关系抽取论文整理——早期文献
阅读资源:SVM中的核方法
Dependency Tree Kernels for Relation Extraction
思路:将句子转化为句法依赖树,构建增强依存树(Augmented Dependency Trees),得到一个句子和两个实体的各种特征,定义相应的核函数,计算不同树之间的相似度,最后用SVM进行分类。这种方法的缺点就是很依赖增强依存树的结果。
理由在于依赖树包含了句子中不同成分语法的依赖关系,作者认为具有相似关系的实例也会在其对应的依赖树上有相似的结构。核函数的目的就是找到依赖树之间的相似性。因此,再找到之后,只需将核函数并入SVM中,即可。
实验部分:
使用ACE数据集【只用到其中5个关系,没有用24个】
在SVM中使用不同的核,
K 0 = sparse kernel
K 1 = contiguous kernel
K 2 = bag-of-words kernel
K 3 = K 0 + K 2
K 4 = K 1 + K2
先用二分类的SVM进行关系检测:实体间是否存在关系,再用Libsvm进行关系分类。
进行二分类检测的理由:
Detecting relations is a difficult task for a kernel method because the set of all non-relation instances is extremely heterogeneous, and is therefore difficult to characterize with a similarity metric.
A Shortest Path Dependency Kernel for Relation Extraction
在dependency tree的基础上,任务句子中有很多不必要的信息,有人提出最小树的方法,这边作者寻找最短路径的方法来解决。
具体做法:将一个句子构建成一个图,其中单词作为图的节点,依存关系作为图的边。这样我们可以得到两个实体的最短路径,对这个最短路径上的节点的单词、词性、实体类别等特征进行组合就得到了最终特征,最后使用核方法和SVM进行关系分类。
评价:创新点在于求依存关系的最短路径,这跟我们人类推理关系是类似的。缺点就是仍然依赖与所使用的NLP工具的质量,这会影响到模型的准确率。
Exploring Various Knowledge in Relation Extraction本文研究了基于SVM的基于特征的关系抽取中的词汇、句法和语义知识的融合。研究表明,chunking方法对于关系抽取非常有效,并且在句法方面有助于大部分性能的提高,而来自完全句法分析的附加信息对于模型表现增强由局限性。因此,作者认为(在实验中证实),用于关系提取的完整解析树中的大多数有用信息都是浅层的,可以通过分块来捕获。
实验部分:使用ACE数据集,对其中6个大类(24个子类)建模,因为考虑到m1-m2,m2-m1属于两类,(除了6个对称的关系【“RelativeLocation”, “Associate”, “Other-Relative”, “OtherProfessional”, “Sibling”, and “Spouse”.】),还有一个无的类别,所以总共43的类别,建立一个多分类的模型。
关键结论:
Dependency tree 与 parse tree 对模型的提升有限,原因在于:ACE预料中关系间隔较短,70%以上实体之间的间隔只有一个词。依赖树和解析树特征只能在剩余的远距离关系中发挥作用。然而,尽管我们系统中使用的Collins解析器代表了完全解析的最新技术,但完全解析总是容易出现长距离错误。 某些关系检测与分类会较为困难,比如AT型及其子类的关系。 加入了chunking的结果后,基于特征的方法明显优于核方法。这表明基于特征的方法可以有效地结合来自不同来源(如WordNet和gazetters)的不同特征,从而对关系抽取产生影响。 在误差分布的分析中,结果表明,73%(627/864)的错误源于关系检测,27%(237/864)的错误源于关系表征,其中17.8%(154/864)的错误源于关系类型间的误分类,9.6%(83/864)的错误源于同一关系类型内关系子类的误分类。这说明关系检测是关系抽取的关键。阅读:chunking(组块分析)
远程监督阅读:
