基于 Python 的网络爬虫:获取异步加载的数据
从重庆市政府采购网自动获取所有的采购公告信息,将其项目名称和采购物资通过可读的方式展示。
2. 实现过程 分析页面布局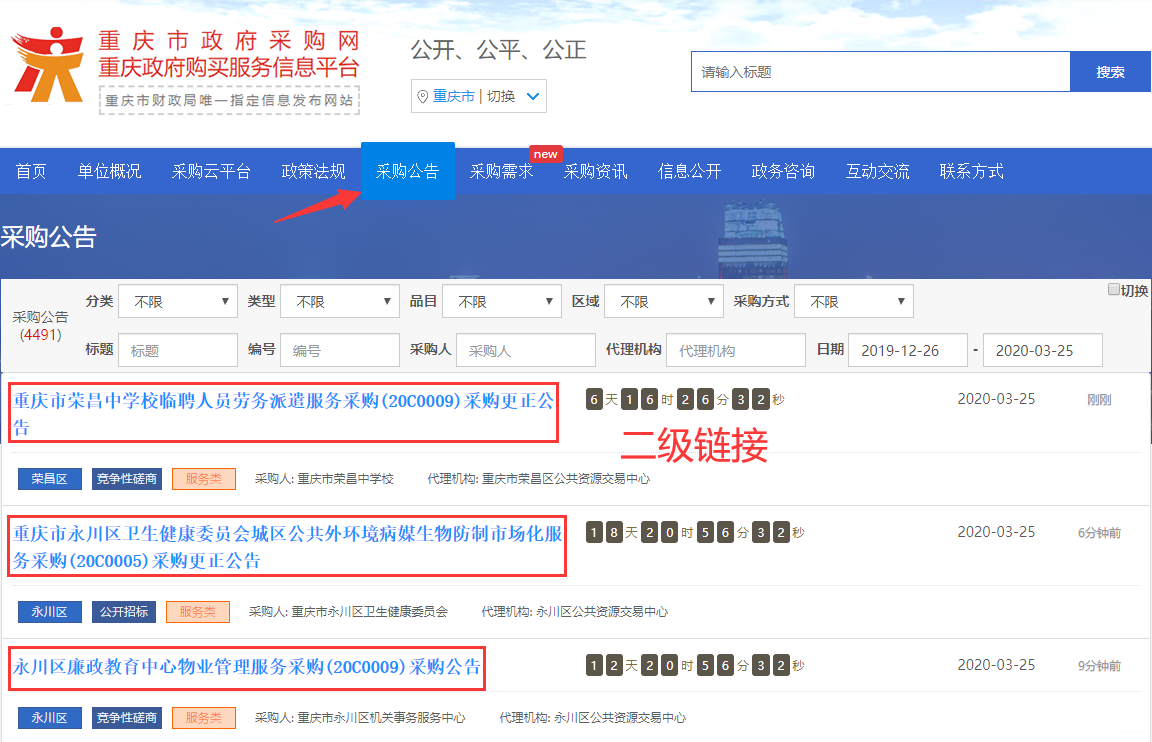 第一次爬取到“假网址”
第一次爬取到“假网址”
(1)首先,展示第一次爬取到的“假网址”。通过 xpath 匹配该 div。
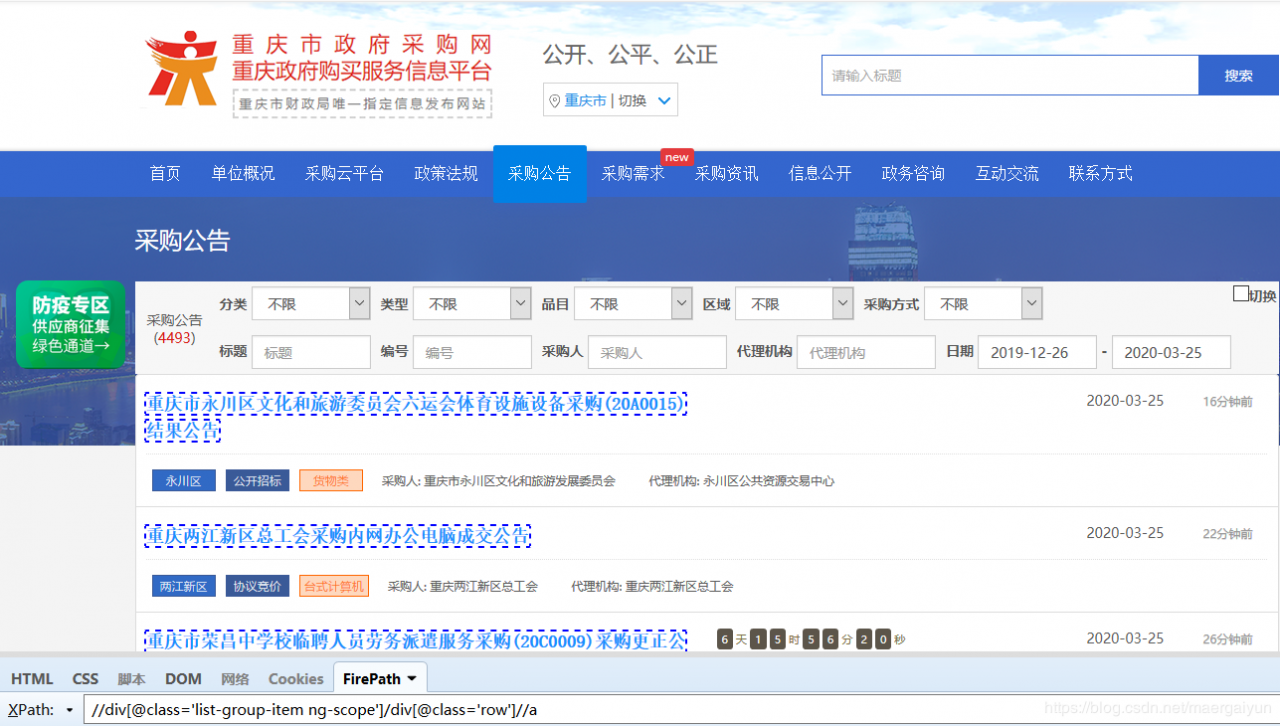
(2)尝试采集当前页面的所有二级链接。
import requests
from lxml import etree
import json
def getpage(url, headers):
res = requests.get(url, headers=headers)
html = etree.HTML(res.text)
return html
def parsepage(url, headers, all):
html = getpage(url, headers)
urllist = html.xpath("//div[@class='list-group-item ng-scope']/div[@class='row']//a")
print(urllist)
for i in urllist:
url = i.xpath("./@href")
all.append(url)
if __name__ == "__main__":
all = []
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 \
(KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36",
}
url = "https://www.ccgp-chongqing.gov.cn/notices/list"
