科普篇 | 推荐系统之矩阵分解模型

导语:本系列文章一共有三篇,分别是
《科普篇 | 推荐系统之矩阵分解模型》
《原理篇 | 推荐系统之矩阵分解模型》
《实践篇 | 推荐系统之矩阵分解模型》
第一篇用一个具体的例子介绍了MF是如何做推荐的。第二篇讲的是MF的数学原理,包括MF模型的目标函数和求解公式的推导等。第三篇回归现实,讲述MF算法在图文推荐中的应用实践。三篇文章由浅入深,各有侧重,希望可以帮助到大家。下文是第一篇——《科普篇 | 推荐系统之矩阵分解模型》,第二篇和第三篇将于后续发布,敬请期待。
矩阵分解(Matrix Factorization, MF)是推荐系统领域里的一种经典且应用广泛的算法。在基于用户行为的推荐算法里,矩阵分解算法是效果最好方法之一,曾在推荐比赛中大放异彩,成就了不少冠军队伍。推荐算法发展至今,MF虽然已经比不过各种CTR模型和深度CTR模型,但是它依然在推荐系统中发挥着重要作用,在召回系统和特征工程中,都可以看到它的成功应用。本文是MF系列中的第一篇,用一个简单的例子讲解了MF是如何做推荐的,旨在科普。
推荐系统要做的事情是为每个用户找到其感兴趣的item推荐给他,做到千人千面。下面以音乐推荐为例,讲述矩阵分解是如何为用户找到感兴趣的item的。
1.1 收集数据,构造评分矩阵
矩阵分解算法是基于用户行为的算法,为此我们需要先获取用户的历史行为数据,然后以此为依据去预测用户可能感兴趣的item。下面的图1是我们收集到的用户行为。

图1
如图1所示,我们用一个矩阵来表示收集到的用户行为数据,这个数据集一共有24个用户,9首歌曲。矩阵中第i 行第j 列的数字代表第i 个用户对第j 首歌曲的播放行为,1代表有播放,空白代表无播放(一般用0表示)。比如,用户1播放过“成都”、“董小姐”,用户8播放过“洗白白”和“抓泥鳅”。我们把这个矩阵称为评分矩阵。这里所说的评分不是用户的显式打分,而是指用户是否有播放。用户行为数据有一个特点,就是一个用户的兴趣通常只会分布在少数几个类别上,像这里的用户1到用户7只喜欢民谣歌曲,用户8到用户14只喜欢儿歌,用户15到21只喜欢草原风,用户22只喜欢民谣和儿歌,等等。由于用户一般只会播放少数几首歌曲,因此这个矩阵大部分都是0(空白),是一个十分稀疏的矩阵。
1.2 分解评分矩阵
矩阵分解算法要做的事情就是去预测出矩阵中所有空白处的评分,并且使得预测评分的大小能反映用户喜欢的程度,预测评分越大表示用于越可能喜欢。这样我们就可以把预测评分最高的前K首歌曲推荐给用户了。
简单来说,矩阵分解算法是把评分矩阵分解为两个矩阵乘积的算法,如下图2所示。
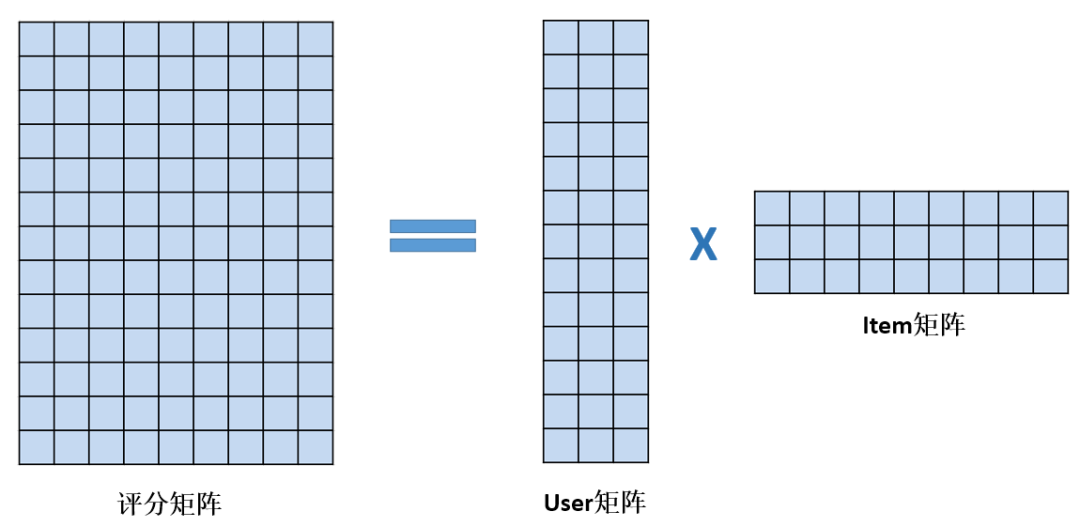
图2
在图2中,等号的左边是评分矩阵,也就是图1的那个矩阵,是已知数据,它被MF算法� �解为等号右边的两个矩阵的乘积,其中一个被称为User矩阵,另一个被称为Item矩阵。如果评分矩阵有n 行m 列(即n个用户,m个item),那么分解出来的User矩阵就会有n 行k 列,其中,第i 行构成的向量用于表示第i 个用户。Item矩阵则有k 行m 列,其中,第j 列构成的向量用于表示第j 个item。这里的k是一个远小于n 和m 的正整数。当我们要计算第i 个用户对第j 个item的预测评分时,我们就可以用User矩阵的第i行和Item矩阵的第j 列做内积,这个内积的值就是预测评分了。
