实践篇 | 推荐系统之矩阵分解模型

导语:本系列文章一共有三篇,分别是
《科普篇 | 推荐系统之矩阵分解模型》
《原理篇 | 推荐系统之矩阵分解模型》
《实践篇 | 推荐系统之矩阵分解模型》
第一篇用一个具体的例子介绍了MF是如何做推荐的。第二篇讲的是MF的数学原理,包括MF模型的目标函数和求解公式的推导等。第三篇回归现实,讲述MF算法在图文推荐中的应用实践。下文是第三篇——《实践篇 | 推荐系统之矩阵分解模型》,敬请阅读。
本文是MF系列文章中的最后一篇,主要讲的是MF算法在图文推荐中的应用实践。无论是在召回层还是精排层,MF都有发挥作用。在召回层,MF既可以做基于内容的召回,也可以做基于行为的召回,并且相比于其他召回算法,MF有着自身独到的优势。在精排层,MF可以用来对分类变量做embedding,产生具有判别性的低维稠密向量,供排序模型使用,提升排序的效果。
推荐系统通常有两层:召回层和精排层。召回层负责从数以百万的物品中快速地找到跟用户兴趣匹配的数百到数千个物品,而精排层负责对召回的物品打分排序,从而选出用户最感兴趣的top K物品。召回层在为精排层缩小排序范围的同时,也决定了推荐效果的上限。如果召回的内容不够准确,再厉害的排序模型也无法返回一个准确的推荐列表给用户。因此召回层很重要。常用的召回方法可以分为基于内容的召回和基于行为的召回。两种召回方法各有自己的优缺点,相互补充,共同提升召回的质量。
1.1基于内容的召回
基于内容的召回通过计算“用户-文章”或“文章-文章”的内容相似度,把相似度高的文章作为召回结果。内容相似度的计算仅使用内容数据。文章的内容数据有标签、一级分类、二级分类、正文、标题等,用户的内容数据就是用户的画像。通过用向量表示内容数据,计算出内容相似度。对于内容数据中的分类变量,可以对其one/multi-hot向量直接计算余弦相似度,也可以先对其做embedding,然后再计算余弦相似度。
基于内容的召回方法优点是可以召回时新文章。因为无论文章有多新,我们都可以获取到其内容数据,从而能计算内容相似度进行召回。缺点是召回内容可能会走向两个极端,比如用正文或标题的embedding可能会召回内容很相似的文章,从而降低了推荐的多样性。如果用一级分类或二级分类召回,粒度又太粗,可能会召回不太相关的内容,从而降低了推荐的准确性。
1.2基于行为的召回
基于行为的召回就是通过计算“用户-文章”或“文章-文章”的行为相似度,把相似度高的文章作为召回结果。行为相似度的计算仅使用用户行为数据。由于同一个用户在一段时间内的兴趣相对比较固定,点击的文章之间会有一定程度的相关性,所以从用户的行为数据中也能学到文章之间的相似性,即行为相似性。
计算行为相似度的经典方法是使用jaccard相似度公式或者cosine相似度公式。比如,文章A 和文章B 的行为相似度可由如下公式计算:
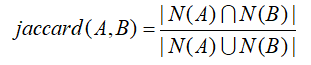
或
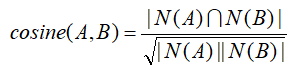
