二手车交易价格预测_Task3_特征工程
import pandas as pd
import numpy as np
from sklearn import preprocessing
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
from operator import itemgetter # 用于获取对象的位置
# 导入数据
train_data = pd.read_csv(r'F:\Users\TreeFei\文档\PyC\ML_Used_car\data\used_car_train_20200313.csv', sep=' ')
test_data = pd.read_csv(r'F:\Users\TreeFei\文档\PyC\ML_Used_car\data\used_car_testA_20200313.csv', sep=' ')
# 看下数据形状
print(train_data.shape, test_data.shape)
发现训练集中有150000个样本,31列(30列特征+1列标签)
测试集中有50000个样本,30列(30列特征)
这里阿泽大大包装了一个异常之处理的代码,可以随时调用
def outliers_proc(data, col_name, scale=3):
'''
用于清洗异常值,默认用box_plot(scale=3)进行清洗 - 箱线图处理异常值
:param data: 接收pandas数据格式
:param col_name: pandas列名
:param scale: 尺度
:return:
'''
def box_plot_outliers(data_ser, box_scale):
'''
利用箱线图去除异常值
:param data_ser: 接收pandas.Series数据格式
:param box_scale: 箱线图尺度
:return:
'''
# quantile(0.75) - 求数据的上四分位数 - Q3
# quantile(0.25) - 求数据的下四分位数 - Q1
# data_ser.quantile(0.75) - data_ser.quantile(0.25) = Q3 - Q1 = ΔQ --> 四分位距
'''
boxplot默认的上边缘到上四分位数的间距是1.5ΔQ,即 scale=1.5
这里设定的为3ΔQ:
超过了上边缘Q3+3ΔQ和下边缘Q1-3ΔQ的部分视为异常值
'''
iqr = box_scale * (data_ser.quantile(0.75) - data_ser.quantile(0.25)) # iqr - 上边缘到上四分位数的间距,即3ΔQ
val_low = data_ser.quantile(0.25) - iqr # 下边缘 Q1-3ΔQ
val_up = data_ser.quantile(0.75) + iqr # 上边缘 Q3+3ΔQ
rule_low = (data_ser val_up) # 高于上边缘 Q3+3ΔQ的为异常值
return (rule_low, rule_up), (val_low, val_up) # 得到异常值 / 上边缘与下边缘之间的值
data_n = data.copy() # 拷贝一份数据的副本
data_series = data_n[col_name] # 转化成pandas.Series数据格式
rule, value = box_plot_outliers(data_series, box_scale=scale)
# data_series.shape[0] - 看data_series这个一维数组有几行,即原数据集的总列数
'''
np.arange() - 函数返回一个有终点和起点的固定步长的排列
一个参数时:参数值为终点,起点取默认值0,步长取默认值1
两个参数时:第一个参数为起点,第二个参数为终点,步长取默认值1
三个参数时:第一个参数为起点,第二个参数为终点,第三个参数为步长,其中步长支持小数
'''
# np.arange(data_series.shape[0]) - 取N个数,N为数据集字段数,步长为1 --> 生成的是列表
index = np.arange(data_series.shape[0])[rule[0] | rule[1]] # 挑出位于异常值区间的序号,放进标记为index的列表中
print('Delete number is: {}'.format(len(index))) # 输出要删除多少个异常值
