《用python写网络爬虫》第二章,看不懂你打我。
1、本章学习路径:正则表达式–>Xpath–>BeautifulSoup
2、Requests最核心的两个类:
request(对HTTP请求的封装) response(对HTTP返回结果的封装)一次HTTP请求其实就是:(1)构造request类、(2)发送HTTP请求、(3)等待服务器并获得服务器响应结果、(4)解析响应结果,并构造response类。
以上这四个步骤,只需一行代码即可实现:
response=request.get(url)通过requests构造一个请求对象,并通过get函数发送HTTP请求,最后响应结果保存于response对象中。(如果很多名词看不懂,不要急,只要先把这段文字理解了,然后慢慢看就会懂了)
3、正则表达式:是处理字符串的强大工具,可实现字符串的检索、替换、匹配验证等都不在话下。正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
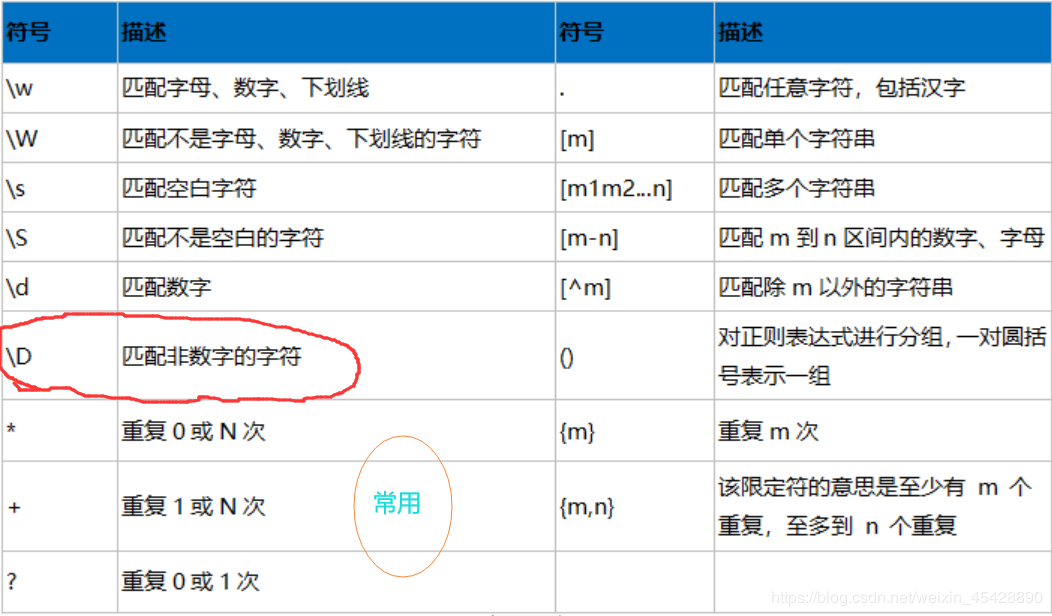
4、正则表达式的重要符号:
 5、网络爬虫关于正则表达式:
5、网络爬虫关于正则表达式:
下面给大家举例方便理解网络爬虫关于正则表达式是如何实现的
第一个例子:(匹配任意字符,一个字符的前几次)
import re #导入正则表达式的库
a="xz123"
b=re.findall("x.",a)#参照前面的点(.)的含义,代表匹配任意字符
print(b) #此时的结果为['xz']
c=re.findall("x*",a) #星号(*)的意思是匹配前一个字符0次或者无数次
print(c) #此时的结果为['x','','','','','']
第二个例子:(贪心算法和非贪心算法的比较)
要求:提取C中的i love you
import re
c="dafsdxxixxfd32r43xxlovexxfadgdaxxyouxxg235"
d=re.findall("xx.*xx",c)
print(d)
我们发现c这个字符串中要提取的i love you 中左右两边都有xx.xx,所以考虑可以用贪心算法。
参考上面的==(.*)==的用处:从左右俩边同时搜索,只要满足xx.xx的情况,就提取包围xx.xx里面的全部。所以此时输出的答案为 [‘xxixxfd32r43xxlovexxfadgdaxxyouxx’] 但是此时我们发现输出的答案不是我们所要的,此时我们要的是最小范围,所以考虑到用非贪心算法,参照上面 ==(.*?)==的含义,从左边一边开始搜索发现符合xx.xx的全部提取出来存储在一个列表中。
import re
c="dafsdxxixxfd32r43xxlovexxfadgdaxxyouxxg235"
d=re.findall("xx.*?xx",c)
print(d)
此时的打印结果为[‘xxixx’,‘xxlovexx’,‘xxyouxx’]
我们发现此时我们不想要xx,我们只想要xx里面的字符串,此时用到==()==(参考前面网络爬虫关于正则表达式的用法)
import re
c="dafsdxxixxfd32r43xxlovexxfadgdaxxyouxxg235"
d=re.findall("xx(.*?)xx",c)
print(d)
此时的打印结果就是我们需要的拉~,记住==(.?)==是网络爬虫中常用的表达式!!!,小可爱们可以思考一下,如果我们需要爬取网页里面的内容,只需把d=re.findall("xx(.?)xx",c)里面的c改为需要爬取的网址就可以拉,这就是爬虫的来源呀!
