SpringBoot超大文件上传实现秒传功能
1.分片上传
1.1 什么是分片上传
1.2 分片上传的场景
2.断点续传
2.1 什么是断点续传
2.2 应用场景
2.3 实现断点续传的核心逻辑
2.4 实现流程步骤
3.分片上传/断点上传代码实现
3.1 前端实现
3.2 后端写入文件
3.3 进行写入操作的核心代码
4.秒传
4.1 什么是秒传
4.2 实现的秒传核心逻辑
4.3 核心代码
5.总结
文件上传是一个老生常谈的话题了,在文件相对比较小的情况下,可以直接把文件转化为字节流上传到服务器,但在文件比较大的情况下,用普通的方式进行上传,这可不是一个好的办法,毕竟很少有人会忍受,当文件上传到一半中断后,继续上传却只能重头开始上传,这种让人不爽的体验。那有没有比较好的上传体验呢,答案有的,就是下边要介绍的几种上传方式
1.分片上传 1.1 什么是分片上传分片上传,就是将所要上传的文件,按照一定的大小,将整个文件分隔成多个数据块(我们称之为Part)来进行分别上传,上传完之后再由服务端对所有上传的文件进行汇总整合成原始的文件。
1.2 分片上传的场景1.大文件上传
2.网络环境环境不好,存在需要重传风险的场景
2.断点续传 2.1 什么是断点续传断点续传是在下载或上传时,将下载或上传任务(一个文件或一个压缩包)人为的划分为几个部分,每一个部分采用一个线程进行上传或下载,如果碰到网络故障,可以从已经上传或下载的部分开始继续上传或者下载未完成的部分,而没有必要从头开始上传或者下载。
2.2 应用场景本文的断点续传主要是针对断点上传场景。
断点续传可以看成是分片上传的一个衍生,因此可以使用分片上传的场景,都可以使用断点续传。
2.3 实现断点续传的核心逻辑在分片上传的过程中,如果因为系统崩溃或者网络中断等异常因素导致上传中断,这时候客户端需要记录上传的进度。在之后支持再次上传时,可以继续从上次上传中断的地方进行继续上传。
为了避免客户端在上传之后的进度数据被删除而导致重新开始从头上传的问题,服务端也可以提供相应的接口便于客户端对已经上传的分片数据进行查询,从而使客户端知道已经上传的分片数据,从而从下一个分片数据开始继续上传。
整体的过程如下:
2.4 实现流程步骤1.前端将文件安装百分比进行计算,每次上传文件的百分之一(文件分片),给文件分片做上序号
2.后端将前端每次上传的文件,放入到缓存目录
3.等待前端将全部的文件内容都上传完毕后,发送一个合并请求
4.后端使用RandomAccessFile进多线程读取所有的分片文件,一个线程一个分片
5.后端每个线程按照序号将分片的文件写入到目标文件中
6.在上传文件的过程中发生断网了或者手动暂停了,下次上传的时候发送续传请求,让后端删除最后一个分片
7.前端重新发送上次的文件分片
方案一,常规步骤
将需要上传的文件按照一定的分割规则,分割成相同大小的数据块;
初始化一个分片上传任务,返回本次分片上传唯一标识;
按照一定的策略(串行或并行)发送各个分片数据块;
发送完成后,服务端根据判断数据上传是否完整,如果完整,则进行数据块合成得到原始文件。
方案二、本文实现的步骤
前端(客户端)需要根据固定大小对文件进行分片,请求后端(服务端)时要带上分片序号和大小。
服务端创建conf文件用来记录分块位置,conf文件长度为总分片数,每上传一个分块即向conf文件中写入一个127,那么没上传的位置就是默认的0,已上传的就是Byte.MAX_VALUE 127(这步是实现断点续传和秒传的核心步骤)
服务器按照请求数据中给的分片序号和每片分块大小(分片大小是固定且一样的)算出开始位置,与读取到的文件片段数据,写入文件。
整体的实现流程如下:

前端的File对象是特殊类型的Blob,且可以用在任意的Blob类型的上下文中。
就是说能够处理Blob对象的方法也能处理File对象。在Blob的方法里有有一个Slice方法可以帮完成切片。
核心代码:
fileMD5 (files) {
// 计算文件md5
return new Promise((resolve,reject) => {
const fileReader = new FileReader();
const piece = Math.ceil(files.size / this.pieceSize);
const nextPiece = () => {
let start = currentPieces * this.pieceSize;
let end = start * this.pieceSize >= files.size ? files.size : start + this.pieceSize;
fileReader.readAsArrayBuffer(files.slice(start,end));
};
let currentPieces = 0;
fileReader.onload = (event) => {
let e = window.event || event;
this.spark.append(e.target.result);
currentPieces++
if (currentPieces < piece) {
nextPiece()
} else {
resolve({fileName: files.name, fileMd5: this.spark.end()})
}
}
// fileReader.onerror = (err => { reject(err) })
nextPiece()
})
}
当然如果我们是vue项目的话还有更好的选择,我们可以使用一些开源的框架,本文推荐使用vue-simple-uploader 实现文件分片上传、断点续传及秒传,后面我会将《前端使用 vue-simple-uploader 实现文件分片上传、断点续传及秒传》的内容更新
