统计学习方法之朴素贝叶斯理解和代码复现
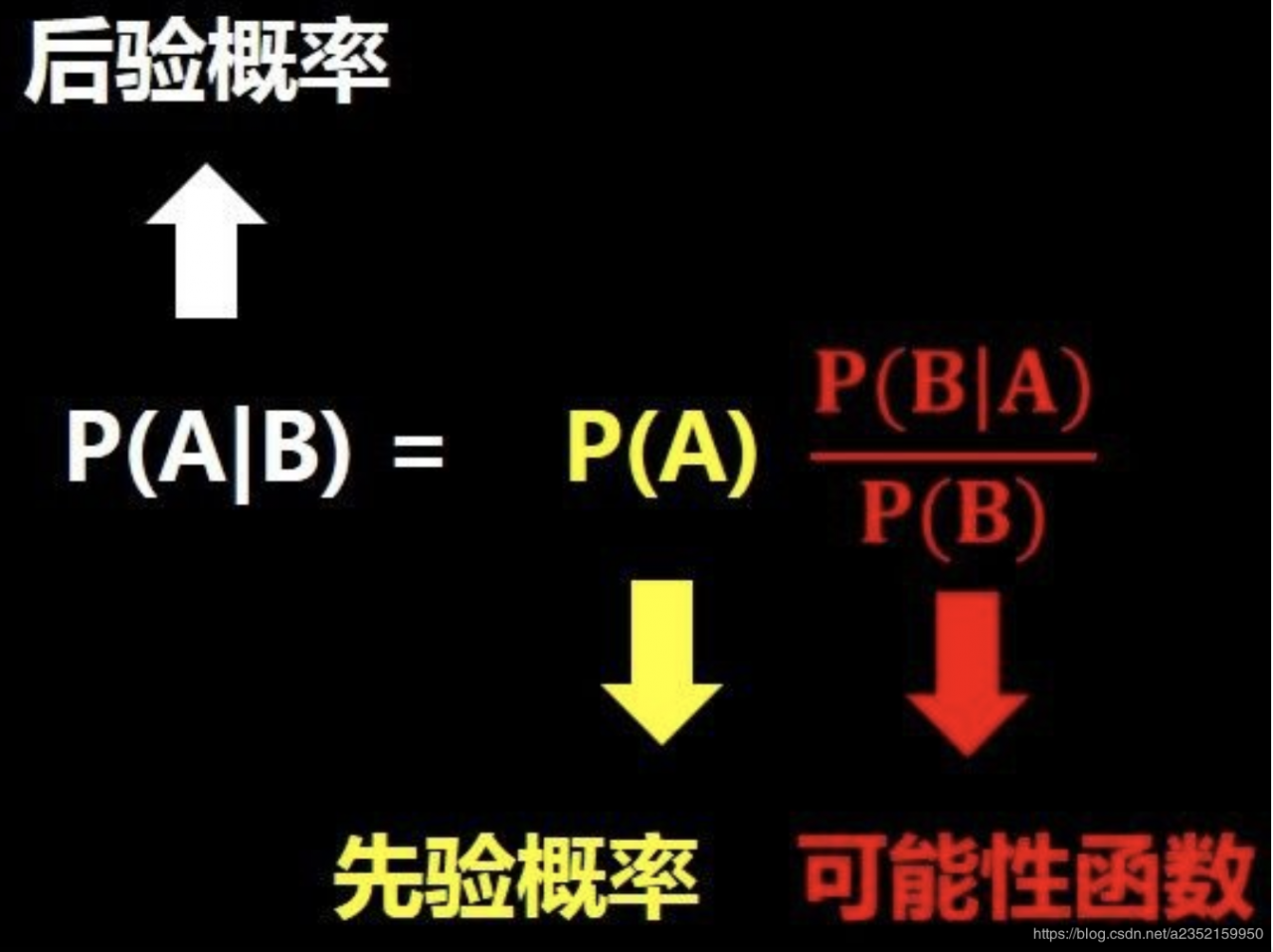
联合概率 P(A,B) = P(B|A)*P(A) = P(A|B)*P(B)将右边两个式子联合得到下面的式子:
P(A|B)表示在B发生的情况下A发生的概率。P(A|B) = [P(B|A)*P(A)] / P(B)
直观理解一下这个式子,如下图,问题A在我们知道B信息之后概率发生了变化(图片来自于小白之通俗易懂的贝叶斯定理(Bayes’ Theorem)

