学习日记-使用BeautifulSoup爬取小说
半个月前入坑了Python,近几天看到csdn上有一些关于美丽的汤(BeautifulSoup)的介绍和使用方法,于是自己也试着写了一个爬虫。
小白的学习日记,若有不当之处,欢迎大神们指点!
使用python版本:python3.8
随便在网上搜了个小说,试着爬下来。
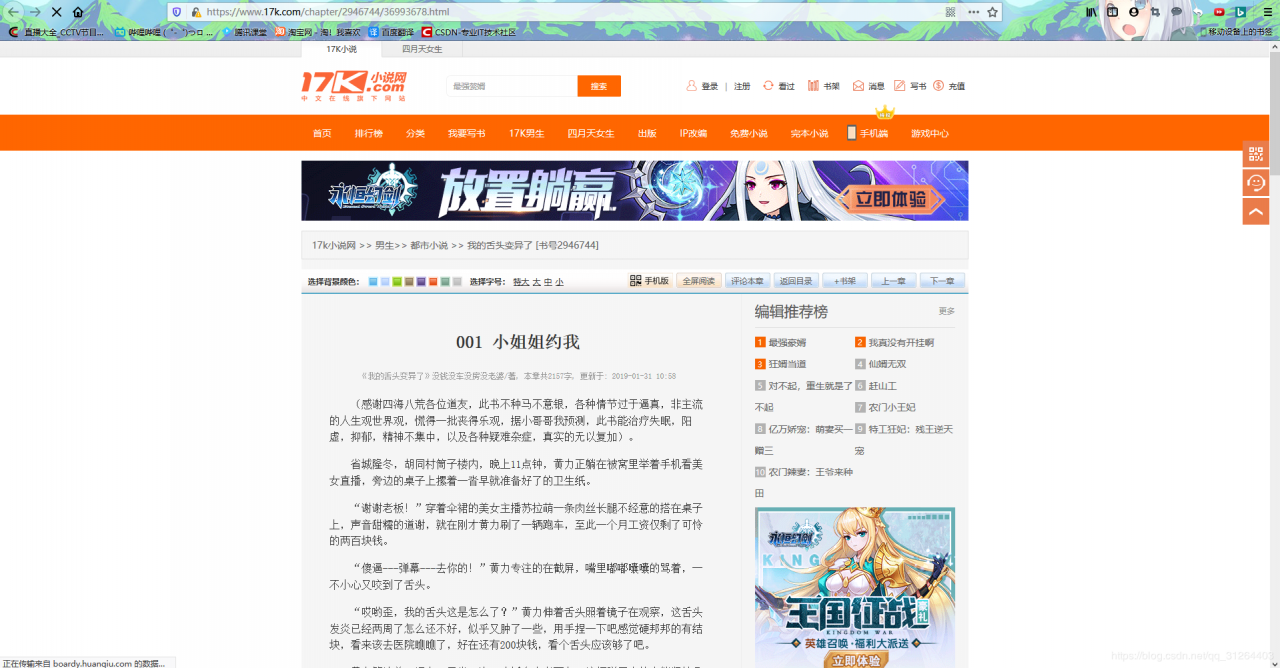
小说链接
# coding=utf-8
#!/usr/bin/env python
from bs4 import BeautifulSoup
import requests
url = 'https://www.17k.com/chapter/2946744/36993678.html'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36'}
查看网页的源代码,发现文章内容都是p标签