当然我们也可以采用百度提供的webuploader的插件,进行分片。
操作方式也特别简单,直接按照官方文档给出的操作进行即可。
《webuploader官方文档》
当然啦,我也使用了一下这个插件,大家也可以跟着我的另一篇博客一起学习一下,篇幅很短,可以快速上手:《分片上传—webloader》
3.2 后端写入文件后端用两种方式实现文件写入:
RandomAccessFile
MappedByteBuffer
在向下学习之前,我们先简单了解一下这两个类的使用
RandomAccessFile
Java除了File类之外,还提供了专门处理文件的类,即RandomAccessFile(随机访问文件)类。
该类是Java语言中功能最为丰富的文件访问类,它提供了众多的文件访问方法。RandomAccessFile类支持“随机访问”方式,这里“随机”是指可以跳转到文件的任意位置处读写数据。在访问一个文件的时候,不必把文件从头读到尾,而是希望像访问一个数据库一样“随心所欲”地访问一个文件的某个部分,这时使用RandomAccessFile类就是最佳选择。
RandomAccessFile对象类有个位置指示器,指向当前读写处的位置,当前读写n个字节后,文件指示器将指向这n个字节后面的下一个字节处。
刚打开文件时,文件指示器指向文件的开头处,可以移动文件指示器到新的位置,随后的读写操作将从新的位置开始。
RandomAccessFile类在数据等长记录格式文件的随机(相对顺序而言)读取时有很大的优势,但该类仅限于操作文件,不能访问其他的I/O设备,如网络、内存映像等。
RandomAccessFile类的构造方法如下所示:
//创建随机存储文件流,文件属性由参数File对象指定
RandomAccessFile(File file , String mode)
//创建随机存储文件流,文件名由参数name指定
RandomAccessFile(String name , String mode)
这两个构造方法均涉及到一个String类型的参数mode,它决定随机存储文件流的操作模式,其中mode值及对应的含义如下:
“r”:以只读的方式打开,调用该对象的任何write(写)方法都会导致IOException异常
“rw”:以读、写方式打开,支持文件的读取或写入。若文件不存在,则创建之。
“rws”:以读、写方式打开,与“rw”不同的是,还要对文件内容的每次更新都同步更新到潜在的存储设备中去。这里的“s”表示synchronous(同步)的意思
“rwd”:以读、写方式打开,与“rw”不同的是,还要对文件内容的每次更新都同步更新到潜在的存储设备中去。使用“rwd”模式仅要求将文件的内容更新到存储设备中,而使用“rws”模式除了更新文件的内容,还要更新文件的元数据(metadata),因此至少要求1次低级别的I/O操作
import java.io.RandomAccessFile;
import java.nio.charset.StandardCharsets;
public class RandomFileTest {
private static final String filePath = "C:\\Users\\NineSun\\Desktop\\employee.txt";
public static void main(String[] args) throws Exception {
Employee e1 = new Employee("zhangsan", 23);
Employee e2 = new Employee("lisi", 24);
Employee e3 = new Employee("wangwu", 25);
RandomAccessFile ra = new RandomAccessFile(filePath, "rw");
ra.write(e1.name.getBytes(StandardCharsets.UTF_8));//防止写入文件乱码
ra.writeInt(e1.age);
ra.write(e2.name.getBytes());
ra.writeInt(e2.age);
ra.write(e3.name.getBytes());
ra.writeInt(e3.age);
ra.close();
RandomAccessFile raf = new RandomAccessFile(filePath, "r");
int len = 8;
raf.skipBytes(12);//跳过第一个员工的信息,其姓名8字节,年龄4字节
System.out.println("第二个员工信息:");
String str = "";
for (int i = 0; i < len; i++) {
str = str + (char) raf.readByte();
}
System.out.println("name:" + str);
System.out.println("age:" + raf.readInt());
System.out.println("第一个员工信息:");
raf.seek(0);//将文件指针移动到文件开始位置
str = "";
for (int i = 0; i < len; i++) {
str = str + (char) raf.readByte();
}
System.out.println("name:" + str);
