(第7篇)八斗学习课堂笔记-【01、02】推荐系统
第一步:召回阶段:用token检索item,(比如8个item)
第二步:过滤阶段:把劣质的item过滤掉,(剩余5个item)
第三步:排序,把好的item排前面
第四步:截断,取TopN
其中,第一步和第二步属于粗排阶段,侧重于召回;第三、第四步属于精排阶段,侧重于准确。
建库:
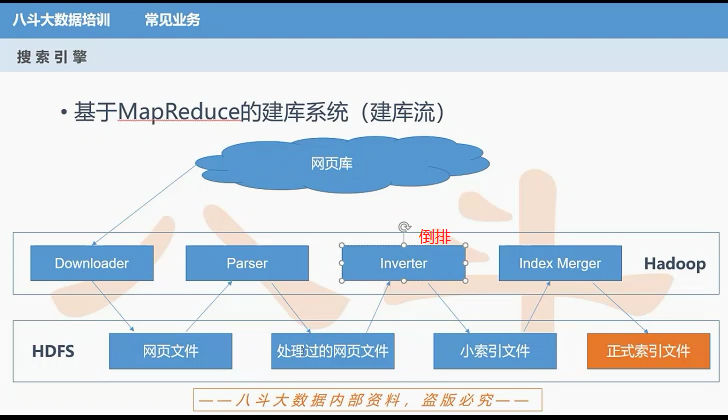
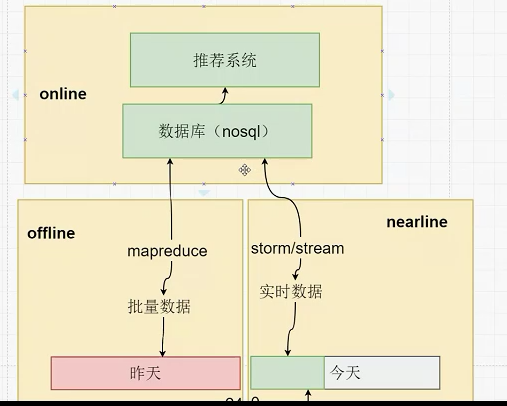
==================================================================
【02】MR实践复习
1、架构
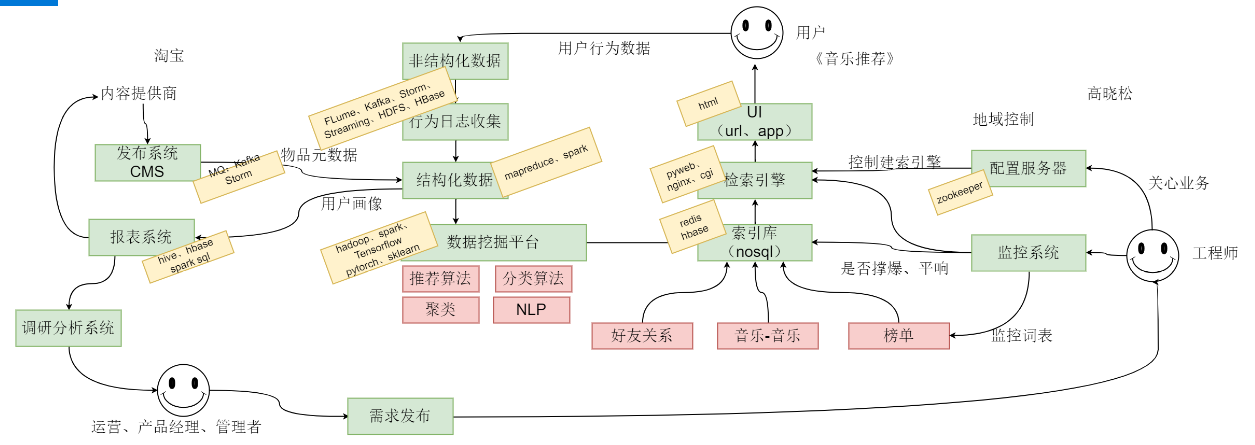
2、mapreduce(复习)
2.1 MR基本概念
(1)通常一个集群中,有这几个角色:master、slave、client
(2)数据副本 —— 数据高可用、容灾
(3)mapreduce —— 分而治之思想
(4)一个split和一个map是一对一的关系
(5)开发java相当于开发函数,开发python等脚本,相当于规定好标准输入和输出
(6)hadoop 1.0 -> hadoop 2.0
hadoop1.0:主:jobtracker、namenode
从:tasktracker、datanode
TaskTracker通过slot数目(可配置参数)限定Task的并发度
进程:worker
hadoop 2.0:主:ResourceMgr(RM资源调度)、ApplicationManager(AM任务调度)
从:NodeManager(NM)
进程:容器(Container)
* 先排序再溢写

单机调试:
cat input | mapper | sort | reducer > output
节点上,分发目标path:
/usr/local/src/hadoop-2.6.5/tmp/nm-local-dir/usercache/root/appcache/application_1543137200099_0011/container_1543137200099_0011_01_000001
杀死任务:
yarn application -kill application_1543137200099_0011
2.2 实践代码
(1)wordcount
(2)全排序
(a) 单reducer:依赖框架自身的sort功能
方式①:通过加一个很大的base_count,保证key对齐,依赖字典序完成全局排序
第一个代码:mr_allsort_1reduce_python(base count)
-jobconf "mapred.reduce.tasks=1"
方式②:通过配置完成全排序,不需要设置base_count
第二个代码:mr_allsort_1reduce_python_2 (通过配置完成)依赖于框架自身的sort功能
# 指定按 key 做 partition
-partitioner org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner
# 利用该配置可以完成二次排序
-jobconf org.apache.hadoop.mapred.lib.KeyFieldBasedComparator \
