Scrapy爬虫项目——阿里文学当当网
创建项目命令:
scrapy startproject [项目名]


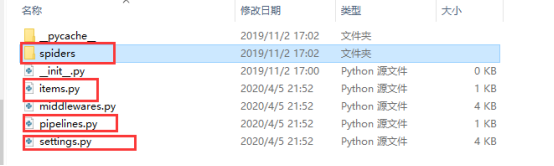
Items定义要爬取的东西;spiders文件夹下可以放多个爬虫文件;pipelines爬虫后处理的文件,例如爬取的信息要写入数据库;settings项目设置
2. Scrapy常用模板Scrapy-般通过指令管理爬虫项目,常用的指令有:
(1) startproject创建爬虫项目

basic基础模板(最常用);crawl通用爬虫模板;csvfeed爬取csv格式的模板;xmlfeed爬取xml格式的模板
(2) genspider -I查看爬虫模板

(3)genspider -t模版爬虫文件名域名创建爬虫
(4)crawl运行爬虫
(5)list查看有哪些爬虫
3. Scrapy爬虫编写基础编写一个Scrapy爬虫项目,一般按照如下流程进行:
(1) 创建爬虫项目
(2) 编写items
(3) 创建爬虫文件
(4) 编写爬虫文件
(5) 编写pipelines
(6) 配置settings
4. 使用scrapy编写阿里文学数据 第一步:定义目标在items中定义目标


yield这里转交给pipelines文件处理
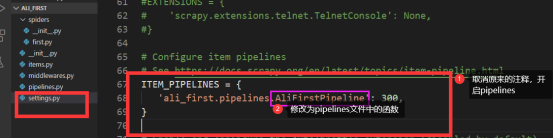
纠正一下:图中第①点我的目录应该是ali_first
(运行之后报错才发现,这个笔记是边做项目边写的,懒得重新截图编辑了)
第三步:开启pipelines修改settings文件

目标站点:当当(http://category.dangdang.com/pg1-cp01.54.06.00.00.00.html)
需求数据:商品标题、链接评论数等数据
要求:自动翻页并自动写入数据库
对比翻页链接:http://category.dangdang.com/pg1-cp01.54.06.00.00.00.html
http://category.dangdang.com/pg2-cp01.54.06.00.00.00.html
第一步:items文件定义目标
# -*- coding: utf-8 -*-
import scrapy
from dangdang_sed.items import DangdangSedItem
from scrapy.http import Request
class FirstSpider(scrapy.Spider):
name = 'first'
allowed_domains = ['category.dangdang.com']
start_urls = ['http://category.dangdang.com/pg1-cp01.54.06.00.00.00.html/']
def parse(self, response):
item = DangdangSedItem() # 创建对象
# 获取数据
item["title"] = response.xpath('//a[@name="itemlist-title"]/@title').extract()
item["href"] = response.xpath('//a[@name="itemlist-title"]/@href').extract()
item["comment"] = response.xpath('//a[@name="itemlist-review"]/text()').extract()
# print('书名:\n'+str(item["title"]))
# print(item["title"])
yield item
# 翻页
for i in range(0,10):
url = "http://category.dangdang.com/pg"+str(i+2)+"-cp01.54.06.00.00.00.html"
yield Request(url,callback = self.parse)
第三步:开启pipelines
修改settings文件
ITEM_PIPELINES = {
'dangdang_sed.pipelines.DangdangSedPipeline': 300,
}
第四步:下载pymysql
使用命令:pip install pymysql
异常:

根据提示输入命令更新pip安装包:
python -m pip install --upgrade pip
再次出现异常,更新失败:

通过百度看到更新方法:
python -m pip install --upgrade pip -i https://pypi.douban.com/simple

再次下载安装pymysql库
修改pymysql设置
(1)找到pymysql路径下的connections.pyi文件

(2)修改connections.pyi文件中的charset值,避免出现乱码问题

第五步:准备数据库
这里用vavicat for mysql工具创建数据库和数据表
数据库:dangdang 数据表:boods

在mysql命令窗口中通过密码登录,查看数据库可以看到刚才创建的数据库dangdang

第六步:完善pipelines文件内容

第七步:运行爬虫文件并查看数据库存储结果
运行first.py文件,同时查看数据库中是否有数据插入

通过vavicat for mysql工具查看dangdang数据库的boods表格数据

作者:Python新手上路