System.out.println("age:" + raf.readInt());
System.out.println("第三个员工信息:");
raf.skipBytes(12);//跳过第二个员工的信息
str = "";
for (int i = 0; i < len; i++) {
str = str + (char) raf.readByte();
}
System.out.println("name:" + str);
System.out.println("age:" + raf.readInt());
raf.close();
}
}
class Employee {
String name;
int age;
final static int LEN = 8;
public Employee(String name, int age) {
if (name.length() > LEN) {
name = name.substring(0, 8);
} else {
while (name.length() < LEN) {
name = name + "\u0000";
}
this.name = name;
this.age = age;
}
}
}
MappedByteBuffer
java io操作中通常采用BufferedReader,BufferedInputStream等带缓冲的IO类处理大文件,不过java nio中引入了一种基于MappedByteBuffer操作大文件的方式,其读写性能极高,想要深入了解的话可以读一下《深入浅出MappedByteBuffer》
3.3 进行写入操作的核心代码为了节约文章篇幅,下面我只展示核心代码,完整代码可以在文末进行下载
RandomAccessFile实现方式
@UploadMode(mode = UploadModeEnum.RANDOM_ACCESS)
@Slf4j
public class RandomAccessUploadStrategy extends SliceUploadTemplate {
@Autowired
private FilePathUtil filePathUtil;
@Value("${upload.chunkSize}")
private long defaultChunkSize;
@Override
public boolean upload(FileUploadRequestDTO param) {
RandomAccessFile accessTmpFile = null;
try {
String uploadDirPath = filePathUtil.getPath(param);
File tmpFile = super.createTmpFile(param);
accessTmpFile = new RandomAccessFile(tmpFile, "rw");
//这个必须与前端设定的值一致
long chunkSize = Objects.isNull(param.getChunkSize()) ? defaultChunkSize * 1024 * 1024
: param.getChunkSize();
long offset = chunkSize * param.getChunk();
//定位到该分片的偏移量
accessTmpFile.seek(offset);
//写入该分片数据
accessTmpFile.write(param.getFile().getBytes());
boolean isOk = super.checkAndSetUploadProgress(param, uploadDirPath);
return isOk;
} catch (IOException e) {
log.error(e.getMessage(), e);
} finally {
FileUtil.close(accessTmpFile);
}
return false;
}
}
MappedByteBuffer实现方式
@UploadMode(mode = UploadModeEnum.MAPPED_BYTEBUFFER)
@Slf4j
public class MappedByteBufferUploadStrategy extends SliceUploadTemplate {
@Autowired
private FilePathUtil filePathUtil;
@Value("${upload.chunkSize}")
private long defaultChunkSize;
@Override
public boolean upload(FileUploadRequestDTO param) {
RandomAccessFile tempRaf = null;
FileChannel fileChannel = null;
MappedByteBuffer mappedByteBuffer = null;
try {
String uploadDirPath = filePathUtil.getPath(param);
File tmpFile = super.createTmpFile(param);
tempRaf = new RandomAccessFile(tmpFile, "rw");
fileChannel = tempRaf.getChannel();
long chunkSize = Objects.isNull(param.getChunkSize()) ? defaultChunkSize * 1024 * 1024
