Python高级特性与网络爬虫(二):使用Selenium自动化测试工具爬取一号店商品信息
上一篇介绍了Ajax动态渲染的页面的分析和爬取,通过JavaScript动态渲染的页面的方式不只有ajax这一种,还有很多其他的方式,分析他们的网页结构和加密参数难度非常大,为了解决这样的页面的数据爬取,我们可以直接使用模拟浏览器运行的方式来实现。python中有很多可以模拟浏览器运行的库,其中最常用的是Selenium,它是一个自动化的web应用的软件测试工具,利用它可以驱动浏览器执行特定的动作,同时也可以获取浏览器当前呈现的页面的源代码,这篇博文将向大家简要介绍一下selenium的使用以及如何通过selenium来爬取一号店的商品信息
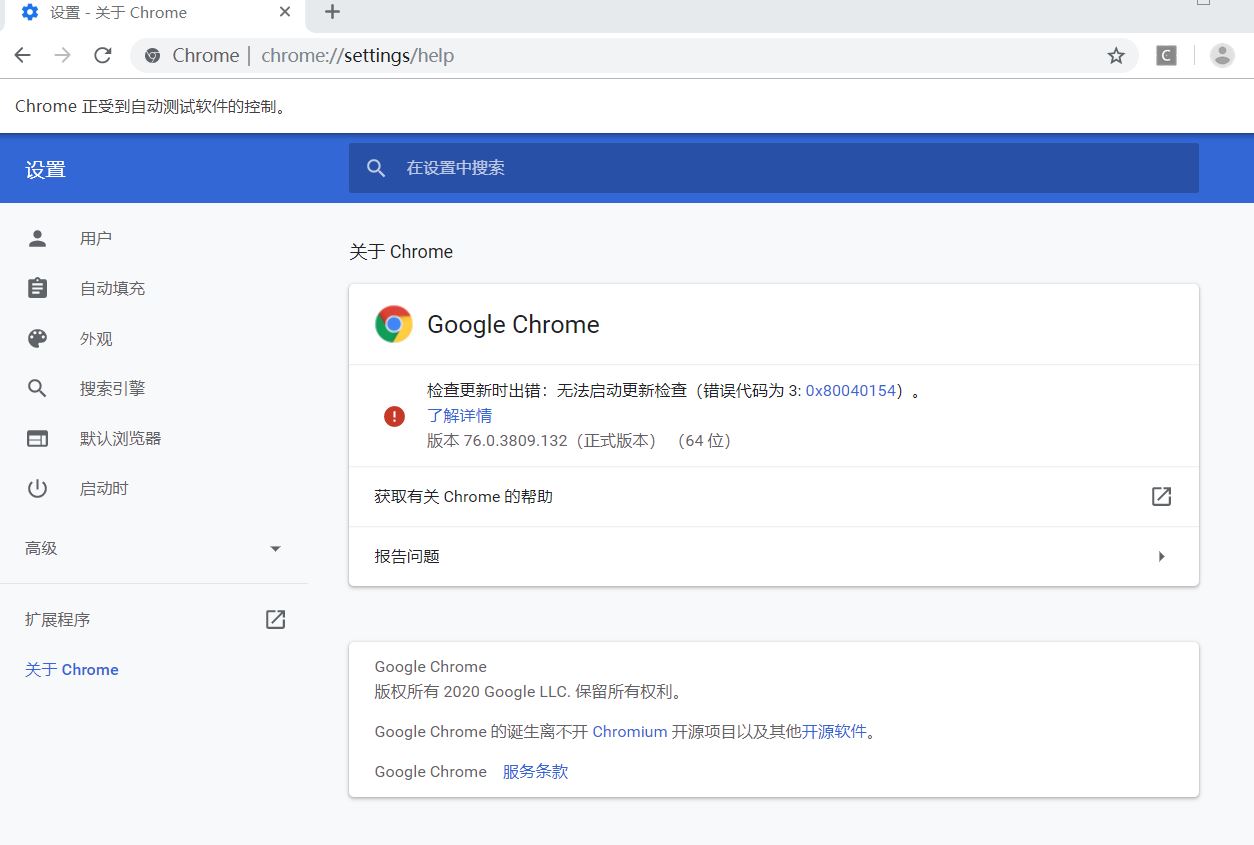
Selenium的配置与使用 Selenium库的安装与ChromeDriver的配置我们这里以selenium驱动Chrome浏览器为例,先在python中通过pip install selenium安装好selenium库,之后为了能够让selenium驱动Chrome还需要去下载ChromeDriver,通过国内镜像网站进行下载http://npm.taobao.org/mirrors/chromedriver/,下载前先要确认自己的Chrome浏览器内核版本,如下图所示,内核版本为76.0.3809.132,下载的76.0.3809.126亲测可用,然后将下载好的chromedriver.exe文件放到python的Script目录下,配置工作完成。
 ',str(img))[0]
if 'src' in url:
url=re.findall('
',str(img))[0]
if 'src' in url:
url=re.findall('',str(img))[0]
url="http:"+url #图片下载链接,有两种图片链接格式,所以要分别处理
try:
pic_r=requests.get(url)
title=url.split('/')[-1].split('!')[0]
#print(title)
with open('yhd_np\{0}'.format(title),'wb') as f:
f.write(pic_r.content)
except:
print(img)
print(url)
wait=WebDriverWait(browser,10)
submit=wait.until(EC.element_to_be_clickable((By.ID,'page_'+str(i))))
submit.click() #点击翻页
browser.close()#关闭浏览器
最终各商品的小图都下载到文件夹中,如下所示:
作者:星风雪宇