res = parsepage(url, headers, all)
with open("ztb.html", "w", encoding="utf-8") as f:
f.write(res)
提示报错:TypeError: write() argument must be str, not None
可以看出,这种方法存在问题!
我们可以将使用 request 方法获取的数据保存为 html 文件,查看内容。
重新写一个只保存首页信息的函数:
import requests
from lxml import etree
import json
def getpage(url, headers):
res = requests.get(url, headers=headers)
# html = etree.HTML(res.text)
return res.text
if __name__ == "__main__":
all = []
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 \
(KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36",
}
url = "https://www.ccgp-chongqing.gov.cn/notices/list"
res = getpage(url,headers)
with open("bidding.html", "w", encoding="utf-8") as f:
f.write(res)
查看 bidding.html 文件:
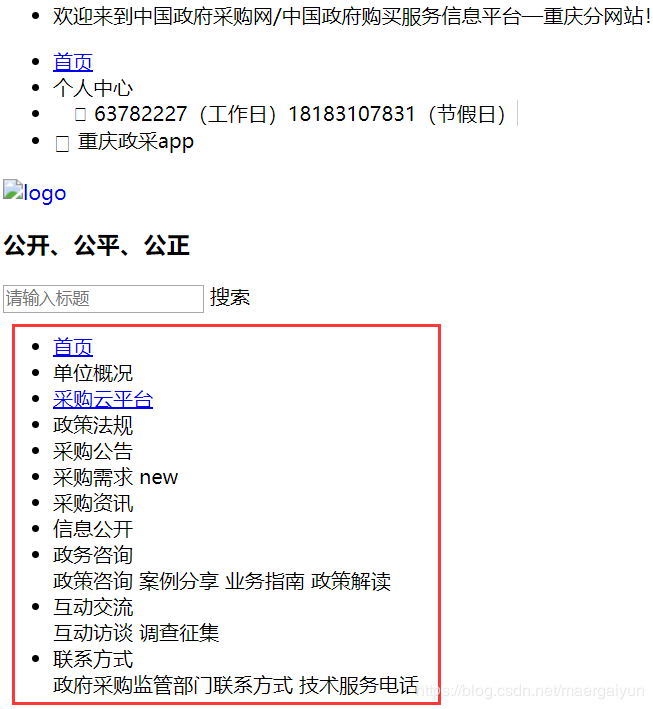
通过查看获取的内容,发现没有任何目录信息!得知这种方法采集的数据并不完整!