其中,N(A )、N(B )分别表示阅读过文章A 和文章B 的用户构成的集合时,|S |表示集合S的元素个数。当越多用户同时读过文章A 和文章B 时,A 和B 的相似性越高。
此外,还可以把行为数据表示为评分矩阵或共现矩阵,通过矩阵分解的方法把用户和文章都向量化,从而计算出“用户-文章”或“文章-文章”的余弦相似度。
基于行为的召回方法优点是能召回内容上不完全相似,但用户又感兴趣的文章,也就是既有相关性,又有多样性。因为用户阅读的文章会在自己的兴趣范围内发散开来,不会一直阅读几乎一样的内容,因此,用这种行为数据计算出来的相似文章既有相关性,又有一定程度的多样性。此外,由于行为相似度反映了大部分用户的行为习惯,更容易切中用户的需求,因此在点击率等指标上往往会比基于内容的召回更高。缺点是不能召回最新的文章,因为行为数据的产生需要时间,计算行为相似度也需要时间,在这些时间里涉及到的新文章是没办法用这种方法召回的。我们只能隔一段时间取最新的行为数据重新计算一次,也就是只能做到准时新召回。此外,基于行为的召回可能会出现假相关,即召回热度高但不相关的文章。
由于两种召回方法各有自己的优缺点,所以在实际应用中一般是采用多路召回的方式,相互补充,取长补短,最后汇总在一起给排序模型做精排。
矩阵分解既可以做基于内容的召回,也可以做基于行为的召回。无论是哪种类型的召回,矩阵分解方法都有着自己的优势。下面将分别介绍基于内容和基于行为的召回是如何应用矩阵分解的,以及它的优势所在。
2.1基于内容的MF召回
在图文推荐场景下,item是文章,文章的内容有标签、一级分类、二级分类、正文、标题等。其中,正文内容最为丰富。我们用文章正文作为语料库,分词后通过word2vec学习出每个词的词向量,对于每篇入库的文章,我们都可以用加权词向量的方法得到它的word2vec向量。在某一时刻,我们的文章库中有M 篇文章,这M 篇文章的向量就构成了一个文章矩阵,记为
其中yi 为第i 篇文章的向量。记用户u 的历史行为数据为
其中rui 表示用户u 对第i 篇文章是否有点击,0表示没有点击,1表示有点击。通过求解如下的增量矩阵分解模型,我们可以得到用户u 的向量xu :
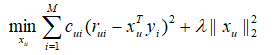
其中
α和λ
为超参数。要强调的是,这里的Item矩阵就是文章矩阵,是事先用word2vec计算好的,在目标函数里被当成是常数看待,要求解的只有xu ,它的解析解为
其中,
![]()
为对角阵,I 为单位矩阵。下面的图1描述了这一增量计算过程
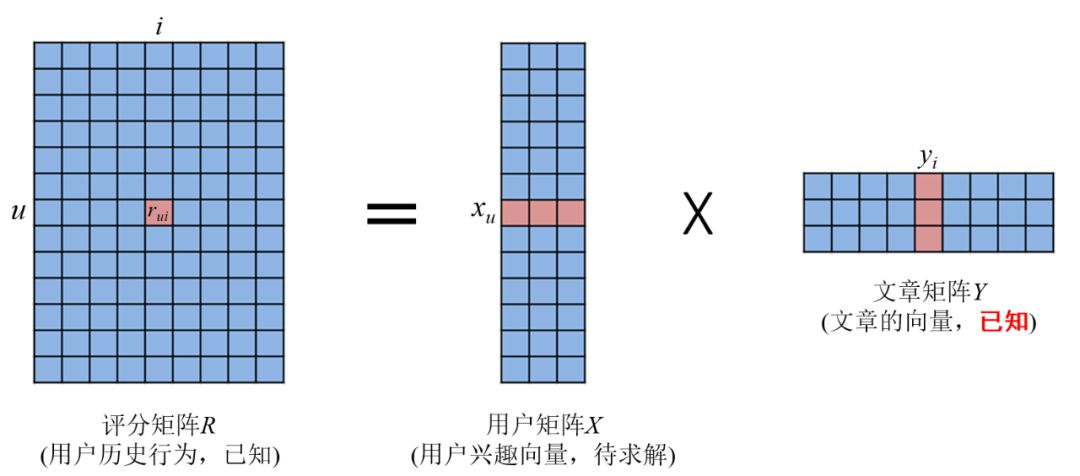
图1
计算出xu 后,将xu 和每一个yi 计算一下内积,把内积最大的top K 篇文章作为召回结果返回。在工程实现上,这种需要从Y 中快速找出top K 个与xu 最相似的向量问题,通常都可以交给向量索引系统去做,例如Faiss。
