搞个好玩的东西,爬虫爬取网络流行语录,并通过python自动发送给qq好友,实现有技术的刷屏哈哈。
首先我们需要爬虫的模块函数and python的win32库。
这里我们以郭老师语录为例
import win32gui
import win32con
import win32clipboard as w
#抓取数据
import requests
import time
import random
from bs4 import BeautifulSoup
上面三个是用来操纵qq窗口的,下面三个是用来爬取数据的。
我们首先爬取数据。
百度郭老师语录,这里我建议朋友们在爬取简单数据的时候分为两个函数模块写,分别是het_html和get_data,这样哪里出bug会很清楚。
代码:
def get_be(url,data=None):#抓取html
header={
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
time=random.choice(range(80,100))#防止被检测到为爬虫
rep=requests.get(url,headers=header,timeout=time)
rep.encoding="utf-8"
return rep.text
def get_data(htmltext):
a_list=[]
bs=BeautifulSoup(htmltext,"html.parser")#python的内置标准库
body=bs.body
data = body.find('div', {'class':'icontent'})
p=data.find_all('p')
for line in p:
a_list.append(line.string)
return a_list
这两个函数,我们只需要给他一个主函数就可以获取我们呢需要的信息,这里的参数都是在查找的页面找到的,如下:
在这里我获取了头部信息
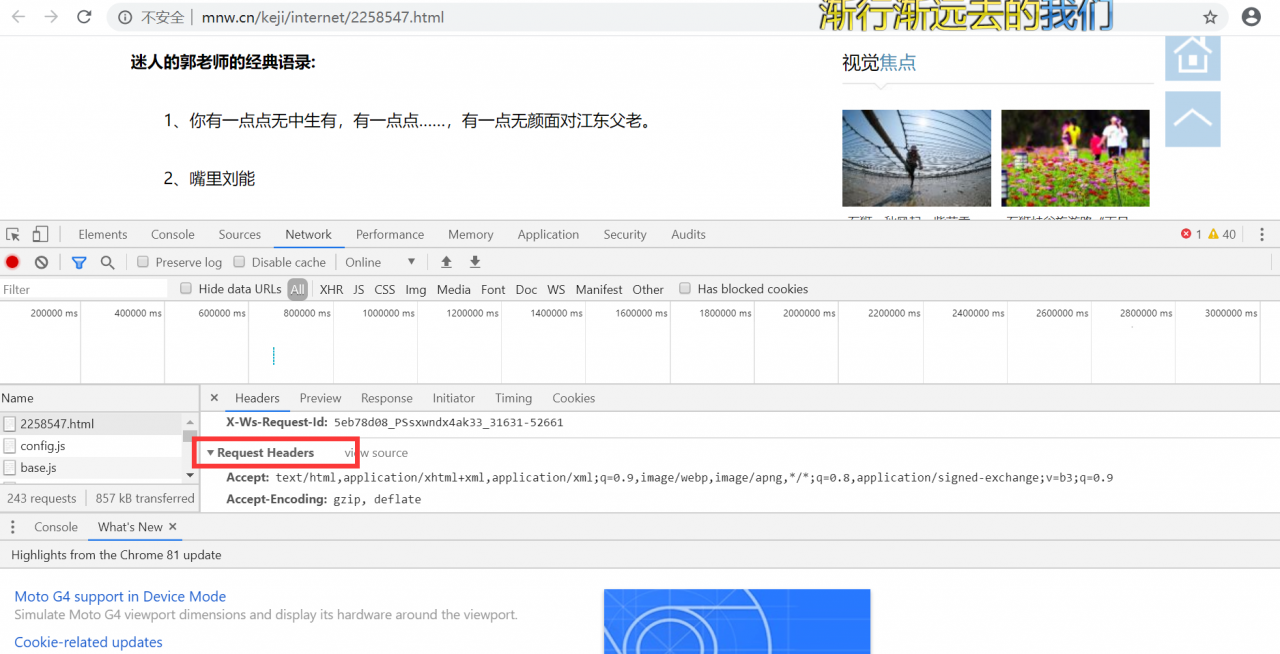 原创文章 46获赞 51访问量 4345
关注
私信
展开阅读全文
原创文章 46获赞 51访问量 4345
关注
私信
展开阅读全文
作者:才疏学浅的ksks14