网络爬虫——实用框架Scrapy 从入门到精通第一天
没有看过前面基础的同学需要先看下前面的基础,如下链接:
一、网络爬虫——正则表达式
二、网络爬虫——XPath表达式
三、网络爬虫——Urllib模块实战项目(含代码)爬取你的第一个网站
四、网络爬虫——项目实战(爬取糗事百科所有文章)
五、络爬虫——实战项目2(爬取某社区所有论文,含代码)
代码代写(实验报告、论文、小程序制作)服务请加微信:ppz2759
Scrapy模块是一个非常常用的爬虫框架模块,我们使用Scrapy可以做到快速的创建爬虫项目。也是接下来学习的基础:唯一的缺点就是安装起来比较麻烦,下面为大家介绍安装的方式:
二、Screpy模块安装这一步真的非常难,我帮大家整理了一下,其中的细节还要注意,一步错,步步错哇
在下载的时候网络不好容易下载失败,所以建议开一个VPN,在下载文件比较快。
1、升级pip:进入cmd输入python -m pip install --upgrade pip等待即可
2、安装wheel:进入cmd输入pip install wheel等待即可
3、下载安装lxml:(点我下载)大家在这里面找到对应的文件下载:Ctrl+F lxml
4、下载安装Twisted:(点我下载)大家在这里面找到对应的文件下载:Ctrl+F Twisted
5、安装scrapy:进入cmd输入 pip install scrapy
6、下载安装pywin32:(点我下载)大家在这里面找到对应的文件下载:Ctrl+F pywin32
所有点我下载的还需要加上这一步(以lxml为例子)
在命令行输入pip install lxml -3.7.6-cp……你下载的完整名字,不是缩写lxml
这个网站中cp代表python版本;win32是32位 win64就是64位
记得下载对应版本(命令行输入python可以查看python版本)
创建爬虫通常使用命令scrapy genspider -t base 爬虫名 想要爬取网页的域名如baidu.com
| 常用命令 | 作用 | 用法 |
|---|---|---|
| startproject | 创建爬虫项目 | scrapy startproject 项目名 |
| genspider -l | 查看当前有哪些爬虫模板 | scrapy genspider -l |
| genspider -t 模板 爬虫名 | 基于爬虫模板创建爬虫 | scrapy genspider -t 模板 爬虫名 域名 |
| crawl | 运行爬虫 | scrapy crawl 爬虫名 |
| list | 查看当前有哪些爬虫 | 创建爬虫项目 |
接下来准备好cmd命令行使用cmd命令
d: #进入D盘
cd 微信公众号:骄傲的程序员 #进入我们指定的文件夹
scrapy startproject pachong #创建爬虫项目
如下图所示创建成功爬虫项目!

我们也可以在我们电脑的D:看到
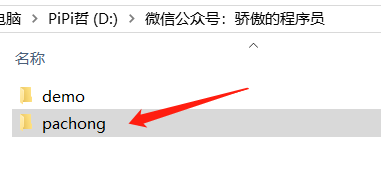
单单有项目是不行的,还要有爬虫文件,接下来生成爬虫文件:
scrapy genspider -t base first dangdang.com
接下来就可以快乐的写代码啦!
快点来进入项目实战把!实战项目实时更新
| 文件/或文件夹 | 作用 |
|---|---|
| spiders | 存放爬虫文件 |
| scrapy.cfg | 配置文件 |
| init.py | 初始化文件 |
| items.py | 定义爬取信息 |
| middlewares.py | 中间建 |
| pipelines.py | 爬去内容之后的处理 |
| settings.py | 总体的设置信息 |
这篇文章真是耗尽了我的耐心2333~
希望大家喜欢,多多支持,谢谢大家

作者:程序员小哲