# 利用该配置可以完成key排序
# 1 代表第一列
-jobconf stream.num.map.output.key.fields=1 \
# 设置map分隔符的位置,该位置前的为key,之后的为value
# "-k1,1" 表示从第1个字段开始,到第一个字段结束,即第一个字段
-jobconf mapred.text.key.partitioner.options="-k1,1" \
# 设置key中需要比较的字段或字节范围
# 选择哪一部分做partition,n是指数字
-jobconf mapred.text.key.comparator.options="-k1,1n" \
-jobconf mapred.reduce.tasks=1
(b) 多reducer
mr_allsort_python(多桶)
适合大数据
-jobconf mapred.reduce.tasks=2 \
# 二次排序的时候需要指定哪个是key,2代表前面两个字段区域作为key
-jobconf stream.num.map.output.key.fields=2 \
# 指定第一个字段是key,指定partition阶段的key值,用于分发
-jobconf num.key.fields.for.partition=1 \
-partitioner org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner
// mapred.text.key.partitioner.options,
// 这个参数可以认为是 num.key.fields.for.partition的升级版
// 它可以指定不仅限于key中的前几个字段用做partition,
// 而是可以单独指定 key中某个字段或者某几个字段一起做partition。
(3)白名单——分发
-file:把本地的文件分发到各个节点
-cachefile:把hdfs的压缩文件分发到各个节点
-archivefile:把hdfs的压缩目录分发到各个节点
# 操作
tar cvzf w.tar.gz white_list_1 white_list_2
(4)压缩
# 指定map的输出是否压缩,有助于减小数据量,减小io压力
# 通过该方法可以控制map个数,形成压缩文件之后不会再进行split
mapred.compress.map.output
# 指定map的输出压缩算法
mapred.map.output.compression.codec
(5)join
例如:相同的key,value拼成一起
-jobconf stream.num.map.output.key.fields=2 \
-jobconf num.key.fields.for.partition=1
3、一个简易demo,检索系统
名单信息:

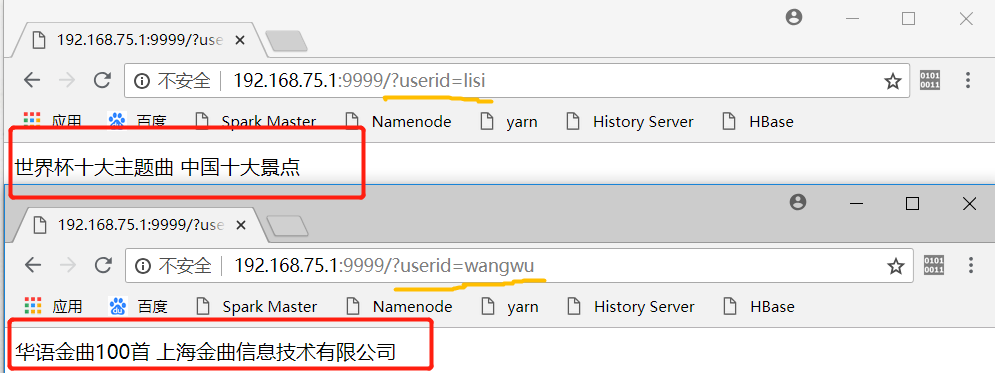
# python main.py 9999
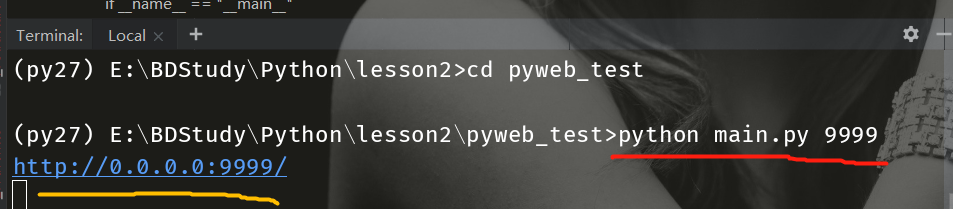
通过网页打开9999端口,并输入userid
一起学习一起讨论的可以加我V一起分享:我的名字叫甘世玉, v:姓名全拼1026
我这边有一些大数据的课程可以分享给你
作者:ijia1