网络爬虫 - 规则
实例1 京东商品页面的爬取

作者:喝醉酒的小白
查看robots协议
import requests
# from pprint import pprint
url = "https://item.jd.com/100009177424.html"
try:
r = requests.get(url)
# print(r.status_code) #HTTP请求的返回状态,200表示连接成功,404表示失败
# print(r.encoding) #从HTTP header中猜测的响应内容编码方式
# print(r.apparent_encoding) #从内容中分析出的响应内容编码方式(备选编码方式)
r.encoding = r.apparent_encoding
print(r.text[:1000])
# pprint(r.text[:1000])
except:
print("Fail!!!")
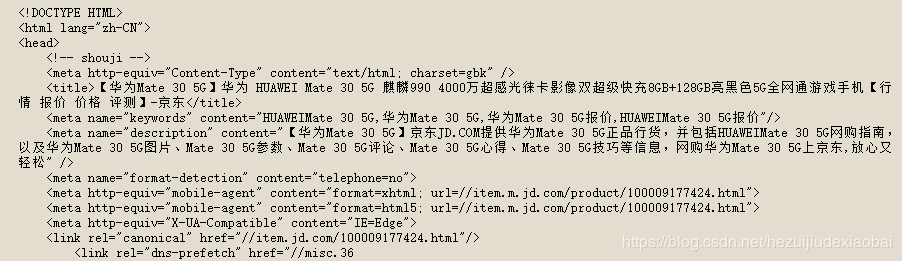
robots
import requests
url = "https://www.amazon.cn/gp/product/B01M8L5Z3Y"
try:
kv = {'user-agent': 'Mozilla/5.0'} #不加 -> 503
r = requests.get(url, headers=kv)
# print(r.status_code) #HTTP请求的返回状态,200表示连接成功,404表示失败
# print(r.encoding) #从HTTP header中猜测的响应内容编码方式
# print(r.apparent_encoding) #从内容中分析出的响应内容编码方式(备选编码方式)
# print(r.request.headers)
r.raise_for_status() #如果转态不是200,引发HTTPError错误
r.encoding = r.apparent_encoding