由于这里用到的Y 是从文章语料库学出来的内容向量,而不是从行为数据中学出来的,因此,这里的MF召回属于基于内容的召回。下面的图2给出了基于文章word2vec向量的MF召回流程图。
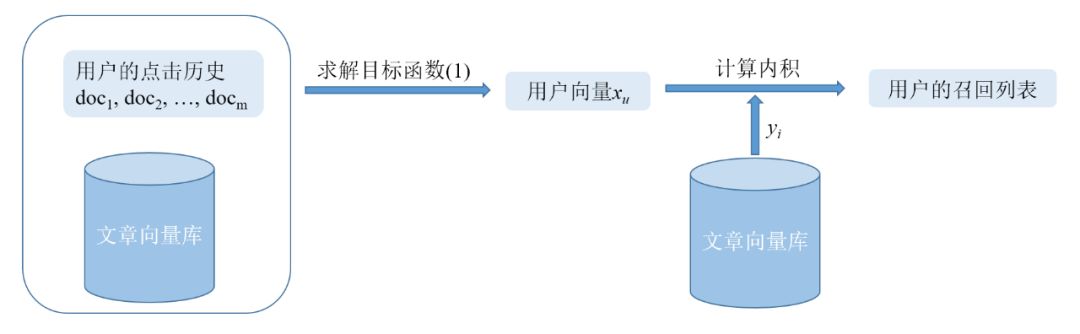
图2
与基于邻域的内容召回方法(用历史点击文章的相似文章作为召回结果)相比,MF的优势在于它能提高召回内容的准确性。在本系列的原理篇文章中,我们通过公式推导得出了一个结论,就是基于邻域的方法可以看成是MF的一种特例。两者的主要区别在于,在基于邻域的算法里,两篇文章的相似度对所有用户都是一样的,而在MF中,两篇文章的相似度对不同用户是不一样的。也就是MF考虑得更细,因此会比基于邻域的方法更准确。下文将会给出基于内容的最近邻召回方法和MF召回方法的在线实验对比数据,从实验中我们也能明显看出MF召回比基于邻域的内容召回方法要更好。
2.2基于行为的MF召回
由于同一个用户在一段时间内阅读的文章具有一定程度的相关性,利用行为数据的这个特点,我们以一个大小固定的滑动时间窗口扫描训练样本中所有用户的历史点击文章序列,构造一个文章跟文章的共现矩阵R={rij },其中rij 表示以文章i 为中心的滑动窗口中,文章j出现的次数。对矩阵R的每一行做截断,只保留数值最大的K 个非零的rij ,其余rij 置零。记xi 为文章i 位于滑动窗口中心时的向量,yi 表示文章i 不在滑动窗口中心时的向量,可构造矩阵分解模型如下:
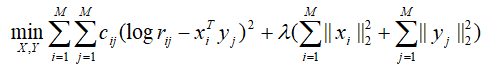
其中,
![]()
α和
λ为超参数。
解这个目标函数,可以得到每篇文章的向量xi 和yi ,用的时候我们只用xi 。有了文章的向量,我们就可以计算文章之间的相似度,为每篇文章找到top K相似文章列表,根据用户历史点击文章关联出相似文章作为召回结果。
相比于用jaccard公式或余弦公式计算文章间的行为相似度,MF方法的优势在于它的泛化性。jaccard和余弦公式都是基于已观测到的行为数据,如果文章A 和文章B 没有同时出现在任何一个用户的阅读历史中,它们是无法应用jaccard或余弦公式计算相似度的。用户行为数据的稀疏性限制了可计算相似度的文章范围。MF则克服了这个问题,它用整个行为数据集学出了每篇文章的向量,因此任何两篇文章的行为相似度都是可计算的。
那些隐藏在数据中没有被直接观测到的关系,可以在向量化每篇文章之后被观测到。比如说,我们观测到有用户阅读了文章A 和文章B,也有用户阅读了文章B 和文章C,但没有用户同时阅读A 和C,这种情况下,jaccard可以计算出A 和B 的相似度,B 和C 的相似度,但却无法计算A 和C。而事实上,A 和C 很有可能是相似的,只是它们的相似关系没有直接体现在观测数据里。MF通过把A,B,C 都向量化以后,A 和C 的相似关系就被揭示出来了,所以MF方法有更好的泛化性。它能召回更多相关的文章,同时也会在一定程度上提高召回文章的多样性。
基于行为的MF召回有两点值得探讨的:
(1)为什么不直接分解“用户-文章”的行为矩阵,而是分解“文章-文章”的共现矩阵?
