Python之进程+线程+协程(并发与并行、GIL锁、同步锁、死锁、递归锁)
在Python中GIL解释器锁、同步锁、死锁、递归锁都是什么?怎么这么多锁,它们都是用来控制进程、线程的吗?作为一个程序猿,你真的理解并行与并发,同步与异步了么?
希望本篇文章能给你想要的答案… 一、并发与并行
1、并发
一个系统具有处理多个任务的能力,一个CPU可以处理多个任务也叫并发,因为CPU的切换速度极其快
2、并行
一个系统具有 同时 处理多个任务的能力,同时是严格意义上的同时进行
3、区别: 因为一个CPU是可以不断切换任务的,可以实现并发效果,但一个CPU某一个微小的时刻只能正在处理一个任务。
因此,多核的CPU才具有并行的能力,并行是并发的一个子集,并行一定能并发
4、测试代码:
import threading
import time
#定义累加和累乘的函数
def add():
sum1= 0
for i in range(10000):
sum1+= i
print('累加结果:\n',sum1)
def mul():
mul2= 1
for i in range(1,1000):
mul2*= i
print('累乘结果:','\n',mul2)
start= time.time()
#实例化线程对象
t1= threading.Thread(target=add)
t2= threading.Thread(target=mul)
#将每个线程都追加到列表中
l= []
l.append(t1)
l.append(t2)
#初始化每个线程对象
for t in l:
t.start()
#加入join设置
for t in l:
t.join()
print('程序一共运行{}秒'.format(time.time()-start))
二、同步与异步
1、同步
一个进程需要接受外部数据,即执行到一个IO操作(等待外部数据)的时候,程序就一直“等着”,不会往下执行;直到接收到了数据
2、异步
一个进程当执行到一个IO操作时,不会等着,会继续执行后续的操作,某时刻接收到了数据,再返回来处理;很多等待都是没有意义的,因此异步效率更高
概念分析
(1)Cpython用来组织多线程同时运行的一种手段,是Cpython解释器默认的一种设定。也就说明无论我们开启多少个线程,有多少个CPU(或者多核),Python在执行的时候都会在同一时刻只运行一个线程。
(2)之所以加了这个解释器锁,是python的发明者为了维持解释器的稳定运行,但对于用户而言,却是一道障碍,会让我们的进程运行效率不高。
(3)对GIL的精简解释:因为有GIL,所以同一时刻,只有一个线程被CPU执行,导致我们的多核CPU能力无法展现。
(4)但是GIL是无法去除的,只能从其他方面来提高效率,比如多进程+协程,因为我们无法实现一个进程里面跑多个线程,那就直接开多个进程。
任务的分类
(1)IO密集型:需要多次等待外部的数据,所以CPU有非常多的空闲时间,我们就可以利用那些空闲时间来做其他任务,因此有GIL的python适合执行IO密集型的任务,还可以采用多进程+协程来提高效率。
(2)计算密集型:需要连续执行下去不能中断的任务,如计算累乘、计算π的值。
(3)总结:Python的多线程对于IO密集型任务相当有意义,而对于计算密集型的任务则比较低效率,Python不适用。
2、同步锁(1)串行计算:
import threading
import time
#定义累加和累乘的函数
def sub():
global num
temp= num
time.sleep(0.0001)
num= temp-1
start= time.time()
num= 100
l= []
#实例化线程对象
for i in range(100):
t1= threading.Thread(target=sub)
t1.start()
l.append(t1)
#加入join设置
for t in l:
t.join()
print('运行结果:{},程序一共运行{}秒'.format(num,time.time()-start))
(2)串行计算结果:

可以看到从100减去1减了100次计算的结果本应该是0,可这里结果却是56,而且是变化的数字;
原因就是函数执行中途睡了0.001秒,这个时间不长不短,接近CPU在同一个进程中的切换速度;
就使一部分计算切换过去了,一部分计算还保留原来的值,即有些减去了1,有些还没减1线程就被切换走了,导致了结算结果的错误。
(3)处理方法——加一个同步锁:
将CPU锁死,一瞬间只能有一个线程在执行,在这个线程处理完之前都不会让CPU在线程中切换
将函数内容改成以下代码就可以防止串行:
#加一个同步锁
lock= threading.Lock()
#定义累加和累乘的函数
def sub():
#用同步锁将线程锁住
lock.acquire()
