爬取新房销售信息——爬虫篇(requests、bs4(BeautifulSoup4)、csv库)
2020年3月14日
任务介绍此次爬虫任务为“爬取新房销售信息”,获取楼盘名、地址、价格的简单信息,我选取的城市是“赣州”,尝试过安居客、房天下等几个房屋信息网站,安居客有反爬措施,由于是新手比较怂就果断避开了,从信息量来看房天下-赣州符合我的需要,且对新手比较友好,所以选择房天下为对象进行爬虫。
由于信息均为文本,选择保存为csv格式,便于后续读取和分析。
我用的是Anaconda3的环境和PyCharm这种IDE工具,首先需要装载此次任务需要用到的函数库:Requests、bs4(BeautifulSoup4)、csv来实现以下功能:
爬取网页内容; 快速定位并获取想要的文本内容; 保存信息便于数据结果查看和后续分析;有些库Anaconda并没想到我这么快会使用到,没给我预装载。为此,通过Anaconda Prompt这个python环境输入‘pip install [函数库名]’转载所缺的库。

emm,我就是操作演示一下,结果显示这个库我是装好了的。
实操中怎么使用这些强大的函数库呢,用‘import’导入就好了(见下图)。‘as’后面为库名称简写,方便后续调用写起来简单。
import requests as re
from bs4 import BeautifulSoup
import csv
如果为了进一步数据分析,也可以导入pandas这个强大的函数库,本次任务的重点在爬取网页数据,所以暂不使用,爬取数据后做数据分析再行使用。
网页分析进入到所要获取信息的网页,这里我选取的是房天下-赣州-新房的网页,Chrome浏览器通过鼠标右键选择”检查“可以查看网页元素进行分析网页。特别的,如果你想知道价格的位置,直接把鼠标光标移到价格上右键——>检查即可快速定位。
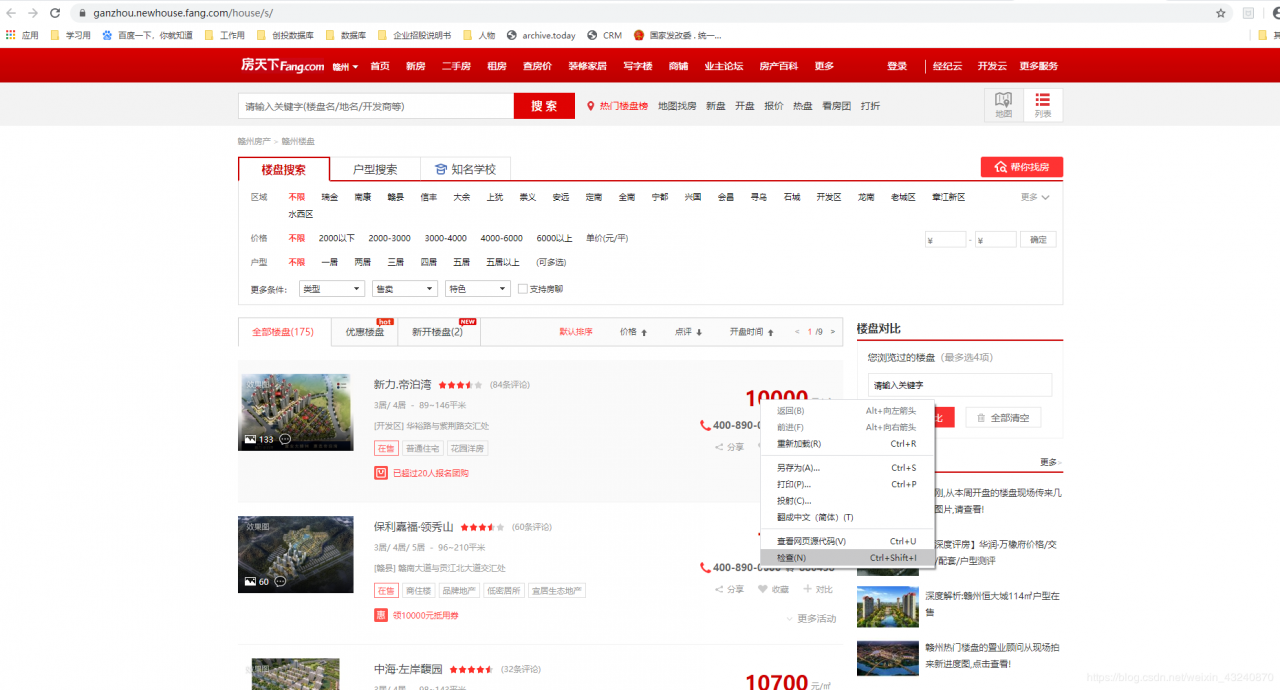
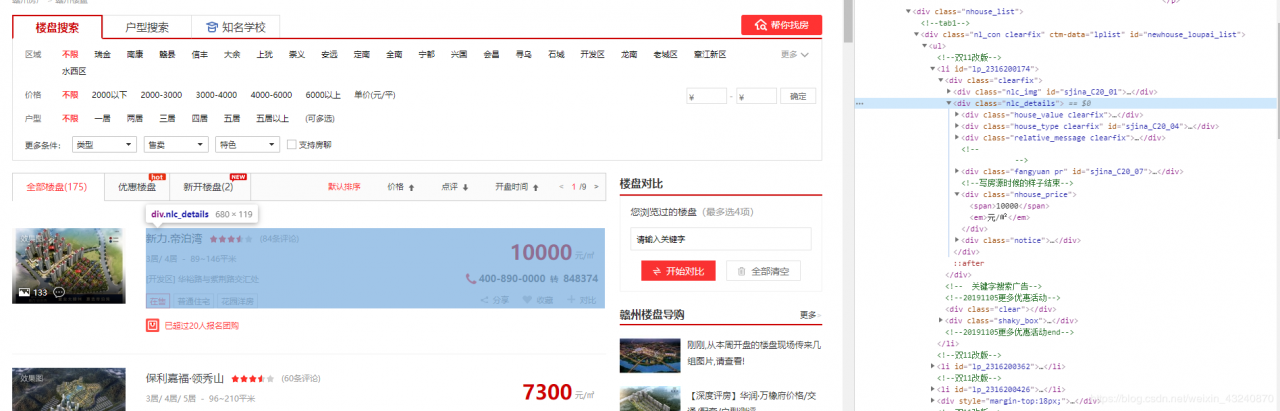
通过审查元素可以发现所需要的楼盘名、地址、价格等信息都在”class“为”nlc_details“的字符串里,为了便于观看,我把需要的信息展开在下面:a为楼盘名,b为楼盘地址,c为楼盘价格。