data_n = data_n.drop(index) # 按索引查找并删除
'''
reset_index() - 重塑索引 (因为有时候对dataframe做处理后索引可能是乱的,就像上面删除了异常值一样)
参数详解:
drop - True:把原来的索引index列去掉,重置index False:保留原来的索引,添加重置的index
inplace - True:原数组不变,对数据进行修改之后结果给新的数组 False:直接在原数组上对数据进行修改
'''
data_n.reset_index(drop=True, inplace=True)
print('Now column number is: {}'.format(data_n.shape[0])) # 打印出现在的行数,即正常值的个数
index_low = np.arange(data_series.shape[0])[rule[0]] # 挑出位于下异常值区间的序号,放进标记为index_low的列表中
outliers_low = data_series.iloc[index_low] # 把位于下异常值区间的数据放进outliers中
print('Description of data less than the lower bound is: ')
print(pd.Series(outliers_low).describe()) # 对于位于下异常值区间的数据,做一个统计描述
index_up = np.arange(data_series.shape[0])[rule[1]] # 挑出位于上异常值区间的序号,放进标记为index_up的列表中
outliers_up = data_series.iloc[index_up] # 把位于上异常值区间的数据放进outliers_up中
print('Description of data larger than the lower bound is: ')
print(pd.Series(outliers_up).describe()) # 对于位于上异常值区间的数据,再做一个统计描述
fig, ax = plt.subplots(1, 2, figsize=(10, 7))
'''
sns.boxplot - 箱线图
参数详解:
x, y, hue - 数据或向量数据的变量名称
data - 用于绘图的数据集
palette - 调色板名称
ax - 绘图时使用的matplotlib轴对象
'''
sns.boxplot(y=data[col_name], data=data, palette='Set1', ax=ax[0])
sns.boxplot(y=data_n[col_name], data=data_n, palette='Set1', ax=ax[1])
return data_n
我们可以删掉一些异常数据,以power为例 - 注意:test的数据不能删除,train删哪些可以自行判断
train_data = outliers_proc(train_data, 'power', scale=3)
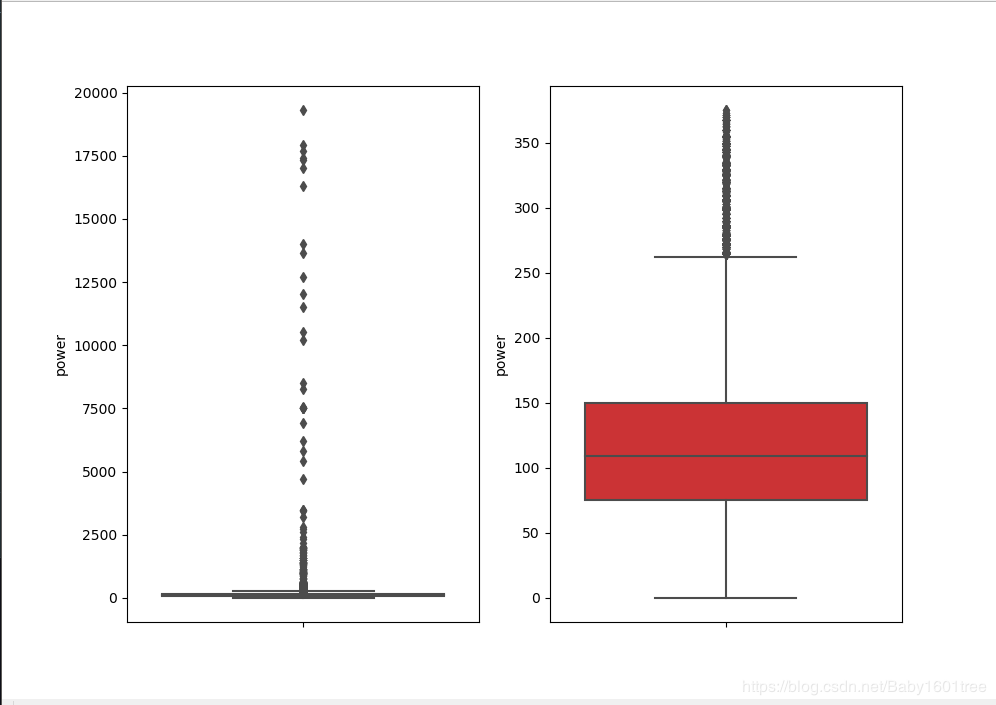
我们发现,处理前的异常值是很多的,处理之后可以看到箱线图的形状了,数据好了很多,但是还是有部分异常值,可以考虑将尺度scale再调小些;
我们把训练集和测试集放在一起,方便构造特征
'''
把两个数据集都加一列'train'标识,合并之后用来区分数据来源
'''
train_data['train'] = 1
test_data['train'] = 0
'''
pd.concat()参数说明:
ignore_index - 如果两个表的index都没有实际含义,可以令 ignore_index = True
合并的两个表根据列字段对齐,然后重塑新的索引
sort - 默认为False;
设置为True时表示合并时会根据给定的列值来进行排序后再输出
'''
data = pd.concat([train_data, test_data], ignore_index=True, sort=False)
# 看一下数据有哪些列
data.columns
'''
特征解释:
SaleID - 交易ID,唯一编码
name - 汽车交易名称,已脱敏
regDate - 汽车注册日期,例如20160101,2016年01月01日
model - 车型编码,已脱敏
brand - 汽车品牌,已脱敏
bodyType - 车身类型-豪华轿车:0; 微型车:1; 厢型车:2; 大巴车:3; 敞篷车:4; 双门汽车:5; 商务车:6; 搅拌车:7