虽然想要的内容都在网页上,却爬取不到任何信息。这里我们考虑到网页异步加载的情况。
于是我们使用谷歌开发者工具检查 JS 和 XHR 中的每一项,发现在 XHR 中有我们想要的数据!
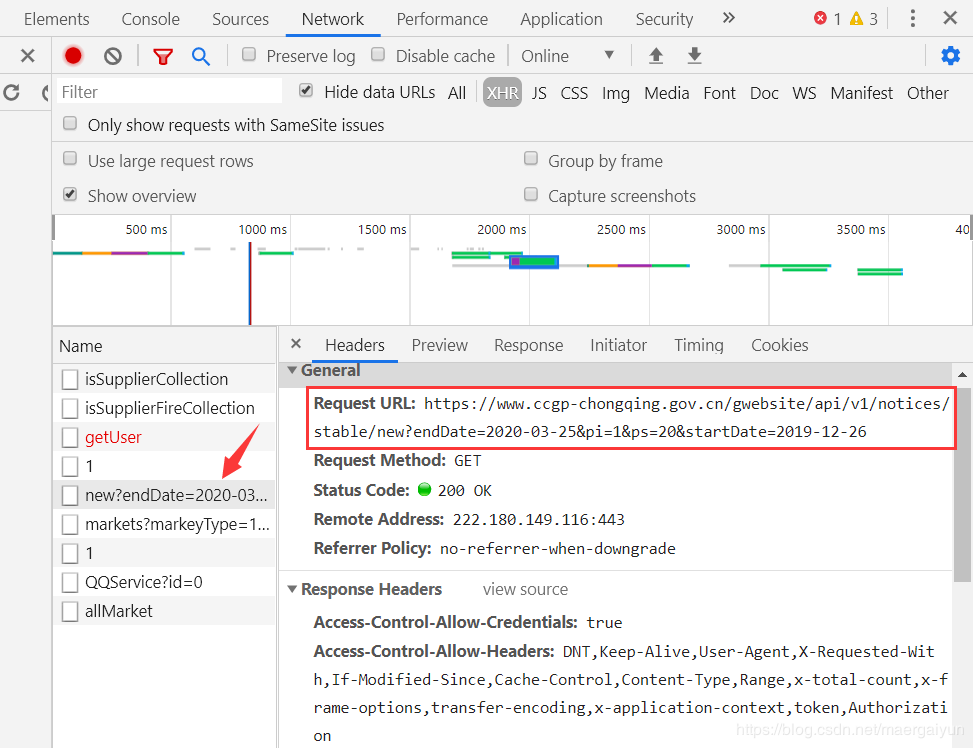
我们不妨请求一下这个网址,看看返回的是什么数据?
其实是一种 JSON 格式的数据,还是通过 JSON 格式显示工具来查看一下!