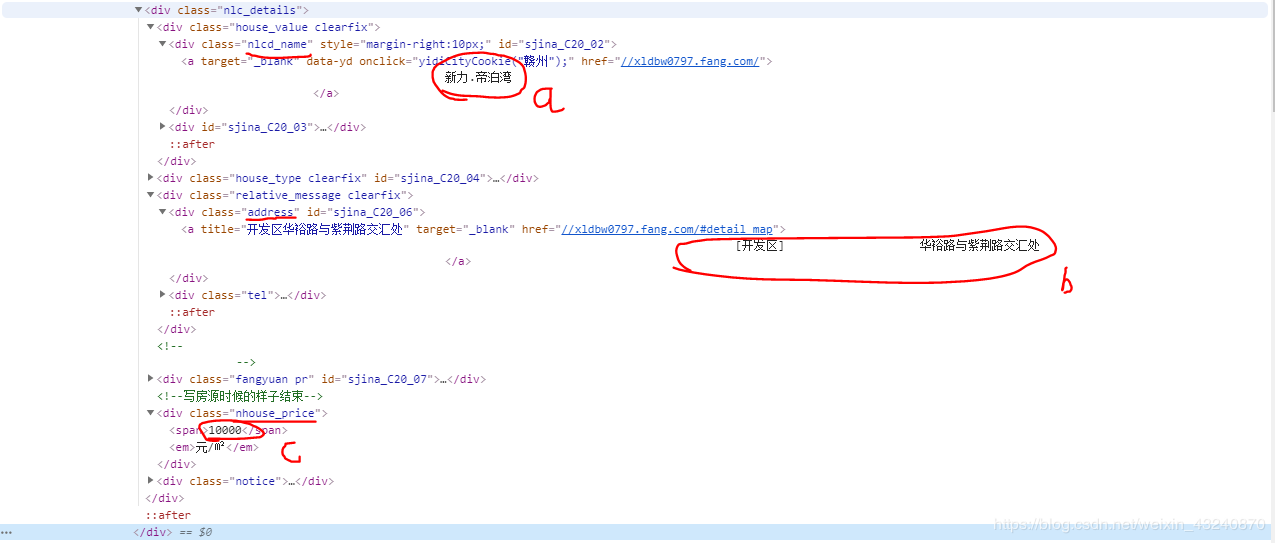
明确这些信息的位置,先用requests获取网页内容,再用BeautifulSoup把网页内容转换成便于分析和获取的文本内容。
不过,同时我发现该网站房屋的信息并不全部显示在一个页面而是多个页面,通过分析不同页面的网址可以发现规律,所以通过循环语句可以简单地实现搜索多个网页。
http://ganzhou.newhouse.fang.com/house/s/b91/ 第一页
http://ganzhou.newhouse.fang.com/house/s/b92/ 第二页
http://ganzhou.newhouse.fang.com/house/s/b93/ 第三页
下面就来实际操作一下吧。
实际操作循环语句前习惯先设置一个空列表,用于放置每一次循环的返回值,for语句设置循环,根据页数设置循环次数。先用requests获取网页内容,再用BeautifulSoup把网页内容转换成便于分析和获取的文本内容。其他见注释。
result_list = []
for i in range(1, 10): # 根据不同页的网址找规律,确定页数
url = "http://ganzhou.newhouse.fang.com/house/s/b9"+str(i)+"/" # 用户自行输入网址
html = re.get(url, timeout=30) # timeout定义等待响应时间,超过30s停止
html.encoding = 'GBK' # 解决中文乱码问题
soup = BeautifulSoup(html.text, 'lxml') # 固定写法
遍历soup查找出类型为’nlc_details‘的内容(即包含名称地址价格的部分),赋值给一个变量 ‘nlc_details’。
nlc_details = soup.find_all('div',class_='nlc_details') # 检查网页元素,确定信息位置
下面整体为一个for循环(在前一个for循环里面执行,需要全体tab一下),遍历’nlc_details’获取所要的名称地址价格信息,其他见注释。