print(r.text[1000:2000]) #HTTP响应内容的字符串形式,即,url对应的页面内容
except:
print("Fail!!!")
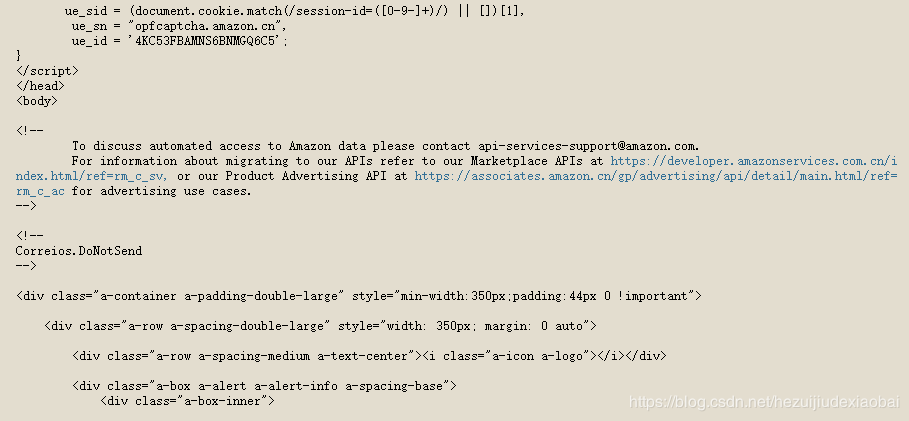
r = requests.get("http://www.baidu.com/s", params=kv) #params : 字典或字节序列,作为参数增加到url中
print(r.status_code)
print(r.request.url)

百度安全验证

原因:使用无头浏览器
解决方案
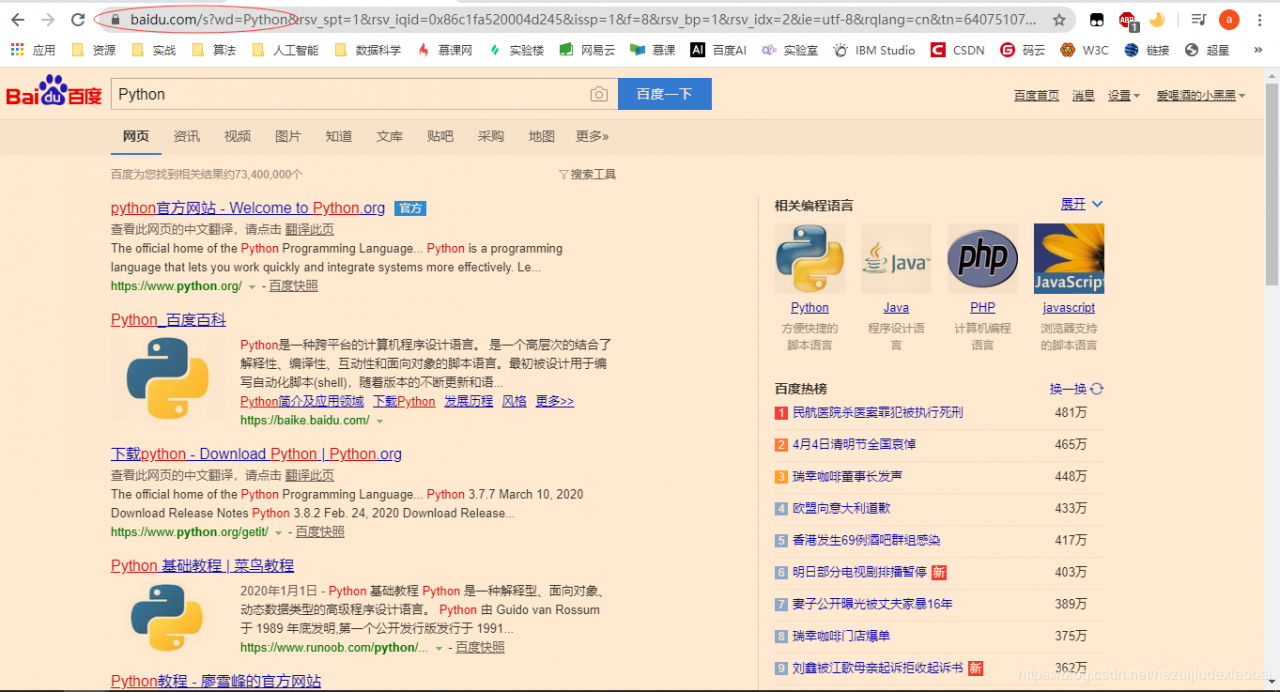
kv = {'wd': 'Python'}
headers = {'user-agent': 'Mozilla/5.0'}
r = requests.get("http://www.baidu.com/s", params=kv, headers=headers) #params : 字典或字节序列,作为参数增加到url中
print(r.status_code)
print(r.request.url)

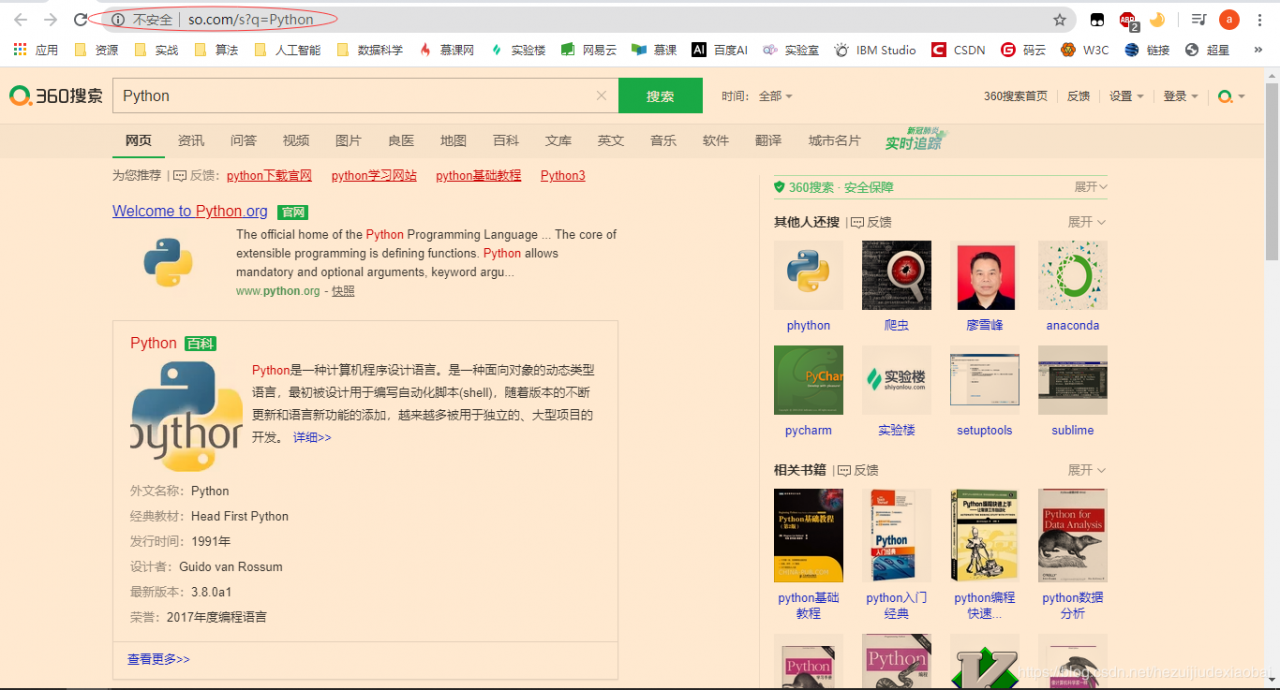
360的关键词接口
http://www.so.com/s?q=keyword
import requests
keyword = "Python"
try:
headers = {'user-agent': 'Mozilla/5.0'} #不加 -> 503
r = requests.get("http://www.so.com/s", headers=headers, params=kv) #params : 字典或字节序列,作为参数增加到url中
# print(r.status_code) #HTTP请求的返回状态,200表示连接成功,404表示失败
# print(r.encoding) #从HTTP header中猜测的响应内容编码方式
# print(r.apparent_encoding) #从内容中分析出的响应内容编码方式(备选编码方式)
# print(r.request.headers)
print(r.request.url)
r.raise_for_status() #如果转态不是200,引发HTTPError错误
r.encoding = r.apparent_encoding
print(len(r.text))
except:
print("Fail!!!")
![]()
DogeDoge的关键词接口
https://www.dogedoge.com/results?q=keyword
import requests
keyword = "Python"
try:
kv = {'q': keyword}
headers = {'user-agent': 'Mozilla/5.0'} #不加 -> 503
r = requests.get("https://dogedoge.com/results", headers=headers, params=kv) #params : 字典或字节序列,作为参数增加到url中
# print(r.status_code) #HTTP请求的返回状态,200表示连接成功,404表示失败
# print(r.encoding) #从HTTP header中猜测的响应内容编码方式
# print(r.apparent_encoding) #从内容中分析出的响应内容编码方式(备选编码方式)
# print(r.request.headers)
print(r.request.url)
r.raise_for_status() #如果转态不是200,引发HTTPError错误
r.encoding = r.apparent_encoding
print(len(r.text))
except:
print("Fail!!!")
![]()
国家地理
url = http://www.ngchina.com.cn/photography/picture_story/1643.html
作者:喝醉酒的小白