fuelType - 燃油类型-汽油:0; 柴油:1; 液化石油气:2; 天然气:3; 混合动力:4; 其他:5; 电动:6
gearbox - 变速箱-手动:0; 自动:1
power - 发动机功率:范围 [ 0, 600 ]
kilometer - 汽车已行驶公里,单位万km
notRepairedDamage - 汽车有尚未修复的损坏-是:0; 否:1
regionCode - 地区编码,已脱敏
seller - 销售方-个体:0; 非个体:1
offerType - 报价类型-提供:0; 请求:1
creatDate - 汽车上线时间-即开始售卖时间
price - 二手车交易价格(预测目标)
v系列特征 - 匿名特征:包含v0-14在内15个匿名特征(根据汽车的评论,标签等大量信息得到的embedding向量)
'''
# 我们构造一个车辆使用时间 - 一般来说:使用时间和价格会呈反比
'''
车辆使用时间 = 汽车上线时间 - 汽车注册时间
这里的汽车注册时间应该是二手车交易过户后在登记本上的注册时间,而不是新车首次注册的时间,不然不合逻辑
注意:数据的时间有出错的格式,我们需要设置参数 errors = 'coerce'
errors='coerce' Pandas - 遇到不能转换的数据就会赋值为 NaN
'''
'''
datetime标准形式: xxxx - xx - xx
dt.days - 求datetime数据的天数
dt.years - 求datetime数据的年
'''
data['used_Time'] = (pd.to_datetime(data['creatDate'], format='%Y%m%d', errors='coerce') -
pd.to_datetime(data['regDate'], format='%Y%m%d', errors='coerce')).dt.days
# 看一下新建的特征’used_time’有多少nan
data['used_Time'].isnull().sum()
1.空值有15072个,总数居有199037个,缺失比例约为7.6%
2.缺失数据占总样本大,不建议删除
3.可以尝试使用XGBoost之类的决策树来处理缺失值
'''
数据来源德国,因此参考德国的邮编 - 先验知识
'''
data['city'] = data['regionCode'].apply(lambda x: str(x)[:-3]) # [:-3] --> [0:-3] - 左闭右开:取第一个到倒数第4个
# 计算某品牌的销售统计量 - 计算统计量的时候得以训练集的数据进行统计
train_gb = train_data.groupby('brand')
all_info = {} # 新建一个字典,用来存放统计量
for kind, kind_data in train_gb: # kind - 品牌; # kind_data - 所属品牌对应的数据
info = {}
kind_data = kind_data[kind_data['price'] > 0] # 去掉不合理的价格 - 售价不会小于0
info['brand_amount'] = len(kind_data) # 所属品牌的数据长度即为该品牌的销售数量
info['brand_price_max'] = kind_data.price.max() # 找出该品牌的销售最高价
info['brand_price_median'] = kind_data.price.median() # 找出该品牌的销售价的中位数
info['brand_price_min'] = kind_data.price.min() # 找出该品牌的销售最低价
info['brand_price_sum'] = kind_data.price.sum() # 统计该品牌的销售总额
info['brand_price_std'] = kind_data.price.std() # 统计该品牌的销售价的标准差
info['brand_price_average'] = round(kind_data.price.sum() / (len(kind_data) + 1), 2) # 这里数量加了1,防止分母为0
all_info[kind] = info
这里的平均值average我卡了很久,一直在想为什么分母要加上1,找了很多资料都没有找到原因,后面看直播以后才知道+1是为了防止出现分母为0的情况(虽然说一般不会出现这种情况,但还是习惯性的加了1,对数据影响很小又能保证不会因为这个原因报错,学习到了!)