那MF是如何从评分矩阵中分解出User矩阵和Item矩阵的呢?简单来说,MF把User矩阵和Item矩阵作为未知量,用它们表示出每个用户对每个item的预测评分,然后通过最小化预测评分跟实际评分的差异,学习出User矩阵和Item矩阵。也就是说,图2中只有等号左边的矩阵是已知的,等号右边的User矩阵和Item矩阵都是未知量,由MF通过最小化预测评分跟实际评分的差异学出来的。
比如说,在上述音乐推荐的例子中,图1中的评分矩阵可以被MF算法分解为如下User矩阵和Item矩阵的乘积,这里的k 取3。
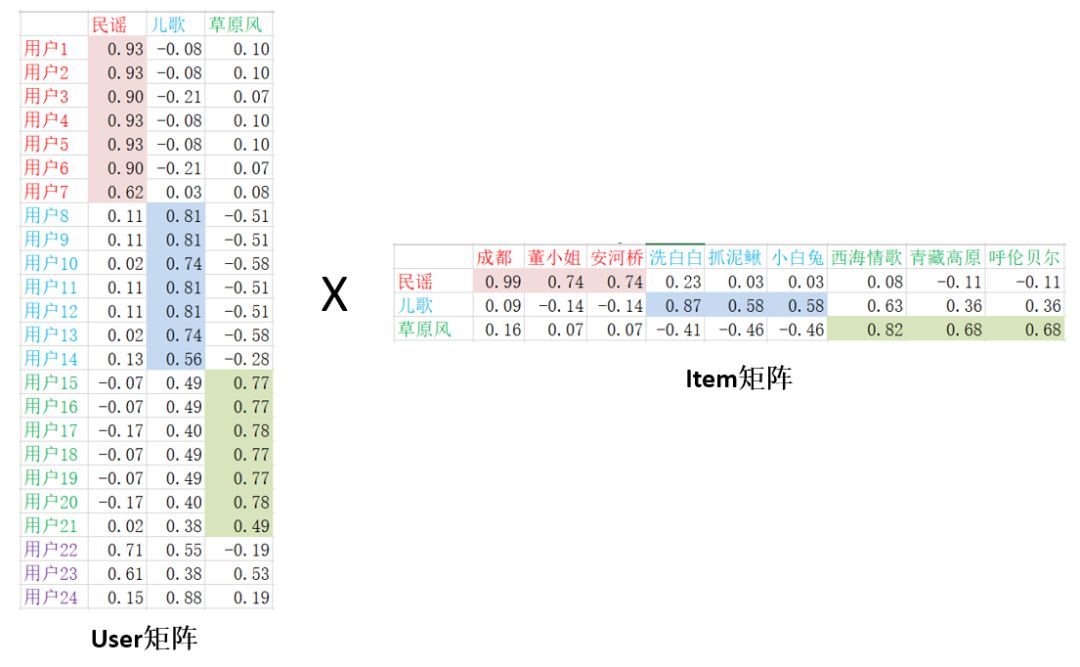
图3
其中,User矩阵共有24行,每行对应一个用户的向量,而Item矩阵共有9列,每列对应一首歌曲的向量。
仔细观察User矩阵可以发现,用户的听歌爱好会体现在用户向量上。比如说,从图1的评分矩阵中,我们知道用户1到用户7这群用户喜欢听民谣类的歌曲,对于这群用户,MF学出来的用户向量的特点是第1维的值最大。类似地,用户8到用户14这群用户喜欢听儿歌,MF学出来的用户向量的特点是第2维的值最大。而用户15到用户21喜欢听草原风,他们的用户向量的第3维最大。对于那些有2种兴趣的用户,比如用户22,他喜欢听民谣和儿歌,他的用户向量则会在第1和第2维上较大。
再来观察Item矩阵,我们也会发现,歌曲的风格也会体现在歌曲的向量上。比如说,对于民谣类的歌曲,它们的向量第1维最大,对于儿歌,它们的第2维最大,对于草原风,它们的向量的第3维最大。
用户向量和歌曲向量的这种特性其实是由MF的目标函数决定的。因为MF用user向量和item向量的内积去拟合评分矩阵中该user对该item的评分(例子中的0和1),所以内积的大小反映了user对item的喜欢程度。用户向量和歌曲向量在相同的维度上越匹配,内积就越大,反之内积就越小。这就导致了学出来的用户向量和歌曲向量的每一维取值的大小都代表了一定意义。比如在上述例子中,MF学到的每一维就代表了一个不同的歌曲类别,这里的民谣、儿歌、草原风其实是我们根据每一维的数据特点,为了好理解而人为地给每个类别起的名字,实际上MF学出来的每一维不一定都能有这么好的解释,很多时候甚至可能都无法直观地解释每一维,但每一维的确又代表了一个类别,因此我们把这种类别称为隐类别,把用户向量和歌曲向量中的每一维称为隐变量。所以矩阵分解是一种隐变量模型。隐类别的个数是要我们事先指定的,也就是上面的那个k,k 越大,隐类别就分得越细,计算量也越大。
另外,我们在例子中也可以看到,描述一个用户的听歌兴趣可以用评分矩阵中一个9维的稀疏向量来表示(每一维代表一� �歌曲),也可以用MF学出来的用户向量来描述用户听歌兴趣。前者是以歌曲为粒度来描述用户听歌兴趣,后者是以隐类别为粒度来描述用户听歌兴趣。由于隐类别的个数远远小于歌曲的总数,因此,MF是一种降维方法,把歌曲的维度降到隐类别的维度,然后在隐类别上匹配用户和歌曲去做推荐。
1.3 计算内积,排序,推荐
因为用户向量和歌曲向量的内积等于预测评分,所以在我们学出User矩阵和Item矩阵之后,把这两个矩阵相乘,就能得到每个用户对每首歌曲的预测评分了,评分值越大,表示用户喜欢该歌曲的可能性越大,该歌曲就越值得推荐给用户。下面的图4给出了图3中的User矩阵和Item矩阵相乘的结果,我们把它称为预测评分矩阵。
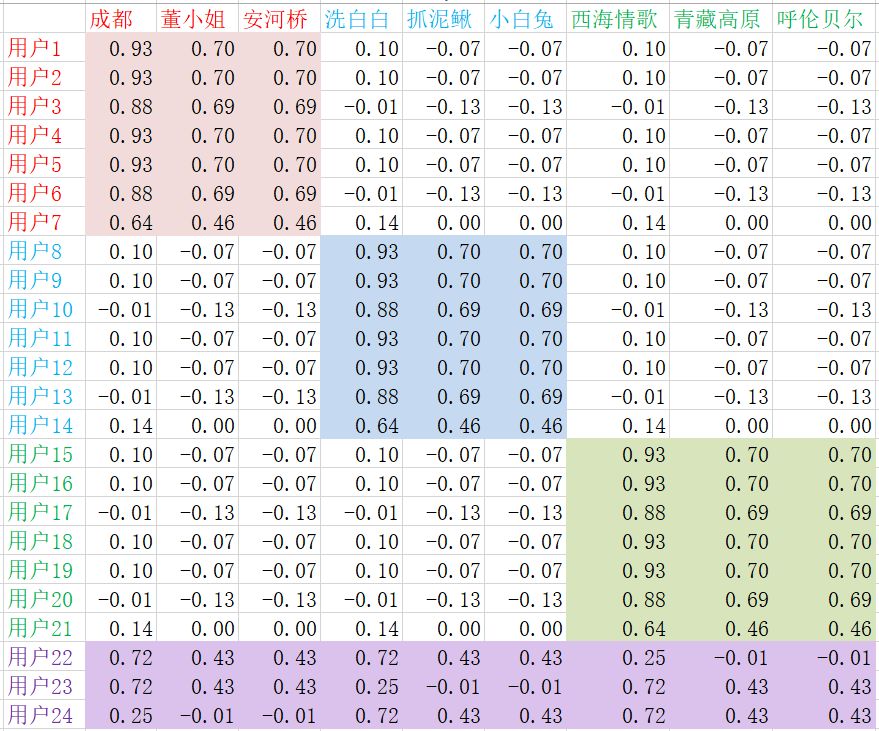
图4