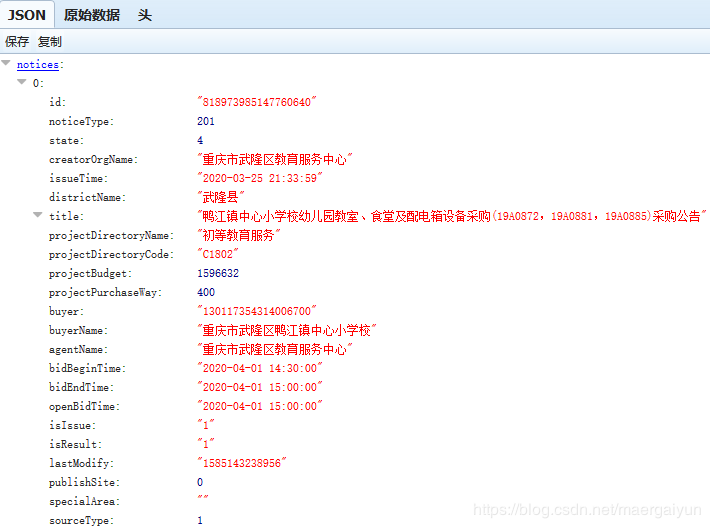
(1)在采集所有二级链接之前,我们先分析一下每个 url 的格式。
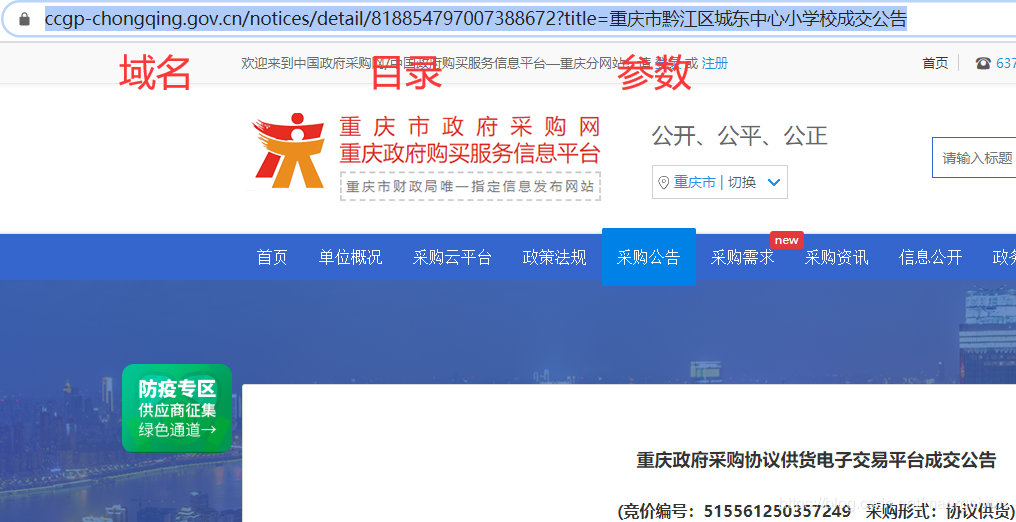
每一个公告的域名都有三部分构成,即域名、目录和参数。其中域名都是同样的;目录部分结尾是由每个项目的 id 构成的;参数是在"?"后面,可以不传。
(2)分析完之后,我们开始对新的 url 发起请求。
保留每个公告的项目名称和 url 数据,并且输出为 JSON 文本:
import requests
import json
def getpage(url, headers):
response = requests.get(url, headers=headers)
html = response.json()
return html
def getnotice(url, headers):
allnotices = []
html = getpage(url, headers)
notices = html['notices']
for i in notices:
notice = {}
notice["title"] = i["title"]
notice["id"] = i["id"]
allnotices.append(notice)
return allnotices
def geturl(url, headers):
allnotices = getnotice(url, headers)
allurls = []
for j in allnotices:
everyurl = {}
everyurl["projectname"] = j["title"]
everyurl["url"] = "https://www.ccgp-chongqing.gov.cn/notices/detail/" + j["id"]
everyurl["id"] = j["id"]
allurls.append(everyurl)
return allurls
if __name__ == "__main__":
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/63.0.3239.132 Safari/537.36"
}
url = "https://www.ccgp-chongqing.gov.cn/gwebsite/api/v1/notices/stable/new?endDate=2020-03-25&pi=1&ps=100&startDate=2019-12-26"
allurls = geturl(url, headers)
f = open("urls.json", "w", encoding="utf-8")
f.write(json.dumps(allurls, ensure_ascii=False, indent=4) + "\n")
f.close()
打开 allurls.json 文件,查看我们获取的数据是否是正确的。

(1)辨别“真假”。