# 把做出来的新的统计特征加入原表中brand_fe = pd.DataFrame(all_info).T.reset_index().rename(columns={'index': 'brand'}) # 转置后重塑索引
data = data.merge(brand_fe, how='left', on='brand') # 相当于excel中的 vlookup
# 数据分桶 - 以power为例
'''
数据分桶的原因:
LightGBM在改进 XGBoost 时就增加了数据分桶,增强了模型的泛化性
1.分桶就是离散化,离散后,2333333333333333稀疏向量内积乘法运算速度会更快,计算结果也方便储存 # 这是onehot的好处
2.离散后,特征对异常值更具鲁棒性 - 系统或组织有抵御或克服不利条件的能力 - 常被用来描述可以面对复杂适应系统的能力
3.LR(线性回归)属于广义线性模型,表达能力有限
经过离散化后,每个变量有单独的权重,这相当于引入了非线性,能够提升模型的表达能力,加大拟合
4.离散后特征可以进行特征交叉(one-hot编码等),由 M+N 个变量编程 M*N 个变量,进一步引入非线形,提升了表达能力
5.特征离散后模型更稳定,如用户年龄区间不会因为用户年龄长了一岁就变化
'''
bin = [i * 10 for i in range(31)]
data['power_bin'] = pd.cut(data['power'], bin, labels=False) # 按值切分,bin为区间
data[['power', 'power_bin']]
这里针对第一个优点: '稀疏向量内积乘法运算速度会更快,计算结果也方便储存’是onehot编码的优点,不是分桶的好处
# 以上特征处理完了,我们可以删掉原始多余的特征数据了data = data.drop(['SaleID', 'creatDate', 'regDate', 'regionCode'], axis=1) # 资料上没有SaleID列,我在这里一起删除了
教材里是没有SaleID列的,应该是省略了,在这一步我一起做了删除的动作
# 目前的数据已经可以给树模型使用了,我们导出data.to_csv(r'F:\Users\TreeFei\文档\PyC\ML_Used_car\data\data_for_tree.csv', index=0)
# 不同模型对数据集的要求不同,我们再构造一份特征给LR(Logistic regression-逻辑回归), NN(近邻,如k近邻)之类的模型用
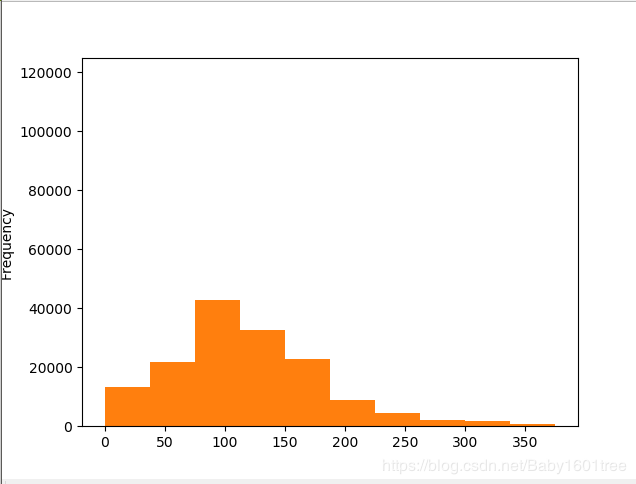
# # 我们看下数据分布
data['power'].plot.hist()
'''
分布非常不均匀,因为我们对train进行了异常值处理,但是test还有异常值
所以我们其实还是不删除train中的power的异常值比较好,改用长尾分布截断代替
'''
train_data['power'].plot.hist()
# 我们对其取log 再做归一化
'''
归一化的理由:
1.数据存在不同的评价指标,其量纲或量纲单位不同,处于不同的数量级
解决特征指标之间的可比性,经过归一化处理后,各指标处于同一数量级,便于综合对比
2.求最优解的过程会变得平缓,更容易正确收敛-即能提高梯度下降求最优解时的速度
3.提高计算精度
scaling-将变化幅度较大的特征化到[-1,1]之内
minmax_scale - 将每个特征放缩到给定范围内(默认范围0-1)
'''
# min_max_scaler = preprocessing.MinMaxScaler() # 创建该方法的实例
'''
为什么要取对数 - 数据集中有负数就不能取对数了 - 实践中,取对数的一般是水平量,而不是比例数据
1.缩小数据的绝对数值,方便计算
2.取对数后,可以将乘法计算转换称加法计算
3.对数值小的部分差异的敏感程度比数值大的部分的差异敏感程度更高
4.取对数之后不会改变数据的性质和相关关系,但压缩了变量的尺度
5.所得到的数据易消除异方差问题
'''
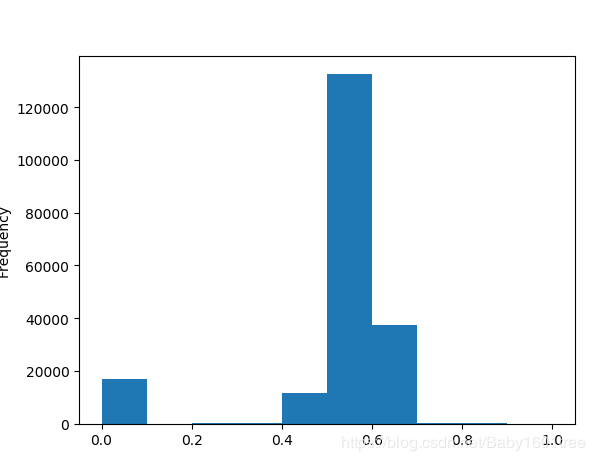
data['power'] = np.log(data['power'] + 1)
# x = (x - xmin) / (xmax - xmin) --> 将X归一化为[0,1]
data['power'] = ((data['power'] - np.min(data['power'])) / (np.max(data['power']) - np.min(data['power'])))
data['power'].plot.hist()
这里其实适合长尾分布截断
'''