如图4所示,User矩阵和Item矩阵相乘得到的预测评分矩阵中每个元素都是非零的,它把图1的原始评分矩阵中原本为空的地方都填上数字了。对于用户1到用户7,他们的MF向量和前3首民谣的MF向量最匹配,所以它们的内积较大,但跟儿歌和草原风歌曲的MF向量都不匹配,所以它们的内积较小。同理,其余用户也有类似的结论。我们用不同颜色把预测评分矩阵中值较大的区域标注了出来,可以看到,对于用户喜欢的类别(体现在历史有播放过该类别的歌曲),该类别下的歌曲的预测评分都比较大,反之,预测评分都比较小。这就说明了,MF学习出来的用户向量和歌曲向量,可以很准确地刻画用户的听歌兴趣和歌曲的类别属性,通过它们的内积能有效地为用户找到感兴趣的歌曲。
在实际使用时,我们一般是先用MF对评分矩阵做分解,得到User矩阵和Item矩阵。对于某个用户,我们把他的用户向量和所有item向量做内积,然后按内积从大到小排序,取出前K 个item,过滤掉历史item后推荐给用户。
至此,我们通过这个音乐推荐的例子,以形象但不十分严谨的方式,把矩阵分解模型如何做推荐的方法介绍完了。因为这是一篇科普性质的文章,其主要目的是给非推荐领域的读者简单介绍矩阵分解方法如何做推荐,所以它只讲述了矩阵分解算法的基本思想和做法,不会涉及具体数学公式。如果想进一步了解其中的算法细节和数学原理,可以继续参考本系列的第二篇文章。
(1)MF把用户对item的评分矩阵分解为User矩阵和Item矩阵,其中User矩阵每一行代表一个用户的向量,Item矩阵的每一列代表一个item的向量;
(2)用户i 对item j 的预测评分等于User矩阵的第i 行和Item矩阵的第j 列的内积,预测评分越大表示用户i 喜欢item j 的可能性越大;
(3)MF是把User矩阵和Item矩阵设为未知量,用它们来表示每个用户对每个item的预测评分,然后通过最小化预测评分和实际评分的差异学习出User矩阵和Item矩阵;
(4)MF是一种隐变量模型,它通过在隐类别的维度上去匹配用户和item来做推荐。
(5)MF是一种降维方法,它将用户或item的维度降低到隐类别个数的维度。
[1] 项亮. 推荐系统实践. 北京: 人民邮电出版社. 2012.
[2] Sarwar B M, Karypis G, Konstan J A, et al. Item-based collaborative filtering recommendation algorithms. WWW. 2001, 1: 285-295.
[3] Linden G, Smith B, York J. Amazon. com recommendations: Item-to-item collaborative filt ering. IEEE Internet computing. 2003 (1): 76-80.
[4] Koren Y, Bell R, Volinsky C. Matrix factorization techniques for recommender systems. Computer. 2009 (8): 30-37.
[5] Koren Y. Factorization meets the neighborhood: a multifaceted collaborative filtering model. SIGKDD. 2008: 426-434.
[6] Hu Y, Koren Y, Volinsky C. Collaborative filtering for implicit feedback datasets. ICDM. 2008: 263-272.
