经典网络结构总结--ResNet系列
论文:Deep Residual Learning for Image Recognition
Motivation:网络越深,能获取的信息越多,而且特征也越丰富。但是根据实验表明,随着网络的加深,优化效果反而越差,测试数据和训练数据的准确率反而降低了(网络退化)。为了让更深的网络也能训练出好的效果,何凯明大神提出了一个新的网络结构——ResNet。这个网络结构的想法主要源于VLAD(残差的想法来源)和Highway Network(跳跃连接的想法来源)。
ResNet Block

残差学习模块包括identity mapping和residual mapping,其中前者指的是x本身的映射,后者为残差映射即F(x)。
残差学习为何有效?
设残差模块的输出为H(x)=F(x)+x,对于普通网络其输出为H(x)。假设网络达到了某个深度的最优状态,再继续增加深度就需要考虑下一层网络也必须达到最优状态,否则增加深度就会使网络退化;对于添加了残差学习的网络,在同样的情况下,只需要令F(x)=0即可,因为上层输出的x是最优解,那么额外增加的网络层的输出H(x) = 0 + x =x,可以视为增加层数起码不会导致网络退化。
BottleNeck Block

另外,作者还提出了bottleneck block来减少计算量。
论文:Densely Connected Convolutional Networks
Motivation:不从深度和宽度的角度优化网络结构,而是从特征的充分利用这一角度来对resnet进行改进。 dense block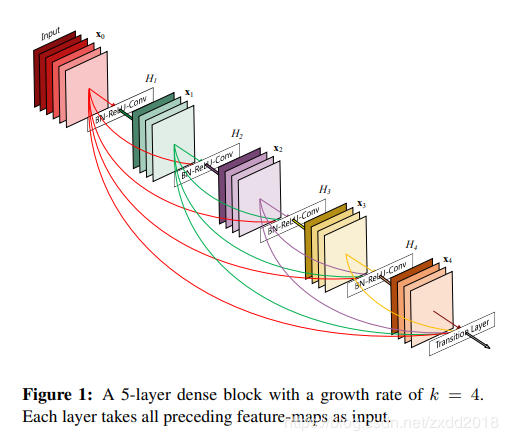 优点:缓解了梯度消失问题,加强了特征传播,鼓励特征重用,并大大减少了参数的数量。(得益于密集连接特性)
