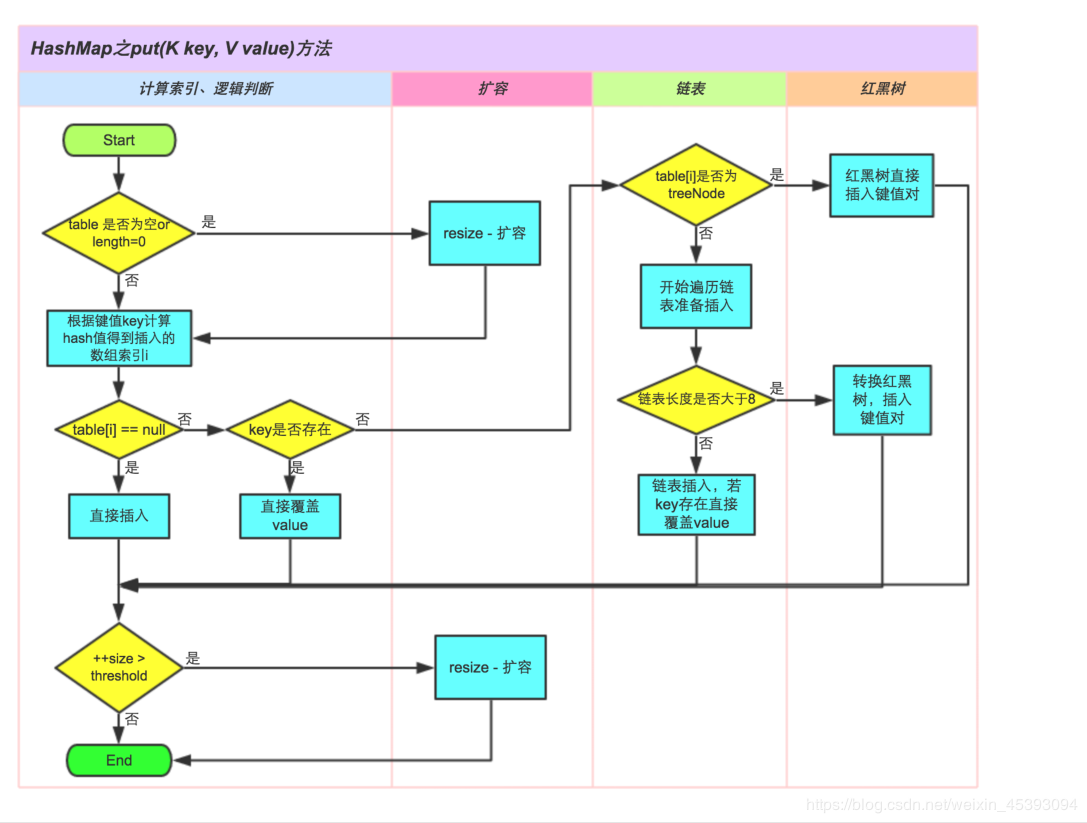
先会根据key的hashcode计算出要存储的位置,如果存储位置相同则会以链表的形式排在其后,如果链表的长度大于8则会转换成红黑树存储,默认数组长度16,加载因子0.75,如果数组存储超过其容量(12)则会自己扩容。
jdk1.8源码分析
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab; Node p; int n, i;
//检查是否需要初始化操作
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//检查是否桶为空[链表为空]
if ((p = tab[i = (n - 1) & hash]) == null)
//直接创建一个新节点
tab[i] = newNode(hash, key, value, null);
else {
Node e; K k;
//p是链表头节点,比较hash同时判断equals
//判断key是否相同,相同则标记e插入操作的表头节点
//hash
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//链表头节点是树结构
else if (p instanceof TreeNode)
//对树结构进行插入操作
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
else {
//hash相同equals不同,执行普通的插入操作
//这里的beancount为链表元素的个数
for (int binCount = 0; ; ++binCount) {
//到达链表尾端
if ((e = p.next) == null) {
//创建新节点
p.next = newNode(hash, key, value, null);
//连表长度满足优化要求
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//找到一个key相同的
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
//继续迭代
p = e;
}
}
//key存在,执行更新操作
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
//修改次数++
++modCount;
//检查是否需要扩容
if (++size > threshold)
resize();
//
afterNodeInsertion(evict);
return null;
}
六.HashMap扩容机制
jdk1.8源码分析
/**
* Initializes or doubles table size. If null, allocates in
* accord with initial capacity target held in field threshold.