[7] Mnih A, Salakhutdinov R R. Probabilistic matrix factorization. NIPS. 2008: 1257-1264.
[8] Koren Y. Collaborative filtering with temporal dynamics. SIGKDD. 2009: 447-456.
[9] Pilászy I, Zibriczky D, Tikk D. Fast als-based matrix factorization for explicit and implicit feedback datasets. RecSys. 2010: 71-78.
[10] Johnson C C. Logistic matrix factorization for implicit feedback data. NIPS, 2014, 27.
[11] He X, Zhang H, Kan M Y, et al. Fast matrix factorization for online recommendation with implicit feedback. SIGIR. 2016: 549-558.
[12] Hofmann T. Probabilistic latent semantic analysis. UAI. 1999: 289-296.
[13] Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation. JMLR. 2003, 3(Jan): 993-1022.
[14] Zhang S, Yao L, Sun A, et al. Deep learning based recommender system: A survey and new perspectives. ACM Computing Surveys (CSUR). 2019, 52(1): 5.
[15] Mikolov, Tomas & Chen, Kai & Corrado, G.s & Dean, Jeffrey. Efficient Estimation of Word Representations in Vector Space. Proceedings of Workshop at ICLR. 2013.
[16] Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality. NIPS. 2013: 3111-3119.
[17] Pennington J, Socher R, Manning C. Glove: Global vectors for word representation. EMNLP. 2014: 1532-1543.
[18] Covington P, Adams J, Sargin E. Deep neural networks for youtube recommendations. RecSys. 2016: 191-198.
[19] Chen T, Guestrin C. Xgboost: A scalable tree boosting system. SIGKDD. 2016: 785-794.
[20] Ke G, Meng Q, Finley T, et al. Lightgbm: A highly efficient gradient boosting decision tree. NIPS. 2017: 3146-3154.

作者:腾讯技术工程