在采集公告内容之前,需要特别说明的是,每个公告的内容其实也是通过异步传输的方式,我们可以通过谷歌开发工具检测。
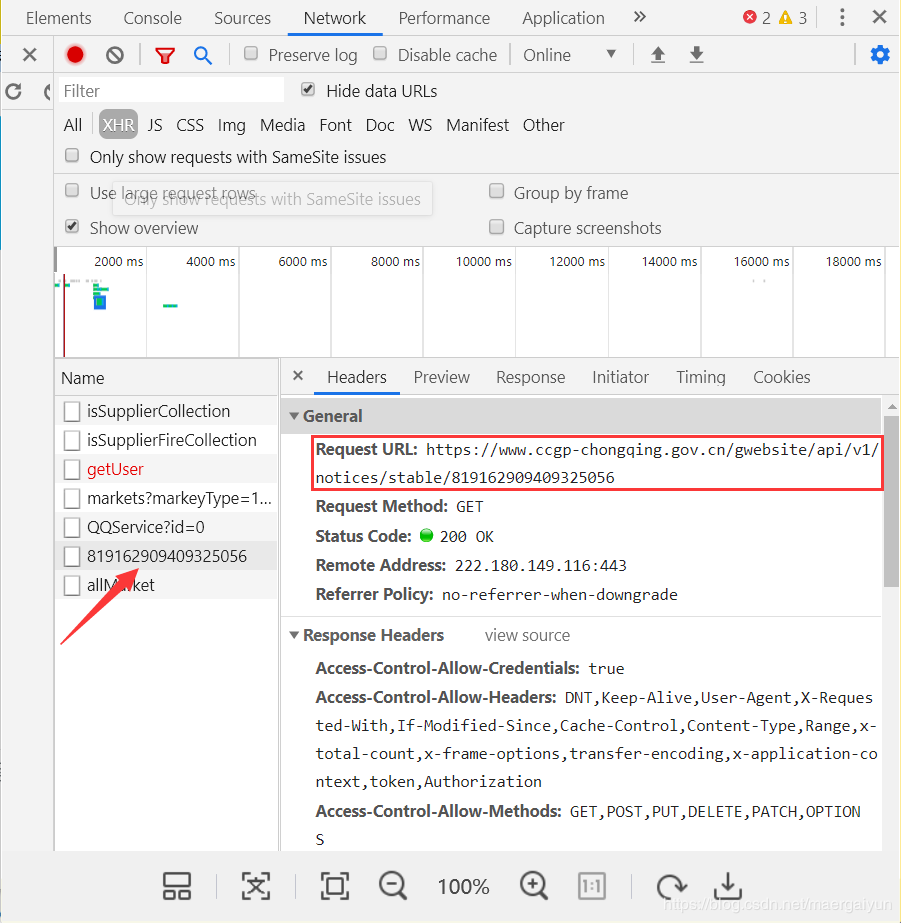
同样,我们把它放在 JSON 格式显示工具里面查看一下。
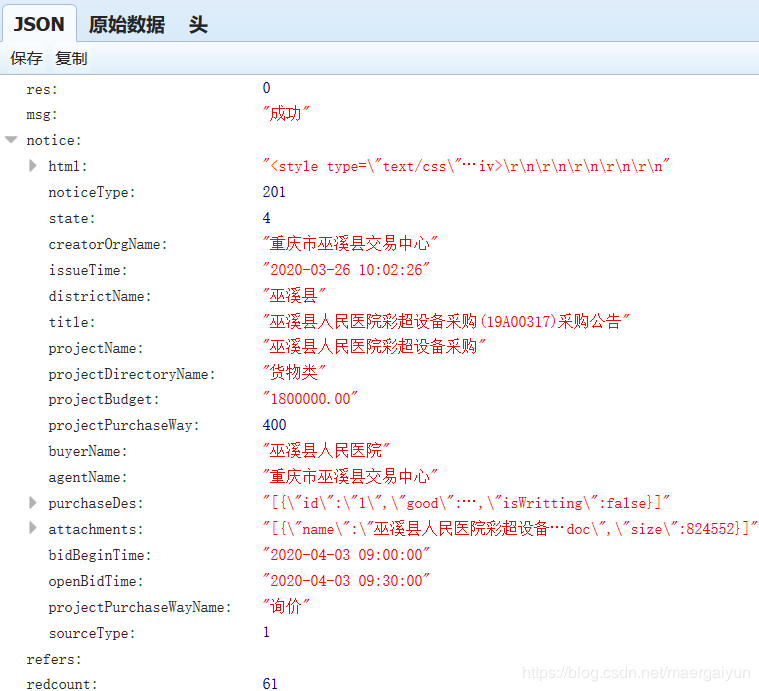
(2)开始采集满足需求的“真网址”。
我们最后想要的数据都在 title 和 purchaseDes 当中。我们在采集这部分数据之前,需要过滤掉不是"采购公告"的数据,另外添加一行 trueurl 的数据。
import json
# 读取过滤之前的数据
def getdata():
f = open(r"F:./urls.json", encoding="utf-8")
data = f.read()
f.close()
urls = json.loads(data)
return urls
# 过滤数据
def getgrepurls(grepurls):
urls = getdata()
for p in urls:
if p["projectname"][-4:] == "采购公告" :
p["trueurl"] = "https://www.ccgp-chongqing.gov.cn/gwebsite/api/v1/notices/stable/" + p["id"]
grepurls.append(p)
if __name__ == "__main__":
grepurls = []
getgrepurls(grepurls)
f = open("grepurls.json", "w", encoding="utf-8")
f.write(json.dumps(grepurls, ensure_ascii=False, indent=4) + "\n")
f.close()
打开 grepurls.json 文件,检查过滤的结果。

(3)最后开始爬取每个公共的项目名称和采购物资。
特别注意的是,第一次过滤后得到的虽然都是采购公告,但是部分采购公告的页面布局不同,不包含采购物资的内容。因此还需把这部分数据剔除!
import requests
import json
# 读过滤之前的数据
def getdata1():
f = open(r"F:./grepurls.json", encoding="utf-8")
data = f.read()
f.close()
grepurls = json.loads(data)
return grepurls
# 第二次过滤,过滤不包含分包内容的采购公告
def getnewurls(headers):
grepurls = getdata1()
newurls = []
for i in grepurls:
trueurl = i["trueurl"]
response = requests.get(trueurl, headers=headers)
trueurldata = response.content.decode()
json_trueurldata = json.loads(trueurldata)
try:
