文本相似性热度统计算法实现(一)-整句热度统计
软件老王在上一节介绍到相似性热度统计的4个需求(文本相似性热度统计(python版)),根据需求要从不同维度进行统计:
(1)分组不分句热度统计(根据某列首先进行分组,然后再对描述类列进行相似性统计);
(2)分组分句热度统计(根据某列首先进行分组,然后对描述类列按照标点符号进行拆分,然后再对这些句进行热度统计);
(3)整句及分句热度统计;(对描述类列/按标点符号进行分句,进行热度统计)
(4)热词统计(对描述类类进行热词统计,反馈改方式做不不大)
热词统计统计对业务没啥帮助,软件老王就是用了jieba分词,已经包含在其他几个需求中了,不再介绍了,直接介绍整句及分句热度统计,方案包含完整的excel读入,结果写入到excel及导航到明细等。
2.1 完整代码完整代码,有需要的朋友可以直接拿走,不想看代码介绍的,可以直接拿走执行。
import jieba.posseg as pseg
import jieba.analyse
import xlwt
import openpyxl
from gensim import corpora, models, similarities
import re
#停词函数
def StopWordsList(filepath):
wlst = [w.strip() for w in open(filepath, 'r', encoding='utf8').readlines()]
return wlst
def str_to_hex(s):
return ''.join([hex(ord(c)).replace('0x', '') for c in s])
# jieba分词
def seg_sentence(sentence, stop_words):
stop_flag = ['x', 'c', 'u', 'd', 'p', 't', 'uj', 'f', 'r']
sentence_seged = pseg.cut(sentence)
outstr = []
for word, flag in sentence_seged:
if word not in stop_words and flag not in stop_flag:
outstr.append(word)
return outstr
if __name__ == '__main__':
#1 这些是jieba分词的自定义词典,软件老王这里添加的格式行业术语,格式就是文档,一列一个词一行就行了,
# 这个几个词典软件老王就不上传了,可注释掉。
jieba.load_userdict("g1.txt")
jieba.load_userdict("g2.txt")
jieba.load_userdict("g3.txt")
#2 停用词,简单理解就是这次词不分割,这个软件老王找的网上通用的,会提交下。
spPath = 'stop.txt'
stop_words = StopWordsList(spPath)
#3 excel处理
wbk = xlwt.Workbook(encoding='ascii')
sheet = wbk.add_sheet("软件老王sheet") # sheet名称
sheet.write(0, 0, '表头-软件老王1')
sheet.write(0, 1, '表头-软件老王2')
sheet.write(0, 2, '导航-链接到明细sheet表')
wb = openpyxl.load_workbook('软件老王-source.xlsx')
ws = wb.active
col = ws['B']
# 4 相似性处理
rcount = 1
texts = []
orig_txt = []
key_list = []
name_list = []
sheet_list = []
for cell in col:
if cell.value is None:
continue
if not isinstance(cell.value, str):
continue
item = cell.value.strip('\n\r').split('\t') # 制表格切分
string = item[0]
if string is None or len(string) == 0:
continue
else:
textstr = seg_sentence(string, stop_words)
texts.append(textstr)
orig_txt.append(string)
dictionary = corpora.Dictionary(texts)
feature_cnt = len(dictionary.token2id.keys())
corpus = [dictionary.doc2bow(text) for text in texts]
tfidf = models.LsiModel(corpus)
index = similarities.SparseMatrixSimilarity(tfidf[corpus], num_features=feature_cnt)
result_lt = []
word_dict = {}
count =0
for keyword in orig_txt:
count = count+1
print('开始执行,第'+ str(count)+'行')
if keyword in result_lt or keyword is None or len(keyword) == 0:
continue
kw_vector = dictionary.doc2bow(seg_sentence(keyword, stop_words))
sim = index[tfidf[kw_vector]]
result_list = []
for i in range(len(sim)):
if sim[i] > 0.5:
if orig_txt[i] in result_lt and orig_txt[i] not in result_list:
continue
result_list.append(orig_txt[i])
result_lt.append(orig_txt[i])
if len(result_list) >0:
word_dict[keyword] = len(result_list)
if len(result_list) >= 1:
sname = re.sub(u"([^\u4e00-\u9fa5\u0030-\u0039\u0041-\u005a\u0061-\u007a])", "", keyword[0:10])+ '_'\
+ str(len(result_list)+ len(str_to_hex(keyword))) + str_to_hex(keyword)[-5:]
sheet_t = wbk.add_sheet(sname) # Excel单元格名字
for i in range(len(result_list)):
sheet_t.write(i, 0, label=result_list[i])
#5 按照热度排序 -软件老王
with open("rjlw.txt", 'w', encoding='utf-8') as wf2:
orderList = list(word_dict.values())
orderList.sort(reverse=True)
count = len(orderList)
for i in range(count):
for key in word_dict:
if word_dict[key] == orderList[i]:
key_list.append(key)
word_dict[key] = 0
wf2.truncate()
#6 写入目标excel
for i in range(len(key_list)):
sheet.write(i+rcount, 0, label=key_list[i])
sheet.write(i+rcount, 1, label=orderList[i])
if orderList[i] >= 1:
shname = re.sub(u"([^\u4e00-\u9fa5\u0030-\u0039\u0041-\u005a\u0061-\u007a])", "", key_list[i][0:10]) \