第一次修改:因为价格中很多为“价格待定”,且价格待定时类型不同导致价格会出现缺失值,所以先用if语句判断一下是否有具体的价格,如果有,则进一步获取该楼盘的其他信息
(发完博客后我在做3.0版本的时候发现detail.find(‘div’,{‘class’:’……’}).text 这句就可以获取到所有信息,不会有缺失值,故做修改。)
因为这一篇的任务是爬取新房信息,所以价格暂定的楼盘也包含在内。在下一篇3.0版本中我会把“有具体价格”、“价格暂定有往期价格”、“价格暂定无往期价格”分别做统计,因为要进行数据分析,只有“有具体价格”的才有利于进行进一步分析。
承上特别说明一下,查询房天下网站发现价格信息有三种显示:
1.具体的价格,楼盘在售;如10000元/㎡
2.价格暂定但有往期价格,同一开发商的往期楼盘价格作为参考;如价格暂定往期价格为8300元/㎡
3.价格暂定无往期价格,价格未确定且该开发商无往期楼盘价格参考;一致显示为“价格暂定”。
for detail in nlc_details:
#保证price有值,可以实时获取
if detail.find('元/㎡') != -1: #在字符串中查找子字符串,如果找到返回索引值,如果找不到返回-1
price = detail.find('div',{'class':'nhouse_price'}).text.strip()
name = detail.find('div',{'class':'nlcd_name'}).text.strip()
address = detail.find('div',{'class':'address'}).text.strip().replace('\t','').replace('[','').replace(']','@')
list = address.split('@')
district = list[0]
result_list.append([name,district,address,price])
为保险起见,我增加了一个输出语句用于检查所获取信息是否正确(也可去掉)。