6、Python中的Re模块:
re.findall函数,用于匹配所有符合规律的内容返回包含结果的列表,语法为:re.findall(pattern,string,flags=0)
pattern---->匹配的正则表达式
string---->要被查找的原始字符串
flags—>标志位,用于控制正则表达式的匹配方式:如区分大小写,多行匹配等。
re.search函数,扫描整个字符串并返回第一个成功的匹配,要用re.search(),re.group()来获取具体值。语法为:re.search(pattern,string,flags=0)
pattern---->匹配的正则表达式
string---->要匹配的字符串
flags—>标志位,用于控制正则表达式的匹配方式:如区分大小写,多行匹配等。
-re.sub函数,用于替换字符串中的匹配项,返回替换后的值。语法为:re.sub(pattern,repl,string,count=0,flags=0)
pattern—>匹配的正则表达式 repl—>替换的字符串,也可以为一个函数 string—>要被查找替换的原始字符串 count—>匹配后替换的最大次数,0默认替换所有 flags—>标志位,用于控制正则表达式的匹配方式:如区分大小写,多行匹配等。re.sub的例子:提取下面的号码
import requests
import re
strl="我的电话号码是:010-6737-2224344,请保存好!"
result=re.sub("\D"," ",strl)
#\D代表的是匹配非数字的字符,替换成“ ”空来表示,也就是把号码提取出来了
print(result)
7、使用Re模块实现豆瓣电影的爬取A
(1)下载requests安装:
Windows:pip install requests
linux:pip install requests
(2)获取豆瓣电影的网页代码
import requests #导入库
import re #使用re模块执行我的正则表达式
#从“豆瓣电影520”中获取页面
html=requests.get("https:movie.douban.com/top250")
print(html) #打印出来的结果的是
#想要打印网页中代码,只需要打印:print(html.text)即可
(3)使用re查找所有电影的评价人数A。
在上面基础上,阅读html找到评价人数的代码,但是太low,所以介绍大家使用chrome浏览器(开发者工具,快速定位想要的代码)首先按下F12键如果按F12不行,就在此页面单击右键找到查看元素下面的步骤就一样啦(开发者工具)继续按F5进行刷新(对应的所有的请求与响应都被捕捉,左下角有个尖用于选择element(元素),点击选中评价人数就在就会自动定位到html代码)
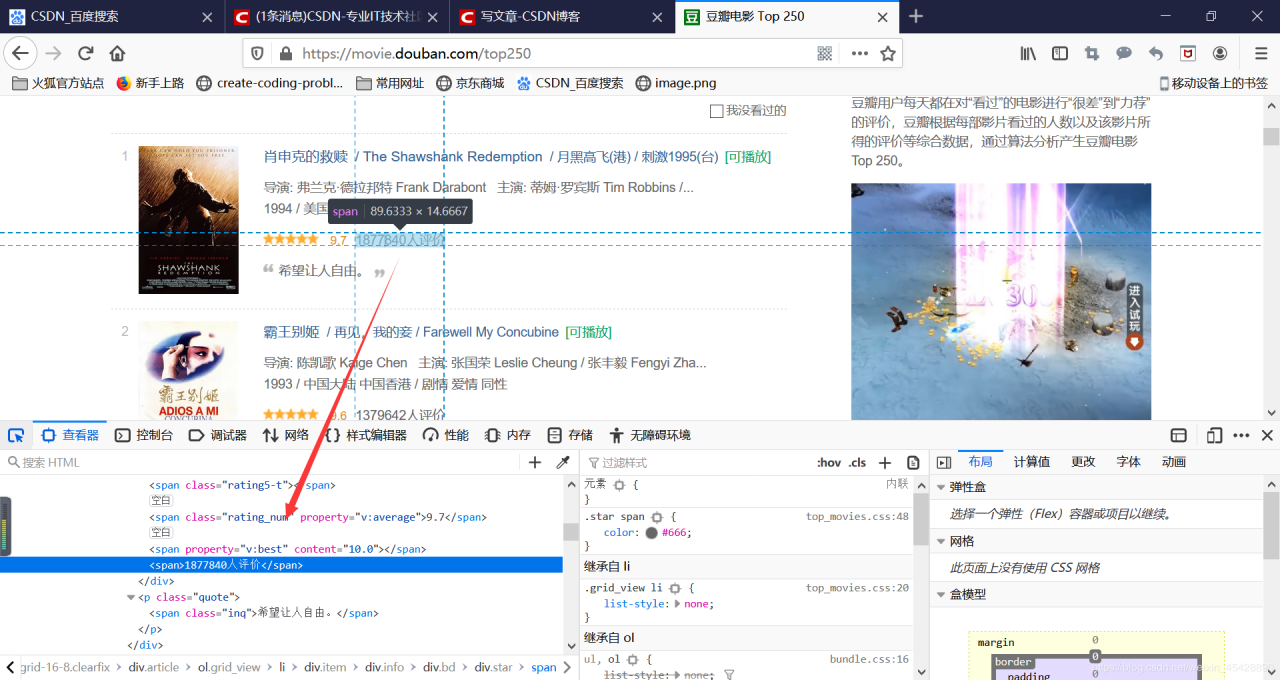 此时找到的代码是(
此时找到的代码是(116758人评价)
import requests
import re
html=requests.get("https:movie.douban.com/top250")
x=re.findall("(.*?)人评价",html.text)
#此处的贪心算法是唯一定位
输出的结果就是网页电影评价人数:[‘116785’,‘8554079’,…]