ResNeXt
优点:缓解了梯度消失问题,加强了特征传播,鼓励特征重用,并大大减少了参数的数量。(得益于密集连接特性)
ResNeXt
论文:Aggregated Residual Transformations for Deep Neural Networks
改进点:在ResNet的基础上引入group convolution,相当于在残差模块中加入了inception中的拓扑结构,在不增加参数量的情况下有更高的准确率。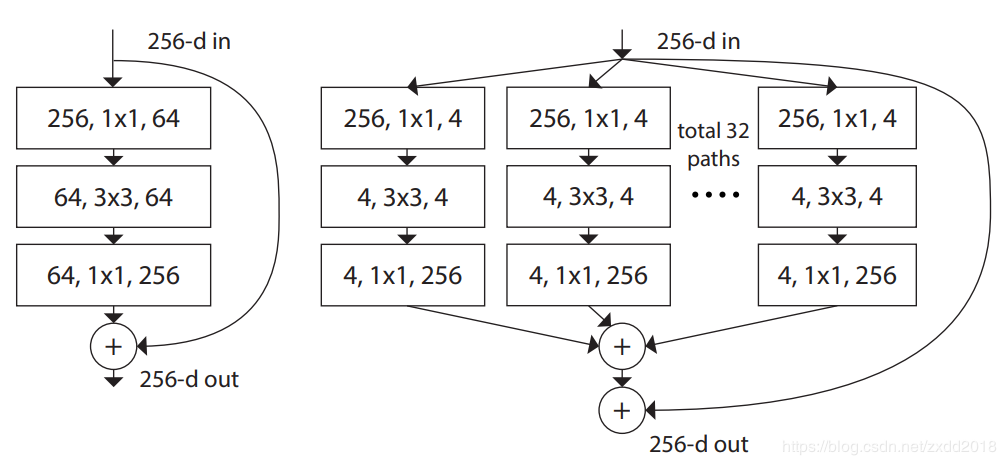 group convolution
group convolution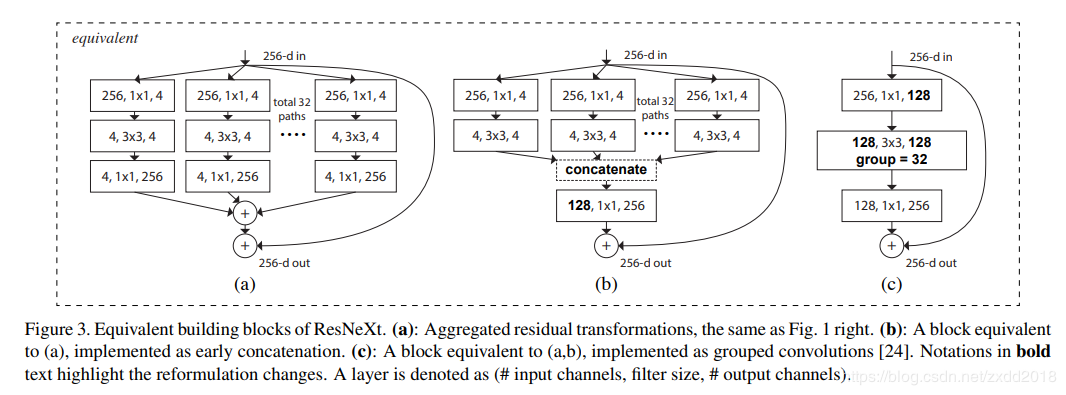 WideResNet
WideResNet
论文:Wide Residual Networks
改进点1:在卷积之间加入dropout,获得提升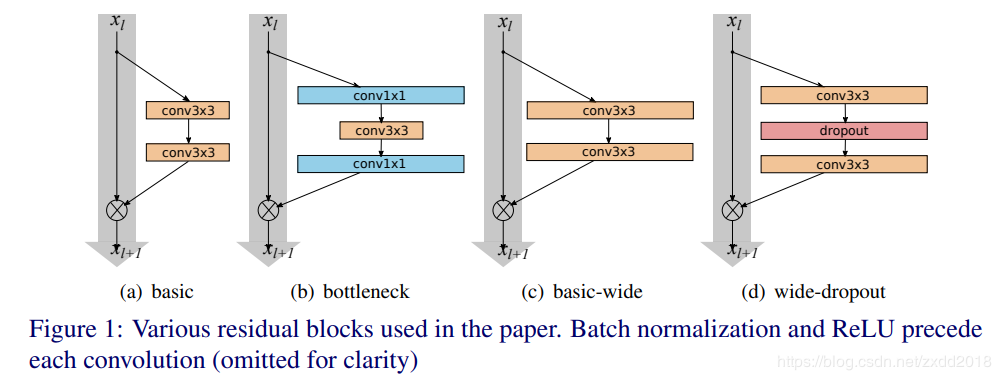 改进点2:增加网络的宽度(k表示扩宽倍数)
改进点2:增加网络的宽度(k表示扩宽倍数)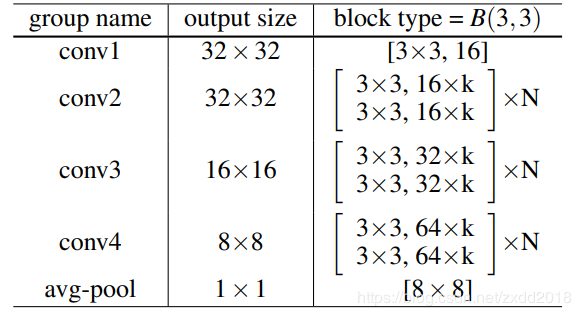 ResNet v2
ResNet v2
论文:Identity Mappings in Deep Residual Networks
改进点:pre-activation
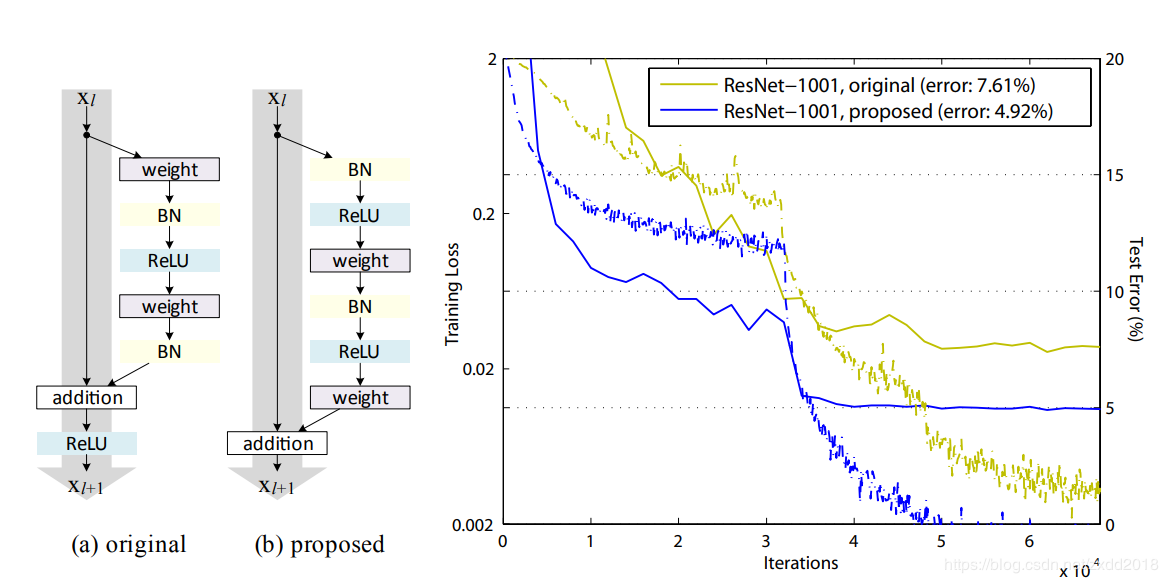
作者:有时候。