print(result_list)
最后是保存到csv文件中,一般套路,打开文件、写入文件,关闭文件,这里用with语句可以省略掉file.close()语句。
写入csv文件通过csv.writer语句,header为表头,writer.writerow为按行写入,为此用一个for语句遍历result_list(类型为’list’)的每一个元素即每一行(包括名称地址价格信息)。
#写入csv文件
with open('ganzhou_real_estate_current.csv', 'w', encoding='GBK', newline='') as f:
writer = csv.writer(f)
header = ['楼盘名称','区县', '地址', '房价']
writer.writerow(header)
for line in result_list:
writer.writerow(line)
最后,确认没有语法错误,没少括号、标点全为半角后,即可运行输出结果。
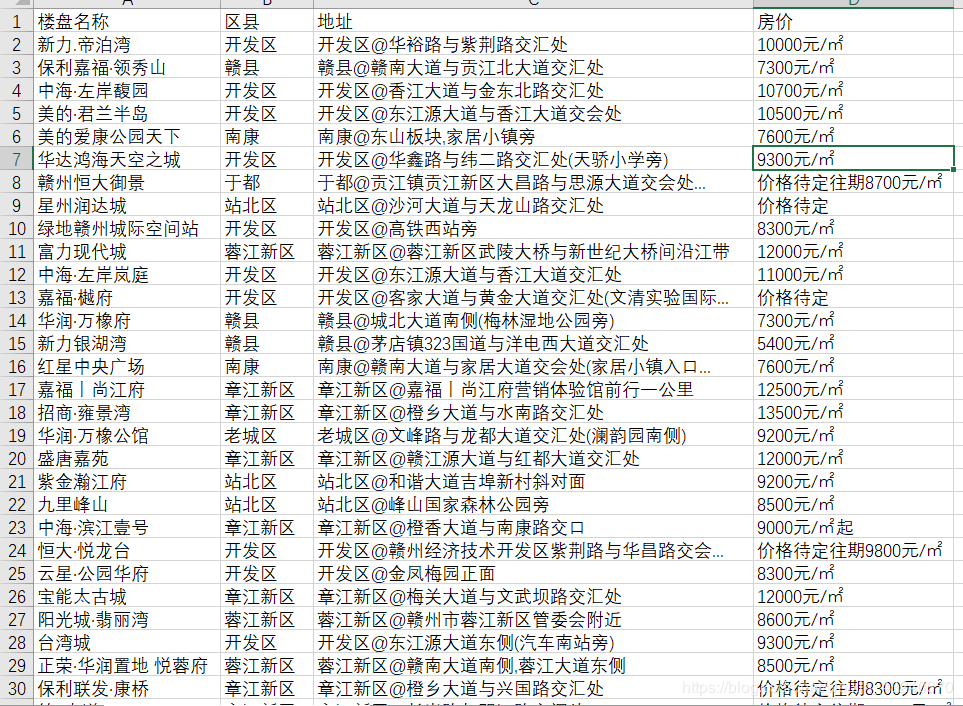
查看结果查看结果如下,爬取成功。
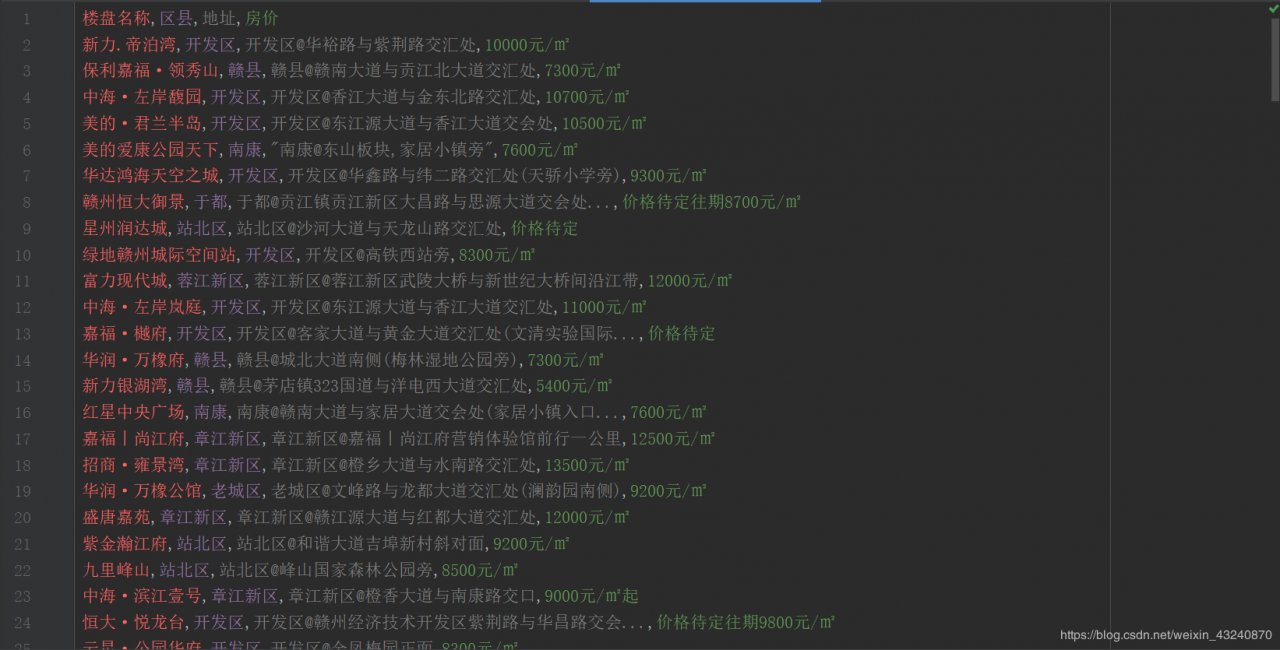
也可通过excel打开:

全部代码见下:
""
作者:Michel
功能:获取房地产价格数据
版本:2.0
日期:2020/3/14
增加功能:实时获取房产信息,无需手动补充缺失值
"""
import requests as re
from bs4 import BeautifulSoup
import csv
#import pandas as pd #输出至csv文件前也可以用pandas包的DataFrame把数据整合为一个表,下面用的是csv包的write函数
result_list = []
for i in range(1, 10): # 根据不同页的网址找规律,确定页数
url = "http://ganzhou.newhouse.fang.com/house/s/b9"+str(i)+"/" # 用户自行输入网址