(4)使用re查找所有电影的评价人数B。(在豆瓣电影中,我只想要提取出数字,用正则表达式如何实现?)
import requests
import re
html=requests.get("https:movie.douban.com/top250")
#电影评分
star=re.findall("(.*?)",html.text)
#电影名称
name=re.findall("(.*?)",html.text)
print(star,name)
电影的评分和名称就都出来了,自己去试试吧~
Xpath
(1)xpath(XML path Language,即XML路径语言)是一门在XML文档中查找信息的语言,是一种解析语言。
(2)常用的Xpath路径表达式:
nodename —>选取此节点的所有子节点 / —>从根节点选取(描述绝对路径) // —>不考虑位置,可选取页面中所有子孙结点(如//div//a 此时的a不一定是子节点) . ---->选取当前结点(描述相对路径) … ---->选取当前节点的父节点(描述相对路径) @属性名 ---->代表提取属性的值 text() ----->获取元素中的文本节点(3)带谓语的Xpath的路径表达式:
//div[@id=‘content’] —>选取属性id为content的div元素 //div[@class] —>选取所有带有属性class的div元素 //div/p[1]/text() —>选取div节点中的第一个p元素的文本 //div/p[2]/text() —>选取div节点中的第二个p元素的文本 //div/p[last()]/text() —>选取div节点中的最后元素的文本(4)使用Xpath提取数据的例子:
from lxml import etree #导入Xpath的库
import requests
import re
html=requests.get("https:movie.douban.com/top250",html.text)
selector=etree.HTML(html) #理解为一个选择器
title=selector.Xpath("/html/head/title/text()").[0].strip("\n")
#/代表从根节点开始,后面加上.[0]是因为全部放进了一个列表里面,取第一元素,后面是为了去除\n符号,得到干净的电影标题
name=selector.Xpath("//div[@class="hd"]/a/span[1]/text()").[0]
#a/span[1]/text()代表着a目录下第一个span节点
print(name,title)
BeautifulSoup介绍:
BeautifulSoup提供一些简单的python式的函数来处理导航、搜索、修改分析树等功能,它能自动将输入文档转换为unicode编码,输出文档转换为UTF-8编码
BeautifulSoup还提供了CSS选择器,使用CSS选择器的时,只需调用select()方法,传入相应的CSS选择器
多线程
python内置了threading 模块,用于实现多线程功能。
因为我是使用Xpath来爬取,所以后面会补充一个完成的Xpath爬虫代码。这里的文档是介绍知识然后写代码方便理解,如果那里有问题可以联系我~~
作者:想要考中科大的袁仁斌