我们从离线实验的结果中发现,分解“用户-文章”矩阵得到的文章向量有个缺点,对于点击数较多的文章,其向量每一维的绝对值会比较大,对于点击数较少的文章,其向量每一维的绝对值会比较小,因此这种向量不适合拿来计算文章间的相似度。实际上,点击数少的文章学到的向量已经是不准确的了。实验时也观察到,用这种文章向量计算相似度的话,很多文章都会跟最热的那些文章相似。分解“文章-文章”的共现矩阵就不会出现这个问题,一是因为矩阵每行的非零元个数最多不超过K 个,得到的文章向量的分量波动不会那么大,二是因为“文章-文章”矩阵比“用户-文章”矩阵更稠密,学到的向量会更准确。
(2)分解“文章-文章”共现矩阵的依据是什么?
在实践中,已经有不少人把用户的行为数据当做是文本数据来用,并取得了成功。具体做法是把用户的点击序列当成是一个文本,序列中的每个item当做是一个词。通过做这� �转换,就可以使用word2vec[15,16]来学出每一个item(词)的向量了。那跟MF又有什么关系呢?因为有一个跟word2vec类似的学习词向量的方法,叫做GloVe[17],就是通过分解“词-词”的共现矩阵学习词向量的,只是word2vec用的损失函数是交叉熵,GloVe用的损失函数是平方损失。虽然GloVe学到的词向量会比word2vec稍差一些,但是GloVe的计算速度比word2vec快很多,比word2vec更适合于需要频繁计算以得到新文章向量的场景。这里MF分解“文章-文章”的共现矩阵,其实就是在用GloVe把行为数据当文本数据,学习文章的向量。
排序模型本质上就是一个二分类的分类器,除了近几年发展起来的各种深度CTR模型[14]以外,实践中用得最多的传统CTR排序模型应该就是LR和GBDT了(p.s. FM[21]可以看成是升级版的LR,XGBoost[19]和lightGBM[20]可以看成是升级版的GBDT)。对于LR和GBDT本身而言,并没有太多的trick,决定效果的关键是特征工程。GBDT相对LR来说,优点是可以做到自动特征交叉,减少了人工构造交叉特征的工作量。在推荐场景下,数据中有很多分类变量,比如文章id,标签id、一级分类、二级分类、地域等,并且有些分类变量取值非常多,比如标签,从几万到几十万都有可能。如果用one-hot或multi-hot来表示这些分类变量,由于维度太高,GBDT会训练得很慢,甚至训练不出来,所以GBDT要用上这些分类变量,就要先对它们做embedding,也就是用低维稠密向量来表示它们。在图文推荐中,产生embedding的方法之一就是MF。
我们记录了每个用户历史点击过的文章id,这些文章id构成了用户画像的一部分,并且可以被看成是一种分类变量,现在要把它们变成一个稠密低维的用户向量xu 来表示用户兴趣。最简单的方法就是求这些历史点击文章的word2vec向量的加权平均,但这样做的缺点是损失的信息太多,导致用户向量不准确。更好的办法是采用矩阵分解模型。记用户的历史行为数据为
其中pui 表示用户u 对文章i 是否有点击,0表示没有点击,1表示有点击。通过求解如下的增量矩阵分解模型,我们可以得到用户的向量xu :
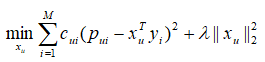
其中,
![]()
α和λ
为超参数,yi 为文章i 的word2vec向量。xu 的求解表达式为
![]()
其中
![]()
![]()
为对角阵,I 为�
�位矩阵。得到用户的向量xu 之后,把xu 作为用户特征,文章的word2vec向量yi 作为文章特征,内积
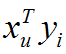
作为用户和文章的交叉特征,训练XGBoost分类模型。离线训练好模型后,在线预测时,文章的word2vec向量yi 可以直接从共享内存中取出,用户向量xu 可以通过上述公式实时计算,内积也实时计算。计算xu 的时间复杂度为O(k3),其中k3 为向量的维度,因此完全能满足在线计算的性能要求。
4.1 MF召回实验
上文提到,MF既可以做基于内容的召回,也可以做基于协同的召回。我们分别对MF的这两种召回做了在线的AB测试,评估的指标是点击数、曝光数和点击率。