但是每一章节的url都是不规律的
第一章

第二章

所以就把思路转向了超链接上
在每一章的末尾都有一个到下一章的超链接

想着用for循环,在每爬完一章节之后获取下一章节的链接
nexturl = soup.find('a',class_='nextChapter').attrs['href']
url = 'https://www.17k.com%s' % (nexturl)
于是乎
#设定需要爬的章数
for i in range(10):
res = requests.get(url, headers=headers)
#强制转码,一开始没有这行代码时输出的小说全是乱码
res = res.content.decode('utf-8')
soup = BeautifulSoup(res,"html.parser")
#找到章节的标题
h1 = soup.find('h1').text
#找到小说的内容
novel = soup.find('div',class_='p')
#过滤div标签中,小说后面的广告
info = [s.extract() for s in novel('div')]
info = [s.extract() for s in novel('p',class_='copy')]
novel = novel.text
print(novel)
接下来就是把小说输入到文本当中去了
f = open('Novel.txt','a',encoding='utf-8')
f.write(h1+novel)
close操作写在for循环之后
f.close()
完整代码(附加了一个计时器,清楚地知道用了多长时间)
# coding=utf-8
#!/usr/bin/env python
from bs4 import BeautifulSoup
import requests
import os
import time
url = 'https://www.17k.com/chapter/2946744/36993678.html'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36'}
print('开始爬取,请等待...')
start = time.time()
#爬100章试试
for i in range(100):
res = requests.get(url, headers=headers)
res = res.content.decode('utf-8')
soup = BeautifulSoup(res,"html.parser")
h1 = soup.find('h1').text
novel = soup.find('div',class_='p')
info = [s.extract() for s in novel('div')]
info = [s.extract() for s in novel('p',class_='copy')]
novel = novel.text
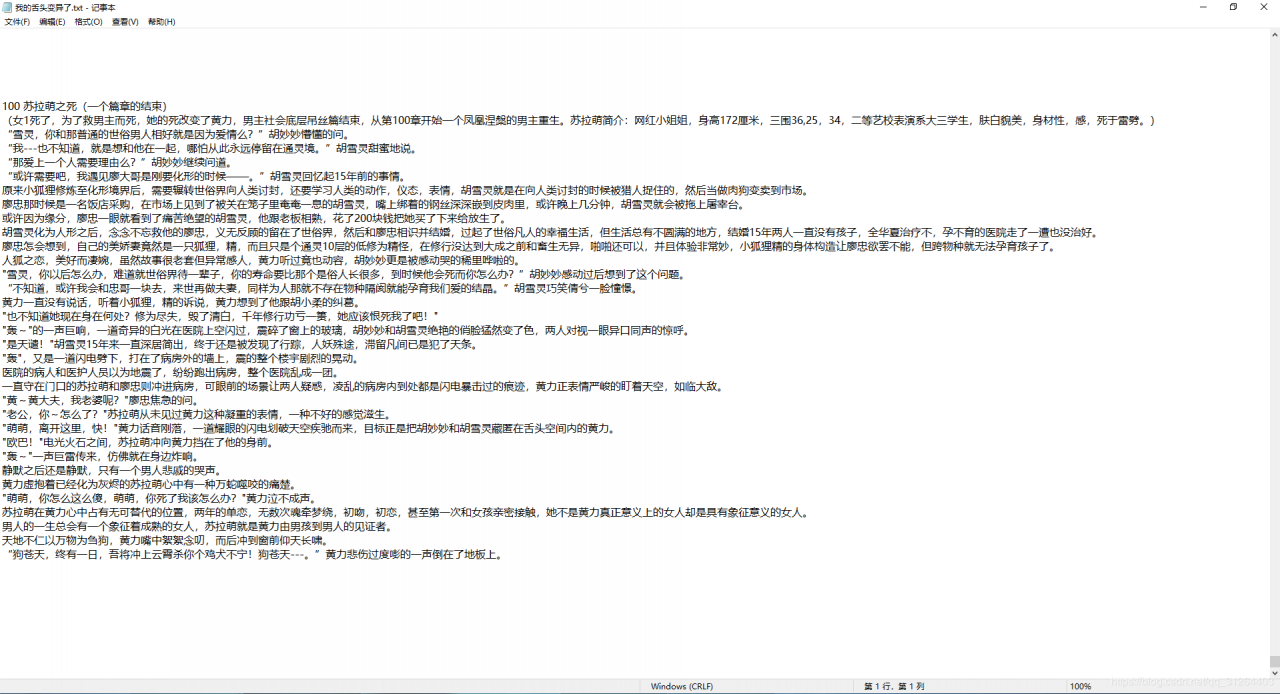
f = open('我的舌头变异了.txt','a',encoding='utf-8')
f.write(h1+novel)
print('第%d章爬取完成!' % (int(i) + 1))
nexturl = soup.find('a',class_='nextChapter').attrs['href']
url = 'https://www.17k.com%s' % (nexturl)
f.close()
end = time.time()
process = end - start
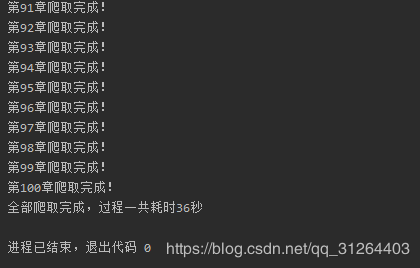
print('全部爬取完成,过程一共耗时%d秒' % (process))
开始运行

结束
效果


作者:Mcdowell160
相关文章
Iris
2021-08-03
Kande
2023-05-13
Ula
2023-05-13
Jacinda
2023-05-13
Winona
2023-05-13
Fawn
2023-05-13
Echo
2023-05-13
Maha
2023-05-13
Kande
2023-05-15
Viridis
2023-05-17
Pandora
2023-07-07
Tallulah
2023-07-17
Janna
2023-07-20
Ophelia
2023-07-20
Natalia
2023-07-20
Irma
2023-07-20
Kirima
2023-07-20