global num
temp= num
time.sleep(0.001)
num= temp-1
#释放同步锁
lock.release()
这样改一下,就能得出正确结果0了
3、死锁(1)死锁案例:
import threading
import time
#继承式线程定义
class MyThread(threading.Thread):
#先获得A锁的函数
def actionA(self):
A.acquire() #获得锁
print(self.name,'gotA',time.ctime()) #输出线程名和时间
time.sleep(2)
#在没有释放A锁的情况下再获取B锁
B.acquire()
print(self.name,'gotB',time.ctime())
time.sleep(1)
#释放A锁和B锁
B.release()
A.release()
#先获得B锁的函数
def actionB(self):
B.acquire() #获得锁
print(self.name,'gotB',time.ctime()) #输出线程名和时间
time.sleep(2)
#在没有释放A锁的情况下再获取B锁
A.acquire()
print(self.name,'gotA',time.ctime())
time.sleep(1)
#释放A锁和B锁
A.release()
B.release()
def run(self):
#执行两个动作
self.actionA()
self.actionB()
if __name__ == '__main__':
#创建两个锁
A= threading.Lock()
B= threading.Lock()
L= []
#执行5次实例化对象,但因为死锁,实际只会执行一次
for i in range(5):
t= MyThread()
t.start()
L.append(t)
for i in L:
i.join()
(2)死锁结果:

Thread 1在actionB中将B锁锁住了,没有释放,然后Thread 2将A锁锁住;
之后先释放A锁,但此时进程正处于Thread 2上,该进程上没有A锁,无法释放A锁;
而Thread 1上是B锁,由于Thread 2没有执行完,被锁住的,所以Thread 1上的B锁也不会被释放;
就这样一直僵持着,导致程序只会执行一遍,之后一直处于死锁状态。
4、递归锁(1)递归锁测试:
import threading
import time
#继承式线程定义
class MyThread(threading.Thread):
#先获得A锁的函数
def actionA(self):
r_lock.acquire() #获得锁
print(self.name,'gotA',time.ctime()) #输出线程名和时间
time.sleep(2)
#在没有释放A锁的情况下再获取B锁
r_lock.acquire()
print(self.name,'gotB',time.ctime())
time.sleep(1)
#释放A锁和B锁
r_lock.release()
r_lock.release()
#先获得B锁的函数
def actionB(self):
r_lock.acquire() #获得锁
print(self.name,'gotB',time.ctime()) #输出线程名和时间
time.sleep(2)
#在没有释放A锁的情况下再获取B锁
r_lock.acquire()
print(self.name,'gotA',time.ctime())
time.sleep(1)
#释放A锁和B锁
r_lock.release()
r_lock.release()
def run(self):
#执行两个动作
self.actionA()
self.actionB()
if __name__ == '__main__':
start= time.time()
#创建两个锁
#A= threading.Lock()
#B= threading.Lock()
#创建一个递归锁
r_lock= threading.RLock()
L= []
#执行5次实例化对象,但因为死锁,实际只会执行一次
for i in range(5):
t= MyThread()
t.start()
L.append(t)
for i in L:
i.join()
print('程序一共执行%s秒' %(time.time()-start))
(2)递归锁结果:
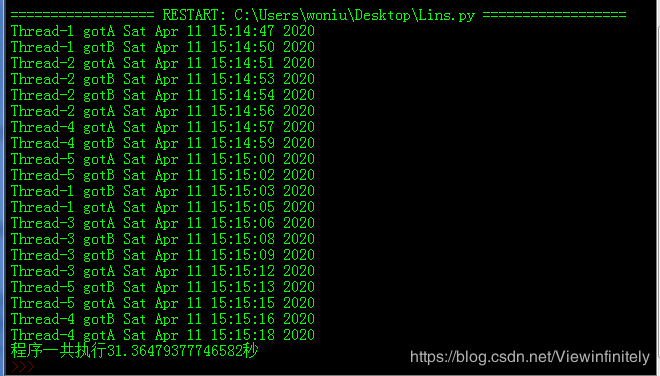
这样它总共会创建5个线程,5个线程接替递归使用,某个进程被占用时就用另外的空闲线程来执行任务,就不会有相互竞争的死锁状态;
就相当于递归锁这一把锁就代表了5把锁,5把锁有空闲的都能用。
作者:栀丶子