4.1.1基于内容的MF召回实验
在这个实验中,对照组用文章正文的word2vec向量计算每篇文章的相似文章,通过用户历史点击文章的相似文章来召回,实验组用的上文中提到的基于内容的MF召回。下面是线上AB测试的结果。其中,黄线是对照组。
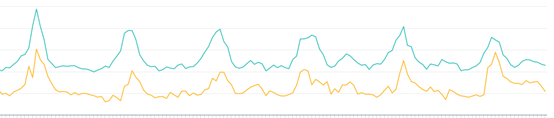
点击率

点击数
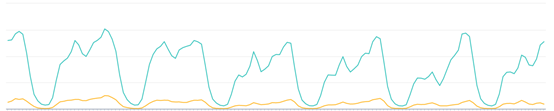
曝光数
可以看到,基于内容的MF召回的点击率、点击数和曝光数都远高于对照组的基于内容的相似召回。这就间接说明了用MF计算用户向量召回的文章,比用memory-based的方式召回内容相似的文章会更准确。
4.1.2 基于协同的MF召回实验
在这个实验中,对照组用jaccard公式计算文章与文章之间的行为相似度,实验组是用MF分解文章的共现矩阵得到文章向量,然后计算文章之间余弦相似度。这两种方法得到每篇文章的相似文章列表后,都是通过用户历史点击文章去关联相似文章的方式来召回。实验结果如下图所示。其中,黄线为对照组。
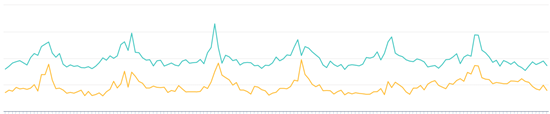
点击率

点击数
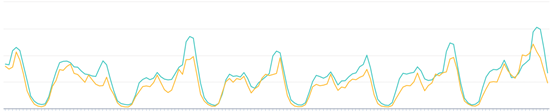
曝光数
可以看到, 在曝光数上,MF和jaccard相差不大,MF稍高。在点击数上,MF明显高于jaccard,所以MF的点击率也明显比jaccard高。同样都是基于协同的召回,MF的线上指标均优于jaccard,这就间接证明了,MF的泛化性比jaccard更好,召回的相似文章更匹配用户的兴趣。
4.2 MF特征用于排序的实验
在这个
实验中,对照组不使用MF特征,实验组在对照组的基础上,添加MF特征,包括MF计算得到的用户向量xu 和交叉特征
![]()
评估算法的指标为线上的点击数、曝光数和点击率。实验结果如下图所示。
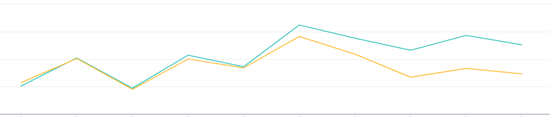
点击率
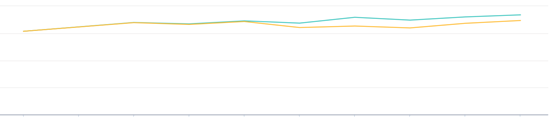
点击数

曝光数
图中的黄线为对照组,绿线为实验组。可以看到,当模型加入MF计算的用户向量和交叉特征之后,点击数、曝光数和点击率都有明显的提升。这个实验表明,用户画像中的分类变量(此处为历史点击文章)被MF转化为低维稠密向量引入到XGBoost后,排序的结果更准确了,从而把更符合用户兴趣的文章推荐给用户,使用户点击变多。
(1)召回方法分为基于内容的召回和基于行为的召回,两类方法各有优缺点,需要多路召回取长补短,相互补充,提高召回的整体质量
(2)MF可以做基于内容的召回,它的优点是比基于邻域的内容召回更准确
(3)MF可以做基于行为的召回,它的优点是比jaccard有更好的泛化性,在召回更多相似item的同时也能提高召回内容的多样性
(4)MF可以把推荐场景中的各种分类变量转化为低维稠密的embedding,适合和GBDT这类方法配合使用,提高排序准确性
[1] 项亮. 推荐系统实践. 北京: 人民邮电出版社. 2012.
[2] Sarwar B M, Karypis G, Konstan J A, et al. Item-based collaborative filtering recommendation algorithms. WWW. 2001, 1: 285-295.
[3] Linden G, Smith B, York J. Amazon. com recommendations: Item-to-item collaborative filtering. IEEE Internet computing. 2003 (1): 76-80.
[4] Koren Y, Bell R, Volinsky C. Matrix factorization techniques for recommender systems. Computer. 2009 (8): 30-37.
[5] Koren Y. Factorization meets the neighborhood: a multifaceted collaborative filtering model. SIGKDD. 2008: 426-434.