: param.getChunkSize();
//写入该分片数据
long offset = chunkSize * param.getChunk();
byte[] fileData = param.getFile().getBytes();
mappedByteBuffer = fileChannel
.map(FileChannel.MapMode.READ_WRITE, offset, fileData.length);
mappedByteBuffer.put(fileData);
boolean isOk = super.checkAndSetUploadProgress(param, uploadDirPath);
return isOk;
} catch (IOException e) {
log.error(e.getMessage(), e);
} finally {
FileUtil.freedMappedByteBuffer(mappedByteBuffer);
FileUtil.close(fileChannel);
FileUtil.close(tempRaf);
}
return false;
}
}
文件操作核心模板类代码
@Slf4j
public abstract class SliceUploadTemplate implements SliceUploadStrategy {
public abstract boolean upload(FileUploadRequestDTO param);
protected File createTmpFile(FileUploadRequestDTO param) {
FilePathUtil filePathUtil = SpringContextHolder.getBean(FilePathUtil.class);
param.setPath(FileUtil.withoutHeadAndTailDiagonal(param.getPath()));
String fileName = param.getFile().getOriginalFilename();
String uploadDirPath = filePathUtil.getPath(param);
String tempFileName = fileName + "_tmp";
File tmpDir = new File(uploadDirPath);
File tmpFile = new File(uploadDirPath, tempFileName);
if (!tmpDir.exists()) {
tmpDir.mkdirs();
}
return tmpFile;
}
@Override
public FileUploadDTO sliceUpload(FileUploadRequestDTO param) {
boolean isOk = this.upload(param);
if (isOk) {
File tmpFile = this.createTmpFile(param);
FileUploadDTO fileUploadDTO = this.saveAndFileUploadDTO(param.getFile().getOriginalFilename(), tmpFile);
return fileUploadDTO;
}
String md5 = FileMD5Util.getFileMD5(param.getFile());
Map<Integer, String> map = new HashMap<>();
map.put(param.getChunk(), md5);
return FileUploadDTO.builder().chunkMd5Info(map).build();
}
/**
* 检查并修改文件上传进度
*/
public boolean checkAndSetUploadProgress(FileUploadRequestDTO param, String uploadDirPath) {
String fileName = param.getFile().getOriginalFilename();
File confFile = new File(uploadDirPath, fileName + ".conf");
byte isComplete = 0;
RandomAccessFile accessConfFile = null;
try {
accessConfFile = new RandomAccessFile(confFile, "rw");
//把该分段标记为 true 表示完成
System.out.println("set part " + param.getChunk() + " complete");
//创建conf文件文件长度为总分片数,每上传一个分块即向conf文件中写入一个127,那么没上传的位置就是默认0,已上传的就是Byte.MAX_VALUE 127
accessConfFile.setLength(param.getChunks());
accessConfFile.seek(param.getChunk());
accessConfFile.write(Byte.MAX_VALUE);
//completeList 检查是否全部完成,如果数组里是否全部都是127(全部分片都成功上传)
byte[] completeList = FileUtils.readFileToByteArray(confFile);