* Otherwise, because we are using power-of-two expansion, the
* elements from each bin must either stay at same index, or move
* with a power of two offset in the new table.
*
* @return the table
*/
final Node[] resize() {
Node[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
/*如果旧表的长度不是空*/
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
/*把新表的长度设置为旧表长度的两倍,newCap=2*oldCap*/
else if ((newCap = oldCap << 1) = DEFAULT_INITIAL_CAPACITY)
/*把新表的门限设置为旧表门限的两倍,newThr=oldThr*2*/
newThr = oldThr < 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;//新表长度乘以加载因子
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
/*下面开始构造新表,初始化表中的数据*/
Node[] newTab = (Node[])new Node[newCap];
table = newTab;//把新表赋值给table
if (oldTab != null) {//原表不是空要把原表中数据移动到新表中
/*遍历原来的旧表*/
for (int j = 0; j < oldCap; ++j) {
Node e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)//说明这个node没有链表直接放在新表的e.hash & (newCap - 1)位置
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode)e).split(this, newTab, j, oldCap);
/*如果e后边有链表,到这里表示e后面带着个单链表,需要遍历单链表,将每个结点重*/
else { // preserve order保证顺序
////新计算在新表的位置,并进行搬运
Node loHead = null, loTail = null;
Node hiHead = null, hiTail = null;
Node next;
do {
next = e.next;//记录下一个结点
//新表是旧表的两倍容量,实例上就把单链表拆分为两队,
//e.hash&oldCap为偶数一队,e.hash&oldCap为奇数一对
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {//lo队不为null,放在新表原位置
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {//hi队不为null,放在新表j+oldCap位置
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
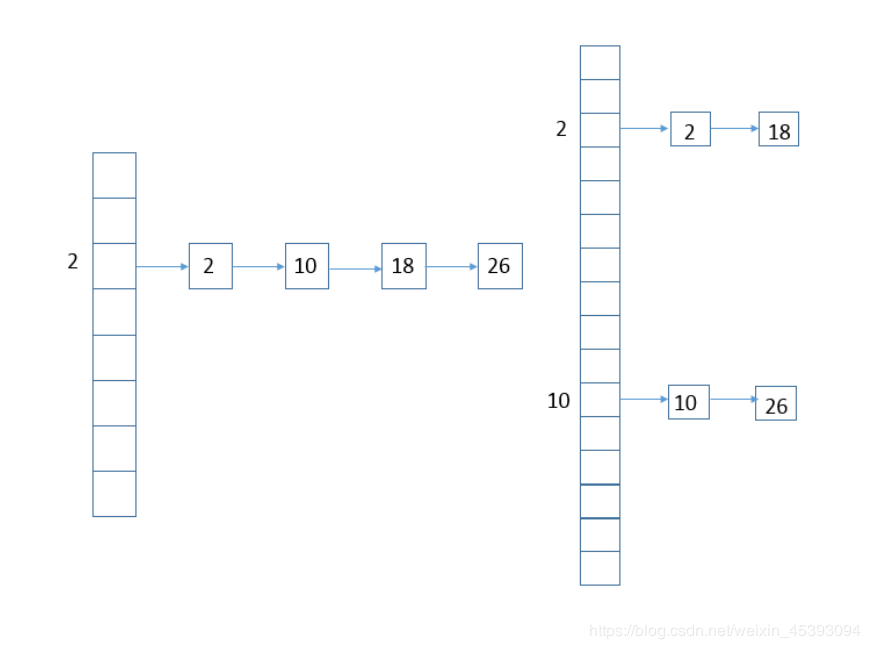
扩容会将原来的链表通过计算e.hash&oldCap==0分成两条链表,再将两条链表散列到新数组的不同位置上
注意: 多线程情况,对hashmap进行put操作会引起resize,并可能会造成数组元素的丢失。
七.HashMap线程安全性
在多线程使用场景中,应该尽量避免使用线程不安全的HashMap,而使用线程安全的ConcurrentHashMap。主要是多线程同时put时,如果同时触发了rehash操作,会导致HashMap中的链表中出现循环节点,进而使得后面get的时候,会死循环。
小结:想要线程安全使用ConcurrentHashMap。
Don’t be afraid to shoot a single horse. What about being alone and brave? You can cry all the way, but you can’t be angry. You have to go through the days when nobody cares about it to welcome applause and flowers.

2020.03.01
作者:辰兮要努力