统计学习基础
过拟合和欠拟合
作者:不明不白小菜鸡
过拟合是指训练误差和测试误差之间的差距太大。就是模型复杂度高于实际问题,模型在训练集上表现很好,但在测试集上却表现很差。
措施:
1、增加数据集
2、加入正则化
3、进行特征选择
4、提前停止训练,深度学习中常用dropout策略。
欠拟合是指模型不能在训练集上获得足够低的误差。换句换说,就是模型复杂度低,模型在训练集上就表现很差,没法学习到数据背后的规律。
措施:
1、增加模型复杂度和训练次数
2、增加新特征,增大假设空间
3、如果有正则项,可以调小正则项参数
偏差、方差、噪声
偏差:度量了模型的期望预测和真实结果的偏离程度,刻画了模型本身的拟合能力。
方差:度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响。
噪声:表达了当前任务上任何模型所能达到的期望泛化误差的下界,刻画了学习问题本身的难度。
偏方差分解


以上是以线性回归为例。lamda越小意味着复杂度越大
正则化是为了防止过拟合, 进而增强泛化能力
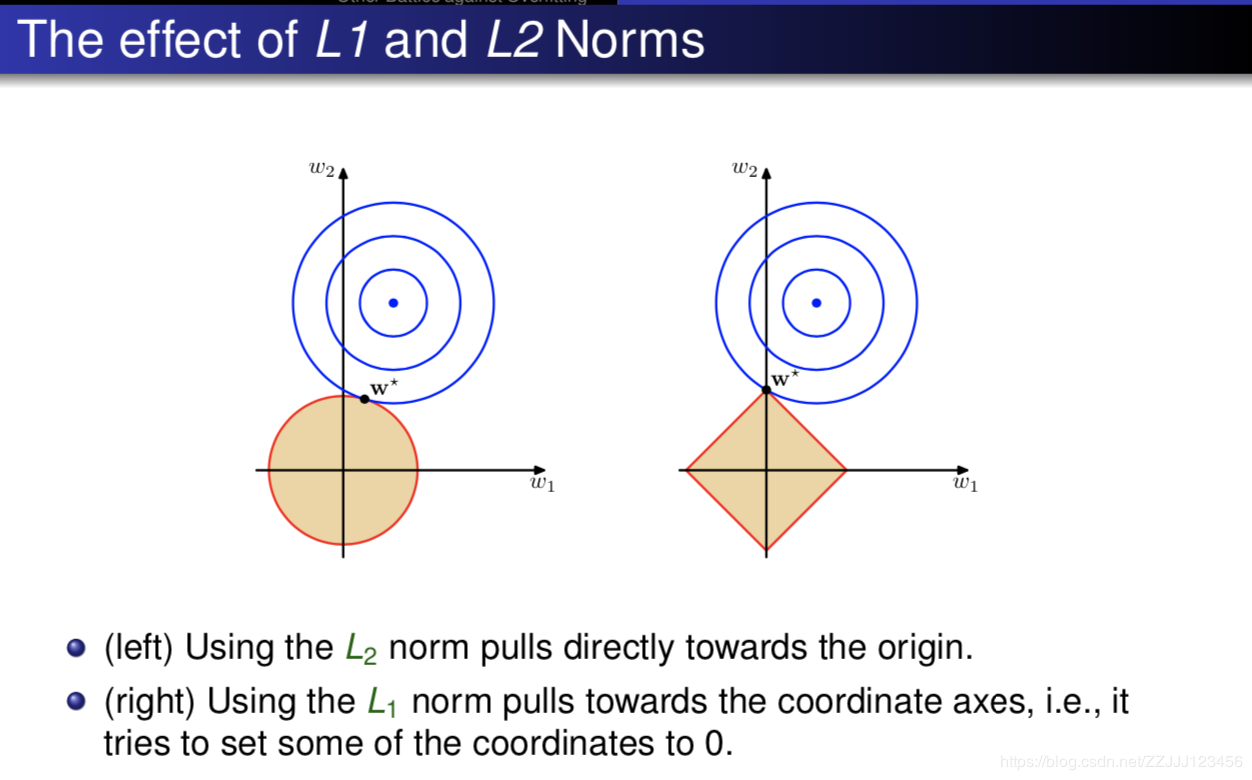
L1和L2正则化的目的都是减少模型的复杂度。
L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择
L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合
当对损失进行求导时,对参数b进行求导,可发现正则化对其没有影响,而当对参数w进行求导时,可以发现正则化对w的影响。


作者:不明不白小菜鸡
相关文章
Iris
2021-08-03
Heather
2020-11-04
Kande
2023-05-13
Ula
2023-05-13
Jacinda
2023-05-13
Winona
2023-05-13
Fawn
2023-05-13
Echo
2023-05-13
Maha
2023-05-13
Kande
2023-05-15
Viridis
2023-05-17
Pandora
2023-07-07
Tallulah
2023-07-17
Janna
2023-07-20
Ophelia
2023-07-20
Natalia
2023-07-20
Irma
2023-07-20