以项目为导向,助您入门python之网络爬虫-爬取京东商品plus价格低于原价5折的商品(二)
爬取京东商品plus价格低于原价5折的商品(二)
上一篇文章已经把整个爬取流程介绍完毕了,现在就不废话了,开始项目!
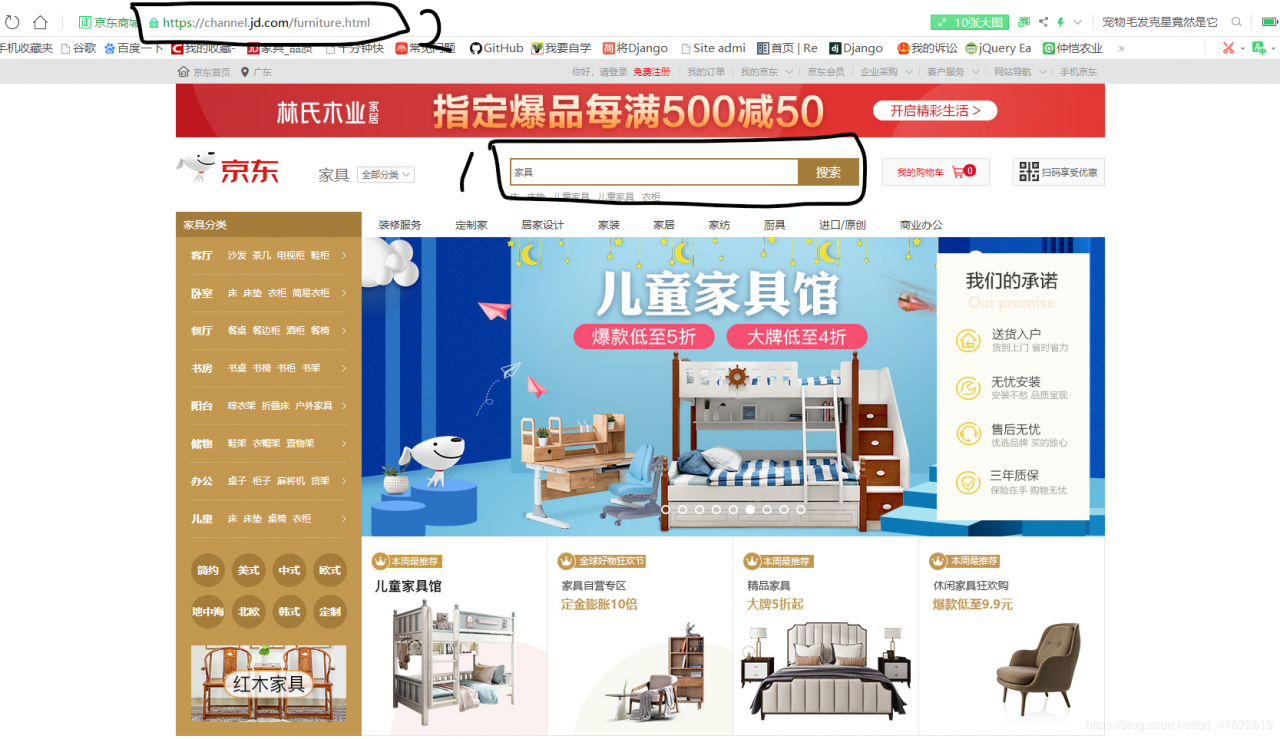 再搜索框里输入你想买的商品,以家具为例:
再搜索框里输入你想买的商品,以家具为例:


作者:欧sai
首先获取京东网页,打开京东首页:
再搜索框里输入你想买的商品,以家具为例:
关于家具的商品一共用100页,其实有更多的。这里的网址有一个规律:
设置一个变量n(如果你是啥都不懂的小白可以不用管变量这个术语,),然后商品的第一页至100页可以这样表示:
https://search.jd.com/Search?keyword=家具&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&stock=1&page=’+str(n)+’&s=’+str(1+(n-1)*30)+’&click=0&scrolling=y
加粗的keyword=家具 是你刚才在京东首页搜索的关键词,如果你想买衣服可以改为keyword=衣服
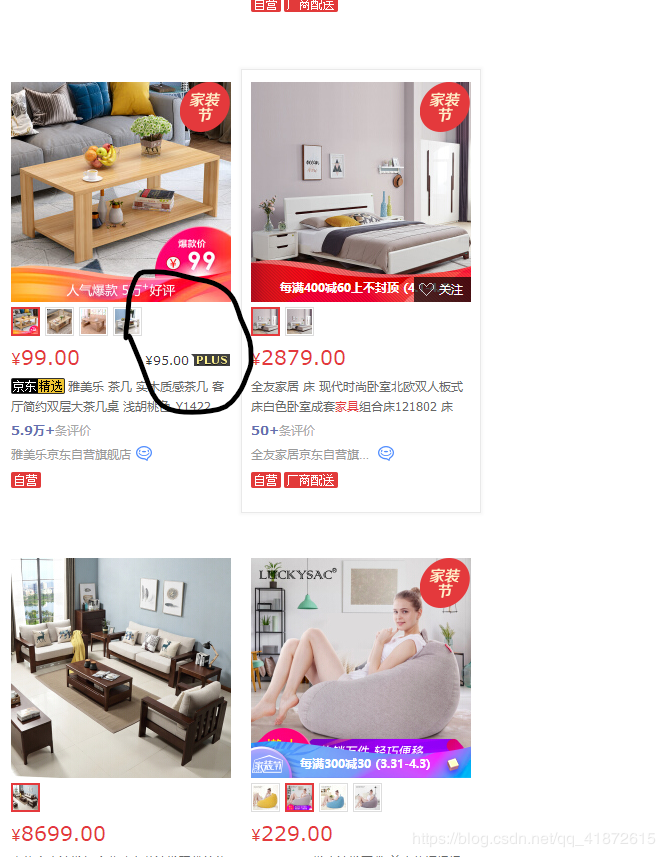
有了这个规律后,现在只需要把心思放在怎样爬取具体某一页的商品信息,然后按照这个规律,使用循环就可以了.怎样获得这个网页的所有信息呢?用我们正常的角度是看,用眼睛看,有会员价的商品都会有如下的图标:
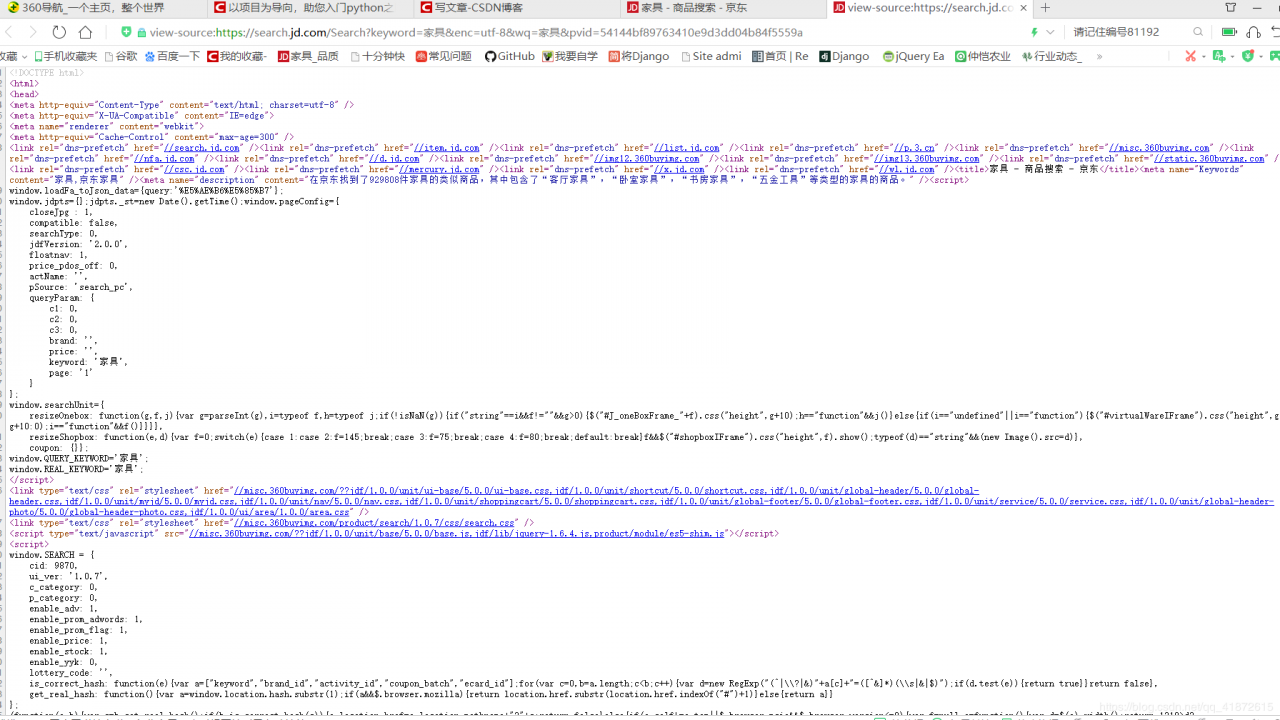
那么我们编程序也是让计算机去这个网页吗?使用计算机视觉技术是可以的,但是视觉技术都是大佬级别的才会,而且对计算机的性能要求高。其实我们现在看到的网页基本都是由HTML编写的,说白了也是用代码敲出来的,只要在网页里右击鼠标,然后点击查看源代码,你就可以看到这个页面的源码,这网页的所有信息都在这里。这样我们就可以 把视图问题转为处理文档的问题。
计算机自动获取网页源代码
#把网址传到url里,n为1到100的变量,n这个变量会在下面写到的循环中定义,现在暂时不定义
url = "https://search.jd.com/Search?keyword=" +"自营"+key + "&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&stock=1&page=" + str(n) + "&s=" + str(1 + (n - 1) * 30) + "&click=0&scrolling=y"
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/63.0.3239.132 Safari/537.36',
'upgrade-insecure-requests': '1',
}
#获取网页
html = requests.get(url, headers=headers).content.decode('utf-8')
print(html)#把获取到的网页源代码显示出来
今天的分享就到这里,下一篇文章讲述这个项目的核心,找plus价格低于原价5折的商品。
作者:欧sai