[6] Hu Y, Koren Y, Volinsky C. Collaborative filtering for implicit feedback datasets. ICDM. 2008: 263-272.
[7] Mnih A, Salakhutdinov R R. Probabilistic matrix factorization. NIPS. 2008: 1257-1264.
[8] Koren Y. Collaborative filtering with temporal dynamics. SIGKDD. 2009: 447-456.
[9] Pilászy I, Zibriczky D, Tikk D. Fast als-based matrix factorization for explicit and implicit feedback datasets. RecSys. 2010: 71-78.
[10] Johnson C C. Logistic matrix factorization for implicit feedback data. NIPS, 2014, 27.
[11] He X, Zhang H, Kan M Y, et al. Fast matrix factorization for online recommendation with implicit feedback. SIGIR. 2016: 549-558.
[12] Hofmann T. Probabilistic latent semantic analysis. UAI. 1999: 289-296.
[13] Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation. JMLR. 2003, 3(Jan): 993-1022.
[14] Zhang S, Yao L, Sun A, et al. Deep learning based recommender system: A survey and new perspectives. ACM Computing Surveys (CSUR). 2019, 52(1): 5.
[15] Mikolov, Tomas & Chen, Kai & Corrado, G.s & Dean, Jeffrey. Efficient Estimation of Word Representations in Vector Space. Proceedings of Workshop at ICLR. 2013.
[16] Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality. NIPS. 2013: 3111-3119.
[17] Pennington J, Socher R, Manning C. Glove: Global vectors for word representation. EMNLP. 2014: 1532-1543.
[18] Covington P, Adams J, Sargin E. Deep neural networks for youtube recommendations. RecSys. 2016: 191-198.
[19] Chen T, Guestrin C. Xgboost: A scalable tree boosting system. SIGKDD. 2016: 785-794.
[20] Ke G, Meng Q, Finley T, et al. Lightgbm: A highly efficient gradient boosting decision tree. NIPS. 2017: 3146-3154.
[21] Rendle S. Factorization machines. ICDM. 2010: 995-1000.
更多精彩阅读:


科普篇 | 推荐系统之矩阵分解模型

作者:腾讯技术工程