MySQL查询性能优化索引下推
前言
1. 索引下推的作用
2. 案例实践
3. 索引下推配置
4. 索引下推原理剖析
5. 索引下推应用范围
前言前面已经讲了MySQL的其他查询性能优化方式,没看过可以去了解一下:
MySQL查询性能优化七种方式索引潜水
MySQL查询性能优化武器之链路追踪
今天要讲的是MySQL的另一种查询性能优化方式 — 索引下推(Index Condition Pushdown,简称ICP),是MySQL5.6版本增加的特性。
1. 索引下推的作用主要作用有两个:
减少回表查询的次数
减少存储引擎和MySQL Server层的数据传输量
总之就是了提升MySQL查询性能。
2. 案例实践创建一张用户表,造点数据验证一下:
CREATE TABLE `user` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(100) NOT NULL COMMENT '姓名',
`age` tinyint NOT NULL COMMENT '年龄',
`gender` tinyint NOT NULL COMMENT '性别',
PRIMARY KEY (`id`),
KEY `idx_name_age` (`name`,`age`)
) ENGINE=InnoDB COMMENT='用户表';
在 姓名和年龄 (name,age) 两个字段上创建联合索引。
查询SQL执行计划,验证一下是否用到索引下推:
explain select * from user where name='一灯' and age>2;

执行计划中的Extra列显示了Using index condition,表示用到了索引下推的优化逻辑。
3. 索引下推配置查看索引下推的配置:
show variables like '%optimizer_switch%';
如果输出结果中,显示 index_condition_pushdown=on,表示开启了索引下推。
也可以手动开启索引下推:
set optimizer_switch="index_condition_pushdown=on";
关闭索引下推:
set optimizer_switch="index_condition_pushdown=off";
4. 索引下推原理剖析
索引下推在底层到底是怎么实现的?
是怎么减少了回表的次数?
又减少了存储引擎和MySQL Server层的数据传输量?
在没有使用索引下推的情况,查询过程是这样的:
存储引擎根据where条件中name索引字段,找到符合条件的3个主键ID
然后二次回表查询,根据这3个主键ID去主键索引上找到3个整行记录
把数据返回给MySQL Server层,再根据where中age条件,筛选出符合要求的一行记录
返回给客户端
画两张图,就一目了然了。
下面这张图是回表查询的过程:
先在联合索引上找到name=‘一灯’的3个主键ID
再根据查到3个主键ID,去主键索引上找到3行记录

下面这张图是存储引擎返回给MySQL Server端的处理过程:

我们再看一下在使用索引下推的情况,查询过程是这样的:
存储引擎根据where条件中name索引字段,找到符合条件的3行记录,再用age条件筛选出符合条件一个主键ID
然后二次回表查询,根据这一个主键ID去主键索引上找到该整行记录
把数据返回给MySQL Server层
返回给客户端

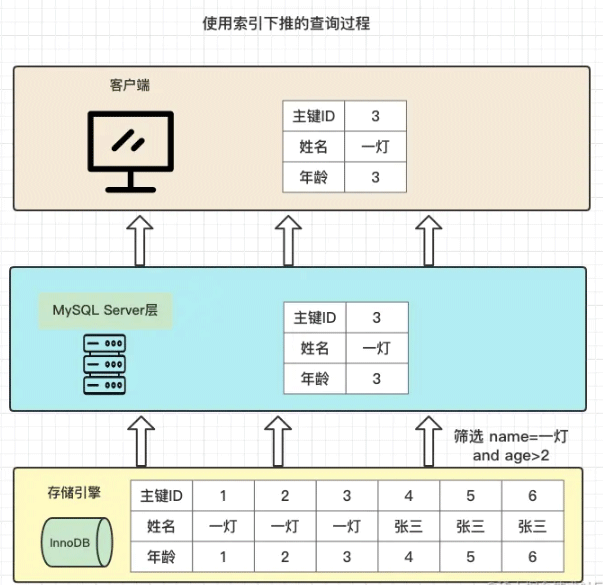
现在是不是理解了索引下推的两个作用:
减少回表查询的次数
减少存储引擎和MySQL Server层的数据传输量
5. 索引下推应用范围适用于InnoDB 引擎和 MyISAM 引擎的查询
适用于执行计划是range, ref, eq_ref, ref_or_null的范围查询
对于InnoDB表,仅用于非聚簇索引。索引下推的目标是减少全行读取次数,从而减少 I/O 操作。对于 InnoDB聚集索引,完整的记录已经读入InnoDB 缓冲区。在这种情况下使用索引下推 不会减少 I/O。
子查询不能使用索引下推
存储过程不能使用索引下推
再附一张Explain执行计划详解图:

到此这篇关于MySQL查询性能优化索引下推的文章就介绍到这了,更多相关MySQL索引下推内容请搜索软件开发网以前的文章或继续浏览下面的相关文章希望大家以后多多支持软件开发网!