归一化的理由:
1.数据存在不同的评价指标,其量纲或量纲单位不同,处于不同的数量级
解决特征指标之间的可比性,经过归一化处理后,各指标处于同一数量级,便于综合对比
2.求最优解的过程会变得平缓,更容易正确收敛-即能提高梯度下降求最优解时的速度
3.提高计算精度
scaling-将变化幅度较大的特征化到[-1,1]之内
minmax_scale - 将每个特征放缩到给定范围内(默认范围0-1)
'''
# min_max_scaler = preprocessing.MinMaxScaler() # 创建该方法的实例
'''
为什么要取对数 - 数据集中有负数就不能取对数了 - 实践中,取对数的一般是水平量,而不是比例数据
1.缩小数据的绝对数值,方便计算
2.取对数后,可以将乘法计算转换称加法计算
3.对数值小的部分差异的敏感程度比数值大的部分的差异敏感程度更高
4.取对数之后不会改变数据的性质和相关关系,但压缩了变量的尺度
5.所得到的数据易消除异方差问题
'''
data['power'] = np.log(data['power'] + 1)
# x = (x - xmin) / (xmax - xmin) --> 将X归一化为[0,1]
data['power'] = ((data['power'] - np.min(data['power'])) / (np.max(data['power']) - np.min(data['power'])))
data['power'].plot.hist()
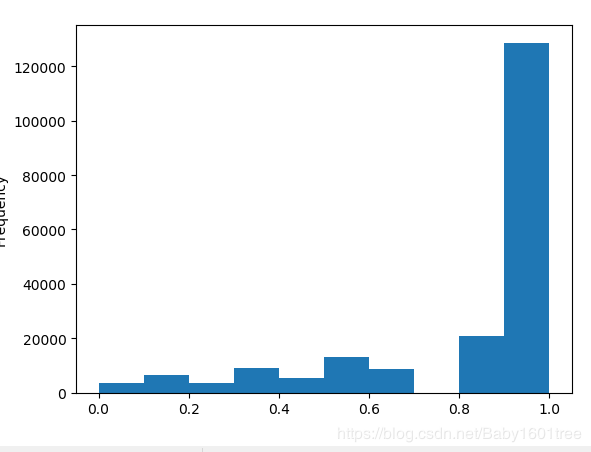
data['kilometer'].plot.hist() # 没有负的公里数,而且符合二手车大多数公里数都比较高的现象,应该已经做过了分桶
# 直接做归一化
data['kilometer'] = ((data['kilometer'] - np.min(data['kilometer']))
/ (np.max(data['kilometer']) - np.min(data['kilometer'])))
data['kilometer'].plot.hist()
def max_min(x): # 这个函数实现的就是下面的公式
return (x - np.min(x)) / (np.max(x) - np.min(x))
data['brand_amount'] = ((data['brand_amount'] - np.min(data['brand_amount'])) /
(np.max(data['brand_amount']) - np.min(data['brand_amount'])))
data['brand_price_average'] = ((data['brand_price_average'] - np.min(data['brand_price_average'])) /
(np.max(data['brand_price_average']) - np.min(data['brand_price_average'])))
data['brand_price_max'] = ((data['brand_price_max'] - np.min(data['brand_price_max'])) /
(np.max(data['brand_price_max']) - np.min(data['brand_price_max'])))
data['brand_price_median'] = ((data['brand_price_median'] - np.min(data['brand_price_median'])) /
(np.max(data['brand_price_median']) - np.min(data['brand_price_median'])))
data['brand_price_min'] = ((data['brand_price_min'] - np.min(data['brand_price_min'])) /
(np.max(data['brand_price_min']) - np.min(data['brand_price_min'])))
data['brand_price_std'] = ((data['brand_price_std'] - np.min(data['brand_price_std'])) /
(np.max(data['brand_price_std']) - np.min(data['brand_price_std'])))
data['brand_price_sum'] = ((data['brand_price_sum'] - np.min(data['brand_price_sum'])) /