isComplete = Byte.MAX_VALUE;
for (int i = 0; i < completeList.length && isComplete == Byte.MAX_VALUE; i++) {
//与运算, 如果有部分没有完成则 isComplete 不是 Byte.MAX_VALUE
isComplete = (byte) (isComplete & completeList[i]);
System.out.println("check part " + i + " complete?:" + completeList[i]);
}
} catch (IOException e) {
log.error(e.getMessage(), e);
} finally {
FileUtil.close(accessConfFile);
}
boolean isOk = setUploadProgress2Redis(param, uploadDirPath, fileName, confFile, isComplete);
return isOk;
}
/**
* 把上传进度信息存进redis
*/
private boolean setUploadProgress2Redis(FileUploadRequestDTO param, String uploadDirPath,
String fileName, File confFile, byte isComplete) {
RedisUtil redisUtil = SpringContextHolder.getBean(RedisUtil.class);
if (isComplete == Byte.MAX_VALUE) {
redisUtil.hset(FileConstant.FILE_UPLOAD_STATUS, param.getMd5(), "true");
redisUtil.del(FileConstant.FILE_MD5_KEY + param.getMd5());
confFile.delete();
return true;
} else {
if (!redisUtil.hHasKey(FileConstant.FILE_UPLOAD_STATUS, param.getMd5())) {
redisUtil.hset(FileConstant.FILE_UPLOAD_STATUS, param.getMd5(), "false");
redisUtil.set(FileConstant.FILE_MD5_KEY + param.getMd5(),
uploadDirPath + FileConstant.FILE_SEPARATORCHAR + fileName + ".conf");
}
return false;
}
}
/**
* 保存文件操作
*/
public FileUploadDTO saveAndFileUploadDTO(String fileName, File tmpFile) {
FileUploadDTO fileUploadDTO = null;
try {
fileUploadDTO = renameFile(tmpFile, fileName);
if (fileUploadDTO.isUploadComplete()) {
System.out
.println("upload complete !!" + fileUploadDTO.isUploadComplete() + " name=" + fileName);
//TODO 保存文件信息到数据库
}
} catch (Exception e) {
log.error(e.getMessage(), e);
} finally {
}
return fileUploadDTO;
}
/**
* 文件重命名
*
* @param toBeRenamed 将要修改名字的文件
* @param toFileNewName 新的名字
*/
private FileUploadDTO renameFile(File toBeRenamed, String toFileNewName) {
//检查要重命名的文件是否存在,是否是文件
FileUploadDTO fileUploadDTO = new FileUploadDTO();
if (!toBeRenamed.exists() || toBeRenamed.isDirectory()) {
log.info("File does not exist: {}", toBeRenamed.getName());
fileUploadDTO.setUploadComplete(false);
return fileUploadDTO;
}
String ext = FileUtil.getExtension(toFileNewName);
String p = toBeRenamed.getParent();
String filePath = p + FileConstant.FILE_SEPARATORCHAR + toFileNewName;
File newFile = new File(filePath);
//修改文件名
boolean uploadFlag = toBeRenamed.renameTo(newFile);
fileUploadDTO.setMtime(DateUtil.getCurrentTimeStamp());
fileUploadDTO.setUploadComplete(uploadFlag);