远程监督关系抽取论文总结 多示例多标签学习 深度学习中的MIML Distant supervision for relation extraction without labeled data 核心思想:如果一个句子中两个实体存在某种关系,那么其他句子中的这两个实体也很可能在表达这种关系。 在文章中,作者发现基于连续组块的句法特征有较好的表现,有助于远程监督的信息提取。作者使用的是连接特征的办法(词汇句法特征连接起来,没有独立使用,【得益于大样本】)。 因此,就可以在数据库中使用已有的关系,找到大量的实体对,从而找到对应句子标注相应关系。再提取这些句子的词汇、句法、语义特征进行训练,得到关系抽取的模型。而负样本使用随机实体对进行标注。通过这种策略生成训练样本,减少标注,然后再设计特征,训练关系分类器。 优点:可以使用大的数据集,不会过拟合,且相比于无监督学习,得到的关系是确定的。 问题:第一个是假设过于肯定,有时候两个实体一起出现,但并没有表达知识库定义的关系。也有可能两个实体之间存在多种类型关系,那么就无法判断这一个句子中所说的是哪一种关系;另外这种标注方式依赖于NER的性能。【NLP工具】 未来的工作:更简单的、基于chunker的语法特征能否在不增加完全解析开销的情况下得到足够的信息,提高性能。Multi-instance Multi-label Learning for Relation Extraction
这篇文章主要是解决远程监督论文所提到的第一个问题。实体间不止存在一种关系,比如中国-北京。可能是北京在中国,也可能北京是中国首都,也可能是北京面积比中国小。也就是不同句子,可以提取出同一实体,表达不同关系。所以,作者提出用多示例多标签学习来解决这一问题。
这是文章中给出的多示例多标签学习的简单图示:
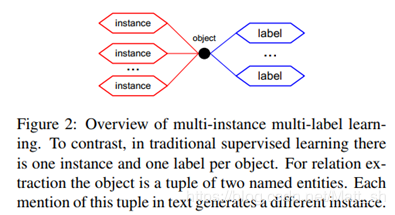
文章使用具有隐变量的图模型共同对文本中一对实体的所有实例及其所有标签进行建模,然后使用EM算法求解该模型。
关于EM算法,看这个:EM算法解读
关于Schemas的总结
**思路**:本文提出的是通用schema的方法,选择利用开放关系抽取方法获得的关系以及现有数据库中存在的关系,构成一个二维的矩阵。**行**是实体对(来源于现存的数据库以及抽取的文本语料),而**列**对应到到固定Schema关系和开放域关系的连接。矩阵每个元素的值(训练集是0,1),希望能够对于缺失部分进行预测,(测试集给出的是概率形式),所以可以将**行**理解为**用户**,**列**理解为**物品**,类似于协同过滤的方法来解决这个问题。
**模型形式**:
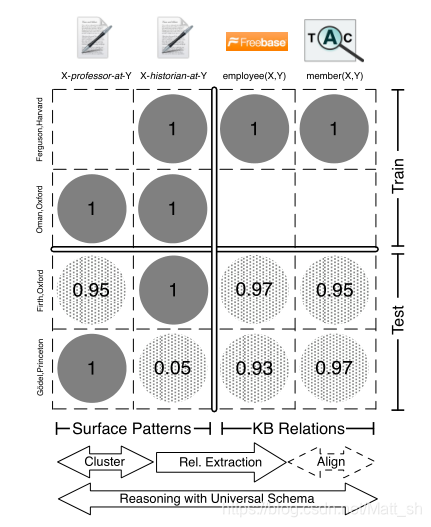
这是论文中的截图。可以看到,列的来源一部分是OpenIE得到的关系,一部分来源于现有KG,比如freebase。
**核心式子**:
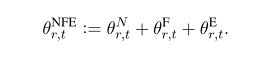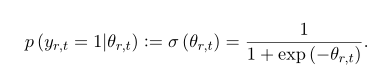
总结来说,定义了参数的不同部分,各种参数以及权重矩阵。
但问题是,只有正样本,没有负样本。也就是模型学习的是倾向于将不同情况预测为真。
> **Bayesian Personalized Ranking (BPR)**: uses a variant of this ranking:giving observed true facts higher scores than unobserved (true or false) facts (Rendle et al., 2009).
最初解决办法是同远程监督一般,自行构造负样本,但效果不好(对于不同负样本鲁棒性低,而且学习成本变高),所以使用了BPR方法。
**实验部分**
要解决的问题:
> How accurately can we fill a database of Universal Schema, and does reasoning jointly across a universal schema help to improve over more isolated approaches?
首先数据处理部分,将纽约时报文章预料提取的命名体与freebase的元组进行连接,再过滤筛选。
>Based on this alignment we filter out all relations for which we find fewer than 10 tuples with mentions in text.
接着,构建矩阵。对每个元组t,对应的关系实例$O_t$由两部分组成。$O_t = O_t^{FB}\cup O_t^{PAT}$。
这样就从数据集-建立了矩阵。
评估部分,构建PRC曲线。这里计算precision的方法:对每个关系,取前1000个实体对。将前100个集中起来,手工判断其相关性或者真实性。,由此结果计算召回率与准确度。
所以说,开放性关系抽取只是获取数据集的工具,这篇文章的重点还是这个矩阵以及对应的参数估计方法。
作者:Matt_sh