(np.max(data['brand_price_sum']) - np.min(data['brand_price_sum'])))
# 对所有类别特征进行oneEncoder编码
'''
pandas --> get_dummies()方法: 对数据进行one-hot编码(因子化)
逻辑回归建模时,需要输入的特征都是数值型特征,我们通常会先对类目型的特征因子化;
以male(男性)为例:原本一个属性维度,因为其取值可以是yes或no,而将其平展开为’male_yes’,'male_no’两个属性; -是不是男性
1.原本male取值为yes的,在此处的"male_yes"下取值为1,在"male_no"下取值为0;
2.原本male取值为no的,在此处的"male_yes"下取值为0,在"male_no"下取值为1.
'''
data = pd.get_dummies(data, columns=['model', 'brand', 'bodyType', 'fuelType',
'gearbox', 'notRepairedDamage', 'power_bin'])
# 可以发现,原来进行onehot编码的特征被覆盖了
'''
也可以单独转化特征,通过x_new = pd.get_dummies(data[x], prefix='x') --> prefix - 转化后列名的前缀,这样子原来的特征不会被覆盖
然后通过pd.concat()连接转换后的特征
原先的特征想删除也可以用drop方法
'''
print(data.shape)
这份数据给 LR 用 - 逻辑回归模型,因为逻辑回归建模时,需要输入的特征都是数值型特征(其实这里的city特征有问题,后面会说)
data.to_csv(r'F:\Users\TreeFei\文档\PyC\ML_Used_car\data\data_for_lr.csv', index=0)
4.特征筛选
#过滤式
#相关性分析 - 我们挑选的都是数值型的特征
'''
DataFrame.corr(method='pearson', min_periods=1)
参数详解:
method - 分析方法: pearson, kendall, spearman
pearson - 衡量两个数据集合是否在一条线上面 - 即针对线性数据的相关系数计算
kendall - 反映分类变量相关性的指标 - 即针对无序序列的相关系数,非正态分布的数据
spearman - 非线性的,非正态分布的数据的相关系数
'''
print(data['power'].corr(data['price'], method='spearman'))
print(data['kilometer'].corr(data['price'], method='spearman'))
print(data['brand_amount'].corr(data['price'], method='spearman'))
print(data['brand_price_average'].corr(data['price'], method='spearman'))
print(data['brand_price_max'].corr(data['price'], method='spearman'))
print(data['brand_price_median'].corr(data['price'], method='spearman'))
# 也可以直接看图 - 下面是看两两特征之间的联系
data_numeric = data[['power', 'kilometer', 'brand_amount',
'brand_price_average', 'brand_price_max', 'brand_price_median']]
correlation = data_numeric.corr()
f, ax = plt.subplots(figsize=(7, 7))
plt.title('Correlation of Numeric Features with Price', y=1, size=16)
sns.heatmap(correlation, square=True, vmax=0.8)
没啥用,就是好看
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
from sklearn.linear_model import LinearRegression
'''
SequentialFeatureSelector是顺序特征选择算法,是一种贪心算法
SFA会根据分类器的性能同时删除或添加一个特征,直到达到所需大小k的特征子集为止