朴素贝叶斯条件:向量X的每一个特征项是独立同分布,这个条件过于宽泛,但是为了计算简便,我们尝试使用一下,用了之后发现效果还不错,那就用着吧
2.极大似然估计求取分类器y值
还记得原先求不同类别下的最大概率这一式子吗(分类器y)?里面有很多的连乘记得吗?
这里提出了一个问题,那么多概率连乘,如果其中有一个概率为0怎么办?那整个式子直接就是0了,这样不对。所以我们连乘中的每一项都得想办法让它保证不是0,哪怕它原先是0,(如果原先是0,表示在所有连乘项中它概率最小,那么转换完以后只要仍然保证它的值最小,对于结果的大小来说没有影响)这里就使用到了贝叶斯估计。

做这种变换是为了每一个概率不为0,从而对于y这个连乘的式子没有影响,但是为了保持概率值之和依旧为1,才演变成上面的式子


在实际运用中,不光需要使用贝叶斯估计(保证概率不为0),同时也要取对数(保证连乘结果不下溢出)。
为什么?
由于连乘项都是0-1之间的,那很多个(特征个数)0-1之间的数相乘,最后的数一定是非常非常小了,可能无限接近于0。对于程序而言过于接近0的数可能会造成下溢出,也就是精度不够表达了。所以我们会给整个连乘项取对数,这样哪怕所有连乘最后结果无限接近0,那取完log以后数也会变得很大(虽然是负的很大),计算机就可以表示了。
取完log以后结果会不会发生变化?
答案是不会的。log在定义域内是递增函数,log(x)中的x也是递增函数。在单调性相同的情况下,连乘得到的结果大,log取完也同样大,并不影响不同的连乘结果的大小的比较
5.代码复现(jupyter)#下载minist手写数据集,并加载
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()
#X_train.shape is (60000, 28, 28)
#y_train.shape is (60000,)
#我们将数据展开一下
X_train = X_train.reshape(-1 , 28*28)
y_train = y_train.reshape(-1 , 1)
X_test = X_test.reshape(-1 , 28*28)
y_test = y_test.reshape(-1 , 1)
#为了简便,我们将手写数据图片二值化一下
X_train[X_train = 128] = 1
X_test[X_test = 128] = 1
import numpy as np
#根据公式计算先验概率P_y,利用拉普拉斯平滑λ=1,并对连乘公式取log
P_y = np.zeros((10 , 1))
classes = 10
for i in range(classes):
P_y[i] = ((np.sum(y_train == i))+1)/(len(y_train)+classes)
P_y = np.log(P_y)
print(P_y)
#计算条件概率Px_y
#这个模块实现求取各个特征值的个数
Px_y = np.zeros((classes , X_train.shape[1] , 2))
for i in range(X_train.shape[0]):
k = y_train[i]
x = X_train[i]
for feature in range(X_train.shape[1]):
Px_y[k,feature,x[f]] += 1
#开始计算条件概率Px_y
#
for index in range(classes):
for f in range(X_train.shape[1]):
Px_y[index , f , 0] = (Px_y[index , f , 0] + 1) / (np.sum(y_train == index) + 2)
Px_y[index , f , 1] = (Px_y[index , f , 1] + 1) / (np.sum(y_train == index) + 2)
#为了把连乘变成连加,我们对Px_y取一个log对数
Px_y = np.log(Px_y)
#拿一个出来看看
print(Px_y[0])
#我们预测的最终结果放在predict中
#每一个数据在10个分类器的结果放在res中,取一个argmax就得到一个预测值
predict = np.zeros((y_test.shape[0],1))
for data in range(y_test.shape[0]):
res = np.zeros((classes , 1))
for i in range(classes):
res[i] = P_y[i]
for f in range(X_train.shape[1]):
res[i] += Px_y[i,f,X_test[data,f]]
predict[data] = np.argmax(res)
predict = predict.astype(int)
#取两个拿出来对比一下
print(predict[:5])
print(y_test[:5])
#预测一下准确率
precision = np.sum(predict == y_test) / y_test.shape[0]
print(precision)
觉得有用就请点个赞吧
参考文章:
李航统计学习方法第二版
统计学习方法|朴素贝叶斯原理剖析及实现
作者:dxwell6