基于线性回归的广告投入销售额预测
学习机器学习算法最好的方法就是实战,因此笔者将利用网上的数据资源进行实践,并将实现过程与结果记录于博客中,积累实战经验,从今天开始更新。
一般学习的第一个算法模型就是经典线性模型了,因此本文将从经典线性模型开始!
某销售公司为了查找某产品的销售额与电视广告投入、收音机广告投入、报纸广告投入之间的关系,提供了过往历史数据请求进行分析。数据集具体指标说明如下:
TV:在电视上投资的广告费用(以千万元为单位); Radio:在广播媒体上投资的广告费用; Newspaper:用于报纸媒体的广告费用; Sales:对应产品的销量(响应变量)(本文数据来自《Python数据挖掘与机器学习实战》) 导入相关的库
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
读取并查看数据基本情况
data = pd.read_csv('Advertising.csv')
data.head()
输出结果:
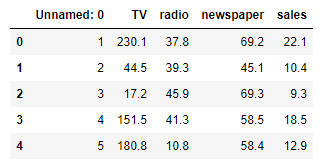
从输出的前5行结果可以看出,第一列为索引列,不纳入数据建模(后续需要去除);数据共4个变量,其中自变量为“TV”、“Radio”、“Newspaper”,因变量为“sales”。
接下来去掉数据集中的索引项
data = data.iloc[:,1:]
data.head()
输出:
data.shape
输出:
(200, 4)
结果表明数据集共4个特征、200条记录。
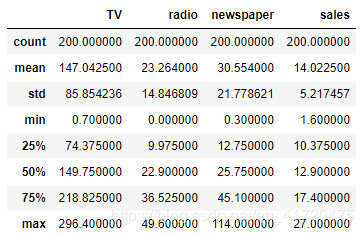
data.describe()
输出:
data.info()
输出:

从输出结果看出,数据集不存在缺失值。
sns.pairplot(data,x_vars = ['TV','radio','newspaper'],y_vars = 'sales',height = 4,aspect = 0.8)
输出:
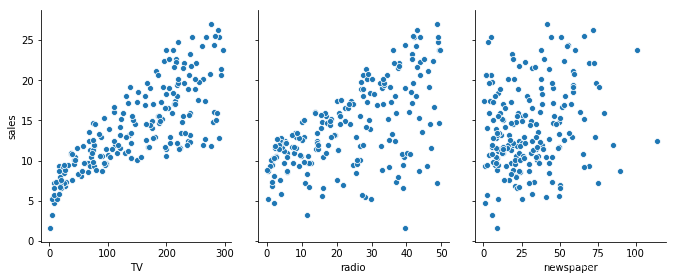
通过绘制每一个维度特征与销售额的散点图,可以大概看出,各种广告投入与销售额成正比。为了进一步查看关系,此处可以设置seaborn的kind参数,添加一条最佳拟合直线和95%的置信带。
#增加参数kind = 'reg'
sns.pairplot(data,x_vars = ['TV','radio','newspaper'],y_vars = 'sales',height = 4,aspect = 0.8,kind = 'reg')
输出:
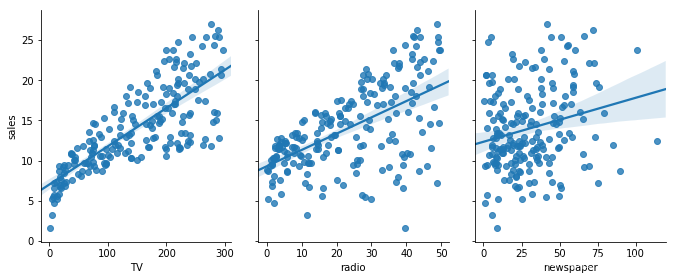
可以看出”TV“、”radio“和”sales“线性关系较强,而”newspaper“和”sales“的线性关系较弱。
同时销售额是连续型数据,适合用线性回归模型进行拟合。
x = data.iloc[:,:3]
y = data.iloc[:,3]
划分训练集和测试集
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size = 0.25,random_state = 0)
模型建立
from sklearn.linear_model import LinearRegression
lm = LinearRegression()
lm.fit(x_train, y_train)
输出:
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)
print(lm.intercept_) #截距
print(lm.coef_) #回归系数
输出:
2.8925700511511483
[0.04416235 0.19900368 0.00116268]
将自变量与对应系数进行打包:
#zip函数为打包函数
#各指标回归系数
feature = ['TV','Radio','Newspaper']
a = zip(feature,lm.coef_)#python2跟python3有变化
for i in a:
print (i)
输出:
(‘TV’, 0.04416234661149288)
(‘Radio’, 0.1990036804039404)
(‘Newspaper’, 0.0011626782879160075)
因此可以得到线性方程为: y = 2.8926 + 0.0442 * TV + 0.1990 * Radio + 0.0012 * Newspaper
查看模型的可决系数R方:
from sklearn.metrics import r2_score
y_pred1 = lm.predict(x_train)
r2_score(y_train, y_pred1)
输出:
0.9072183330817297
R方范围为0~1,越接近1说明模型拟合得越好。
因此结果达到0.9,拟合效果较优。
#测试集上的预测
y_pred2 = lm.predict(x_test)
#可决系数
r2_score(y_test, y_pred2)
输出:
0.8576396745320892
在测试集上的R方也达到0.8以上,结果也较优。
绘制对比曲线
plt.plot(range(len(y_pred2)), y_pred2, color = 'blue', label = 'predict')
plt.plot(range(len(y_pred2)),y_test, color = 'red', label = 'test')
plt.legend(loc = 'upper right')
plt.xlabel("the number of sales")
plt.ylabel("value of sales")
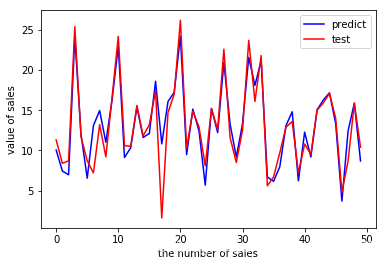
从对比曲线可以看出,两条曲线基本重合!
以上就是基于线性回归的广告投入销售额预测的完整过程。
(本文数据来自《Python数据挖掘与机器学习实战》)
作者:*蓝天翔*