【笔记】吴恩达第二章 单变量线性回归
目录
2.1 模型表示
2.2 代价函数(cost function)
2.3 梯度下降
2.1 模型表示Notation:
m = Number of training examples
x = input variable
y = output variable
(x,y) = one single training example
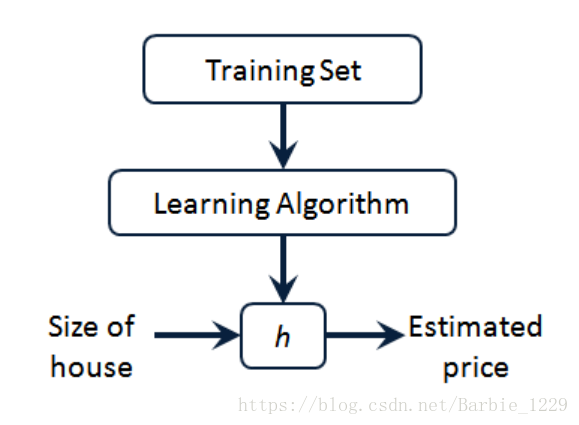
图中h为Hypothesis function:
其中为parameters of model
由训练集通过学习算法得到,我们希望
尽可能地逼近真实值y,即
在样本中,我们选取一个代价函数(cost function,又称square error function 平方误差函数),使得
代价函数的一种取法为最小二乘法,即

目标:得到满足如下要求的
方法之一:梯度下降算法(Gradient descent algorithm)
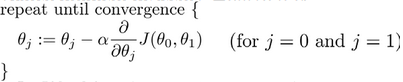
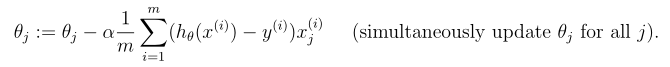
其中,为learning rate,决定每步沿梯度方向下降多少。
作者:KIANDA