可通过以下四种方式获得SFA
顺序前向选择(SFS) #这里就是,所以forward参数选择了True
顺序向后选择(SBS)
顺序正向浮动选择(SFFS)
顺序向后浮动选择(SBFS)
sfs = SequentialFeatureSelector(model,k_features=feature_n,forward=True,verbose=2,scoring='accuracy',cv=cv)
参数详解:
model - 导入要对特征求职的算法
k_features - 要挑选的特征数
forward=True - 顺序向前,如果是False就是向后
floating - 是否浮动搜索
浮动算法具有附加的排除或包含步骤,可在特征被包含(或排除)后删除特征,以便可以对大量特征子集组合进行采样。
此步骤是有条件的,仅当在移除(或添加)特定特征后,通过标准函数将结果特征子集评估为“更好”时,才会发生此步骤
cv - 是否进行交叉验证
scoring - str,可调用或无(默认值:无)
如果为None(默认),则对sklearn分类器使用“准确性”,对于sklearn回归变量使用“ r2”
如果为str,则使用sklearn评分指标字符串标识符:如accuracy,f1,precision,recall,roc_auc
参考网址: https://rasbt.github.io/mlxtend/user_guide/feature_selection/SequentialFeatureSelector/
'''
# 将训练集和测试集剥离,这里得用训练集的数据,因为测试集没有price标签
sfs = SFS(LinearRegression(), k_features=10, forward=True, floating=False, scoring='r2', cv=0)
train_data_new = data[data['train'] == 1]
test_data_new = data[data['train'] == 0]
x = train_data_new.drop(['price'], axis=1) # 去掉标签,只保留特征
x = x.fillna(0)
y = train_data_new['price']
这时候,如果训练模型就会报错!!!说无法将字符串转化成浮点数,说明数据里有字符串类型的数据!!!
我们看一下是哪里的数据出了问题?!
# 我们把训练特征转化成DataFrame类型
df_x = pd.DataFrame(x)
# 找到df_x中的object类型的特征
df_x_obj = df_x.columns[df_x.dtypes == 'object']
print(df_x_obj) # 发现是city列,在提取邮编的时候数据类型变成了object
# 我们将city列做一下处理
data['city'] = pd.to_numeric(data.city, errors='raise')
# 我们再看一下city的数据类型
data['city']
# 处理之后我们再重复上面的特征顺序选择算法
train_data_new = data[data['train'] == 1]
test_data_new = data[data['train'] == 0]
x = train_data_new.drop(['price'], axis=1) # 去掉标签,只保留特征
x = x.fillna(0)
y = train_data_new['price']
sfs.fit(x, y) # 不报错了
sfs.k_feature_names_ # 我们输出挑选出来的特征,结果和教材上的好像不大一样
Out[98]:
(‘kilometer’,
‘v_0’,
‘v_3’,
‘v_7’,
‘used_Time’,
‘brand_price_std’,
‘brand_price_average’,
‘model_167.0’,
‘brand_24’,
‘gearbox_1.0’)
# 我们也试着画一画,看下边际效益
from mlxtend.plotting import plot_sequential_feature_selection as plot_sfs
import matplotlib.pyplot as plt
figl = plot_sfs(sfs.get_metric_dict(), kind='std_dev')
plt.grid()
plt.show()
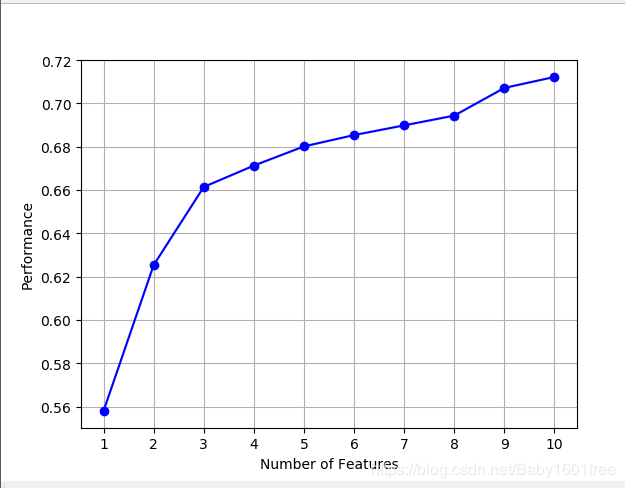
我们可以发现随着特征的增大,表现增长幅度大,随后呈现平稳缓慢增长的趋势;
-----等待Task4
作者:恶魔眼睛大又大���