fileUploadDTO.setPath(filePath);
fileUploadDTO.setSize(newFile.length());
fileUploadDTO.setFileExt(ext);
fileUploadDTO.setFileId(toFileNewName);
return fileUploadDTO;
}
}
上传接口
@PostMapping(value = "/upload")
@ResponseBody
public Result<FileUploadDTO> upload(FileUploadRequestDTO fileUploadRequestDTO) throws IOException {
boolean isMultipart = ServletFileUpload.isMultipartContent(request);
FileUploadDTO fileUploadDTO = null;
if (isMultipart) {
StopWatch stopWatch = new StopWatch();
stopWatch.start("upload");
if (fileUploadRequestDTO.getChunk() != null && fileUploadRequestDTO.getChunks() > 0) {
fileUploadDTO = fileService.sliceUpload(fileUploadRequestDTO);
} else {
fileUploadDTO = fileService.upload(fileUploadRequestDTO);
}
stopWatch.stop();
log.info("{}",stopWatch.prettyPrint());
return new Result<FileUploadDTO>().setData(fileUploadDTO);
}
throw new BizException("上传失败", 406);
}
4.秒传
4.1 什么是秒传
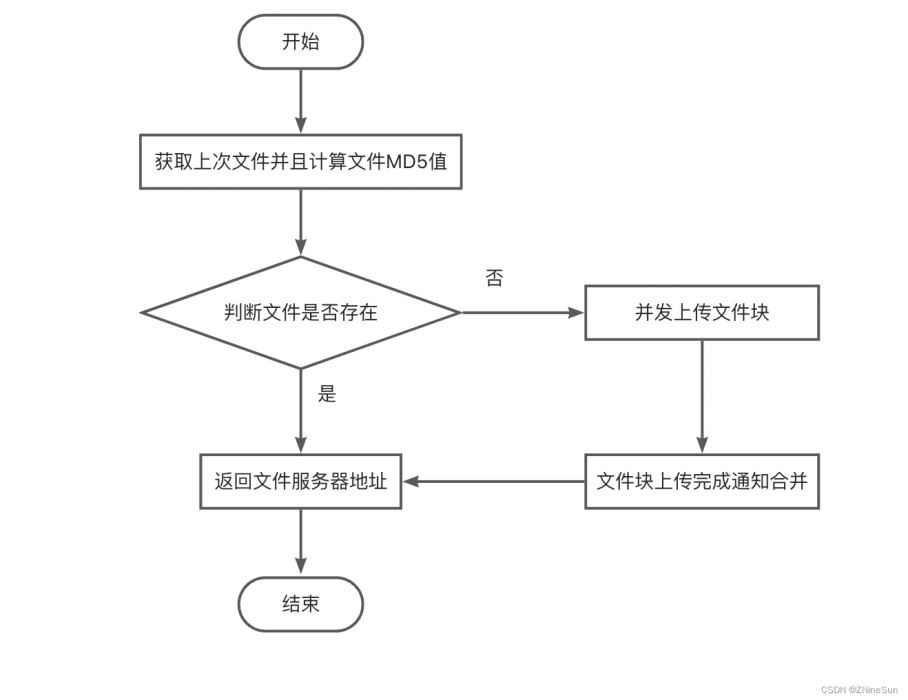
通俗的说,你把要上传的东西上传,服务器会先做MD5校验,如果服务器上有一样的东西,它就直接给你个新地址,其实你下载的都是服务器上的同一个文件,想要不秒传,其实只要让MD5改变,就是对文件本身做一下修改(改名字不行),例如一个文本文件,你多加几个字,MD5就变了,就不会秒传了。
4.2 实现的秒传核心逻辑利用redis的set方法存放文件上传状态,其中key为文件上传的md5,value为是否上传完成的标志位,
当标志位true为上传已经完成,此时如果有相同文件上传,则进入秒传逻辑。
如果标志位为false,则说明还没上传完成,此时需要在调用set的方法,保存块号文件记录的路径,其中
key为上传文件md5加一个固定前缀
value为块号文件记录路径
private boolean setUploadProgress2Redis(FileUploadRequestDTO param, String uploadDirPath,
String fileName, File confFile, byte isComplete) {
RedisUtil redisUtil = SpringContextHolder.getBean(RedisUtil.class);
if (isComplete == Byte.MAX_VALUE) {
redisUtil.hset(FileConstant.FILE_UPLOAD_STATUS, param.getMd5(), "true");
redisUtil.del(FileConstant.FILE_MD5_KEY + param.getMd5());
confFile.delete();
return true;
} else {
if (!redisUtil.hHasKey(FileConstant.FILE_UPLOAD_STATUS, param.getMd5())) {
redisUtil.hset(FileConstant.FILE_UPLOAD_STATUS, param.getMd5(), "false");
redisUtil.set(FileConstant.FILE_MD5_KEY + param.getMd5(),
uploadDirPath + FileConstant.FILE_SEPARATORCHAR + fileName + ".conf");
}
return false;
}
}
5.总结
在实现分片上传的过程,需要前端和后端配合,比如前后端的上传块号的文件大小,前后端必须得要一致,否则上传就会有问题。
其次文件相关操作正常都是要搭建一个文件服务器的,比如使用fastdfs、hdfs等。
如果项目组觉得自建文件服务器太花费时间,且项目的需求仅仅只是上传下载,那么推荐使用阿里的oss服务器,其介绍可以查看官网:
https://help.aliyun.com/product/31815.html
阿里的oss它本质是一个对象存储服务器,而非文件服务器,因此如果有涉及到大量删除或者修改文件的需求,oss可能就不是一个好的选择。
项目地址:https://gitee.com/ninesuntec/large-file-upload
到此这篇关于Spring Boot超大文件上传实现秒传功能的文章就介绍到这了,更多相关Spring Boot超大文件上传内容请搜索软件开发网以前的文章或继续浏览下面的相关文章希望大家以后多多支持软件开发网!