purchaseDes = json_trueurldata["notice"]["purchaseDes"]
except KeyError as e:
print("%s不包含分包内容信息!"%i["projectname"])
else:
newurls.append(i)
return newurls
# 读第二次过滤的数据
def getdata2():
f = open(r"F:./newurls.json", encoding="utf-8")
data = f.read()
f.close()
newurls = json.loads(data)
return newurls
# 保存项目名称和采购物资
def getcontent(headers):
newurls = getdata2()
contents = []
for i in newurls:
good = ""
trueurl = i["trueurl"]
response = requests.get(trueurl, headers=headers)
trueurldata = response.content.decode()
json_trueurldata = json.loads(trueurldata)
purchaseDes = json_trueurldata["notice"]["purchaseDes"]
json_purchaseDes = json.loads(purchaseDes)
for p in json_purchaseDes:
content = {}
content["projectname"] = i["projectname"]
for g in p["good"]:
good = g["title"] + "," + good
content["good"] = good
print(content)
contents.append(content)
return contents
if __name__ == "__main__":
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
}
newurls = getnewurls(headers)
f = open("newurls.json", "w", encoding="utf-8")
f.write(json.dumps(newurls, ensure_ascii=False, indent=4) + "\n")
f.close()
contents = getcontent(headers)
f = open("contents.json", "w", encoding="utf-8")
f.write(json.dumps(contents, ensure_ascii=False, indent=4) + "\n")
f.close()
打开 contents.json 文件,查看最后的结果。

本系统是博主第一个完整开发的爬虫系统,系统中还存在有待改进的地方,例如:指定爬取发布日期区间的公共,数据的展示效果略微粗糙,数据还需提纯等。希望日后加以完善。
作者:马尔盖云