Python Opencv 之 使用 teesseract 进行简单的文字识别(包括中文)
目录
Python Opencv 之 使用 teesseract 进行简单的文字识别(包括中文)
一、简单介绍
二、pillow、pytesseract 的安装
1、pip install install 安装 pillow
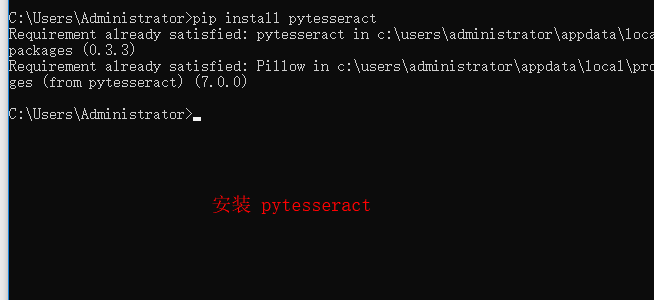
2、pip install pytesseract 安装 pytesseract
三、下载安装需要 pytesseract 需要的 Tesseract-OCR 工具
特别注意:在使用 pytesseract 中,需要配置 Tesseract-OCR,不然使用不了,报错:TesseractNotFoundError
1、到官网下载 Tesseract-OCR 工具,选择自己对应的版本下载即可
2、往下拉找到 Install Tessract via pre-build binary package 进行下载
3、进入 tessdoc 官网,找到对应版本进行下载
4、往下拉,找到自己需要的版本(我这里是windows)
5、Windows 版本的 安装包 https://github.com/UB-Mannheim/tesseract/wiki
6、双击下载包进行安装即可
7、操作很简单,根据步骤操作即可
8、安装的时候,特别记住安装位置即可,后面可能用到
9、配置 tesseract.exe 路径到 pytesseract.py 中
四、代码实现
1、根据以上开始编写代码,打开 Pycharm,新建工程,如下图
2、新建脚本,编辑代码,大概的识别过程
3、准备好一张识别图,运行进行识别
五、关键代码
六、附录中文识别的方法:
1、下载识别中文训练包,可以从下面地址下载
2、把识别中文的训练好的包添加到安装的 Tesseract-OCR\tessdata 目录下
3、在 image_to_string(textImage, lang='chi_sim') 添加 lang='chi_sim'
4、识别结果
一、简单介绍Python是一种跨平台的计算机程序设计语言。是一种面向对象的动态类型语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越多被用于独立的、大型项目的开发。Python是一种解释型脚本语言,可以应用于以下领域: Web 和 Internet开发、科学计算和统计、人工智能、教育、桌面界面开发、软件开发、后端开发、网络爬虫。
本节介绍,通过使用 opencv 和 tesseract 进行简单的文字识别。
二、pillow、pytesseract 的安装 1、pip install install 安装 pillow

2、pip install pytesseract 安装 pytesseract
三、下载安装需要 pytesseract 需要的 Tesseract-OCR 工具 特别注意:在使用 pytesseract 中,需要配置 Tesseract-OCR,不然使用不了,报错:TesseractNotFoundError
pytesseract.pytesseract.TesseractNotFoundError: tesseract is not installed or it's not in your path

1、到官网下载 Tesseract-OCR 工具,选择自己对应的版本下载即可
https://github.com/tesseract-ocr/tesseract/

2、往下拉找到 Install Tessract via pre-build binary package 进行下载
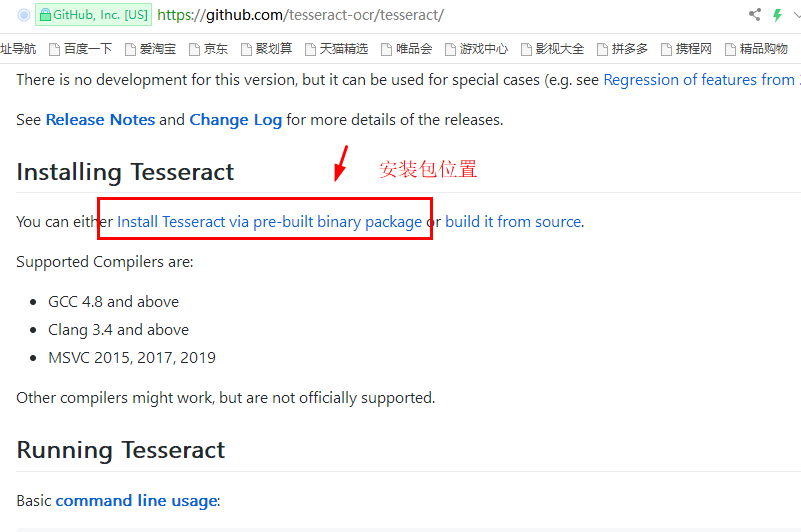
3、进入 tessdoc 官网,找到对应版本进行下载