html = re.get(url, timeout=30) # timeout定义等待响应时间,超过30s停止
html.encoding = 'GBK' # 解决中文乱码问题
soup = BeautifulSoup(html.text, 'lxml') # 固定写法
nlc_details = soup.find_all('div',class_='nlc_details') # 检查网页元素,确定信息位置
for detail in nlc_details: # 遍历列表元素
price = detail.find('div',{'class':'nhouse_price'}).text.strip()
name = detail.find('div',{'class':'nlcd_name'}).text.strip()
address = detail.find('div', {'class':'address'})
# '.text'获取text内容,'.strip'去除前后空行 .text.strip()
# 去掉'\t' .replace('\t','')
# 去掉'[' .replace('[','')
# 去掉']',换成'@',下一步拆分字符串 .replace(']','@')
list = address.split('@') # 拆分字符串,分割为‘区县’+‘地址’
district = list[0] # 获取区县数据
result_list.append([name,district,address,price]) # 把需要的信息合并为列表,叠加
print(result_list)
#写入csv文件
with open('ganzhou_real_estate_current.csv', 'w', encoding='GBK', newline='') as f:
writer = csv.writer(f)
header = ['楼盘名称','区县', '地址', '房价']
writer.writerow(header)
for line in result_list:
writer.writerow(line)
作者:机械键盘让我忍不住敲代码