+ '_'+ str(orderList[i]+ len(str_to_hex(key_list[i])))+ str_to_hex(key_list[i])[-5:]
link = 'HYPERLINK("#%s!A1";"%s")' % (shname, shname)
sheet.write(i+rcount, 2, xlwt.Formula(link))
rcount = rcount + len(key_list)
key_list = []
orderList = []
texts = []
orig_txt = []
wbk.save('软件老王-target.xls')
2.2 代码说明
(1) #1 以下代码 是jieba分词的自定义词典,软件老王这里添加的格式行业术语,格式就是文档,就一列,一个词一行就行了, 这个几个行业词典软件老王就不上传了,可注释掉。
jieba.load_userdict("g1.txt")
jieba.load_userdict("g2.txt")
jieba.load_userdict("g3.txt")
(2) #2 停用词,简单理解就是这些词不拆分,这个文件软件老王是从网上找的通用的,也可以不用。
spPath = 'stop.txt'
stop_words = StopWordsList(spPath)
(3) #3 excel处理,这里新增了名称为“软件老王sheet”的sheet,表头有三个,分别为“表头-软件老王1”,“表头-软件老王2”,“导航-链接到明细sheet表”,其中“导航-链接到明细sheet表”带超链接,可以导航到明细数据。
wbk = xlwt.Workbook(encoding='ascii')
sheet = wbk.add_sheet("软件老王sheet") # sheet名称
sheet.write(0, 0, '表头-软件老王1')
sheet.write(0, 1, '表头-软件老王2')
sheet.write(0, 2, '导航-链接到明细sheet表')
wb = openpyxl.load_workbook('软件老王-source.xlsx')
ws = wb.active
col = ws['B']
(4)# 4 相似性处理
算法原理在文本相似性热度统计(python版)中有详细说明。
rcount = 1
texts = []
orig_txt = []
key_list = []
name_list = []
sheet_list = []
for cell in col:
if cell.value is None:
continue
if not isinstance(cell.value, str):
continue
item = cell.value.strip('\n\r').split('\t') # 制表格切分
string = item[0]
if string is None or len(string) == 0:
continue
else:
textstr = seg_sentence(string, stop_words)
texts.append(textstr)
orig_txt.append(string)
dictionary = corpora.Dictionary(texts)
feature_cnt = len(dictionary.token2id.keys())
corpus = [dictionary.doc2bow(text) for text in texts]
tfidf = models.LsiModel(corpus)
index = similarities.SparseMatrixSimilarity(tfidf[corpus], num_features=feature_cnt)
result_lt = []
word_dict = {}
count =0
for keyword in orig_txt:
count = count+1
print('开始执行,第'+ str(count)+'行')
if keyword in result_lt or keyword is None or len(keyword) == 0:
continue
kw_vector = dictionary.doc2bow(seg_sentence(keyword, stop_words))
sim = index[tfidf[kw_vector]]
result_list = []
for i in range(len(sim)):
if sim[i] > 0.5:
if orig_txt[i] in result_lt and orig_txt[i] not in result_list:
continue
result_list.append(orig_txt[i])
result_lt.append(orig_txt[i])
if len(result_list) >0:
word_dict[keyword] = len(result_list)
if len(result_list) >= 1:
sname = re.sub(u"([^\u4e00-\u9fa5\u0030-\u0039\u0041-\u005a\u0061-\u007a])", "", keyword[0:10])+ '_'\
+ str(len(result_list)+ len(str_to_hex(keyword))) + str_to_hex(keyword)[-5:]
sheet_t = wbk.add_sheet(sname) # Excel单元格名字
for i in range(len(result_list)):
sheet_t.write(i, 0, label=result_list[i])
(5) #5 按照热度高低排序 -软件老王
with open("rjlw.txt", 'w', encoding='utf-8') as wf2:
orderList = list(word_dict.values())
orderList.sort(reverse=True)
count = len(orderList)
for i in range(count):
for key in word_dict:
if word_dict[key] == orderList[i]:
key_list.append(key)
word_dict[key] = 0
wf2.truncate()
(6) #6 写入目标excel-软件老王
for i in range(len(key_list)):
sheet.write(i+rcount, 0, label=key_list[i])
sheet.write(i+rcount, 1, label=orderList[i])
if orderList[i] >= 1:
shname = re.sub(u"([^\u4e00-\u9fa5\u0030-\u0039\u0041-\u005a\u0061-\u007a])", "", key_list[i][0:10]) \
+ '_'+ str(orderList[i]+ len(str_to_hex(key_list[i])))+ str_to_hex(key_list[i])[-5:]
link = 'HYPERLINK("#%s!A1";"%s")' % (shname, shname)
sheet.write(i+rcount, 2, xlwt.Formula(link))
rcount = rcount + len(key_list)
key_list = []
orderList = []
texts = []
orig_txt = []
wbk.save('软件老王-target.xls')
2.3 效果图
(1)软件老王-source.xlsx

(2)软件老王-target.xls
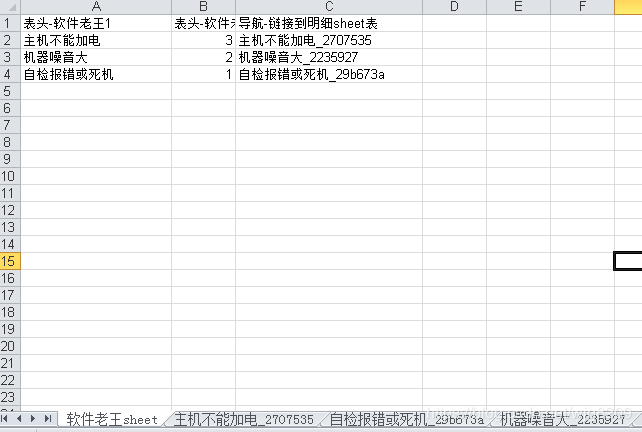
(3)简单说明
真实数据不太方便公布,随意造了几个演示数据说明下效果格式。
I’m 「软件老王」,如果觉得还可以的话,关注下呗,后续更新秒知!欢迎讨论区、同名公众号留言交流!
作者:软件老王