4、往下拉,找到自己需要的版本(我这里是windows)

5、Windows 版本的 安装包 https://github.com/UB-Mannheim/tesseract/wiki

6、双击下载包进行安装即可


8、安装的时候,特别记住安装位置即可,后面可能用到

9、配置 tesseract.exe 路径到 pytesseract.py 中
1)在 pytesseract 安装路径,找到 pytesseract.py 并打开 找到 "tesseract_cmd" 关键字

2)配置上刚才 tesseract.exe 的安装路径,如下图

四、代码实现 1、根据以上开始编写代码,打开 Pycharm,新建工程,如下图


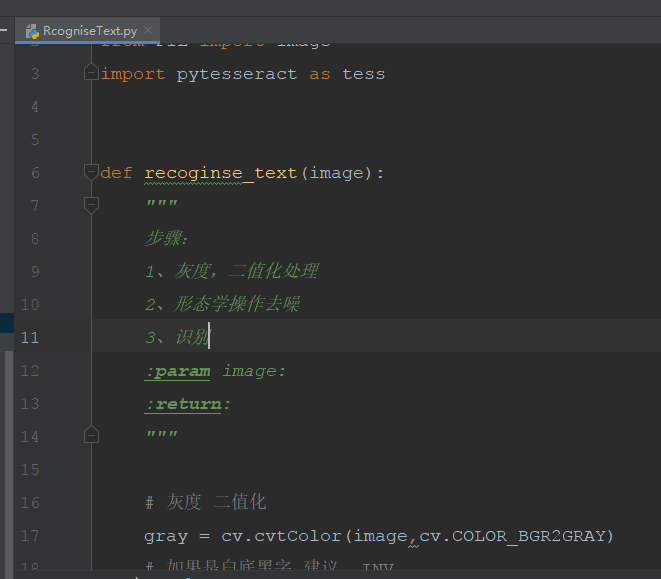
2、新建脚本,编辑代码,大概的识别过程
步骤:1、灰度,二值化处理;2、形态学操作去噪;3、识别;
3、准备好一张识别图,运行进行识别

五、关键代码
import cv2 as cv
from PIL import Image
import pytesseract as tess
def recoginse_text(image):
"""
步骤:
1、灰度,二值化处理
2、形态学操作去噪
3、识别
:param image:
:return:
"""
# 灰度 二值化
gray = cv.cvtColor(image,cv.COLOR_BGR2GRAY)
# 如果是白底黑字 建议 _INV
ret,binary = cv.threshold(gray,0,255,cv.THRESH_BINARY_INV| cv.THRESH_OTSU)
# 形态学操作 (根据需要设置参数(1,2))
kernel = cv.getStructuringElement(cv.MORPH_RECT,(1,2)) #去除横向细线
morph1 = cv.morphologyEx(binary,cv.MORPH_OPEN,kernel)
kernel = cv.getStructuringElement(cv.MORPH_RECT, (2, 1)) #去除纵向细线
morph2 = cv.morphologyEx(morph1,cv.MORPH_OPEN,kernel)
cv.imshow("Morph",morph2)
# 黑底白字取非,变为白底黑字(便于pytesseract 识别)
cv.bitwise_not(morph2,morph2)
textImage = Image.fromarray(morph2)
# 图片转文字
text=tess.image_to_string(textImage)
print("识别结果:%s"%text)
def main():
# 读取需要识别的数字字母图片,并显示读到的原图
src = cv.imread("RecogniseText_03.jpg")
cv.imshow("src",src)
# 识别
recoginse_text(src)
cv.waitKey(0)
cv.destroyAllWindows()
if __name__=="__main__":
main()
六、附录中文识别的方法:
1、下载识别中文训练包,可以从下面地址下载
百度网盘自取密码 v13f
2、把识别中文的训练好的包添加到安装的 Tesseract-OCR\tessdata 目录下

3、在 image_to_string(textImage, lang='chi_sim') 添加 lang='chi_sim'
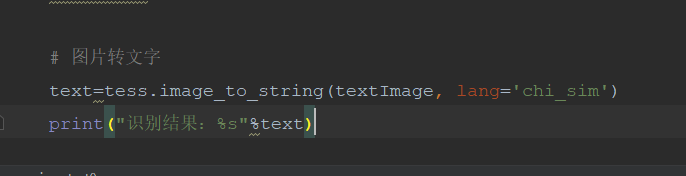
4、识别结果

作者:仙魁XAN