机器学习小组第二期第三周:简单的数据预处理和特征工程
问题:在量纲不同的情况下,不能反映样本中每一个特征的重要程度。
方案:数据归一化,即标准化。把所有的数据都映射到同一个尺度(量纲)。
归一化可以提升模型精度,避免某一个取值范围特别大的特征对距离计算造成影响。(一个特例是决策树,对决策树不需要归一化,决策树可以把任意数据都处理得很好。)
数据的无量纲化可以是线性的,也可以是非线性的。线性的无量纲化包括中心化处理和缩放处理。中心化的本质是让所有记录减去一个固定值,即让数据样本数据平移到某个位置。缩放的本质是通过除以一个固定值,将数据固定在某个范围之中,取对数也算是一种缩放处理。
归一化之后的数据服从正态分布。
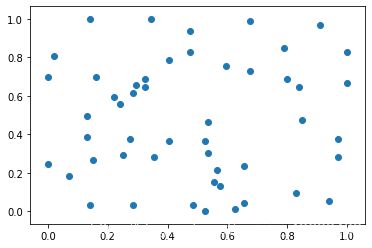
把所有数据映射到0-1之间。使用范围:特征的分布具有明显边界(分数0~100),受outlier的影响比较大。
import numpy as np
# 创建100个随机数
x = np.random.randint(0,100,size=100)
# 最值归一化(向量)
# 最值归一化公式,映射到0,1之间
(x - np.min(x)) / (np.max(x) - np.min(x))
# 最值归一化(矩阵)
# 0~100范围内的50*2的矩阵
X = np.random.randint(0,100,(50,2))
# 将矩阵改为浮点型
X = np.array(X, dtype=float)
# 最值归一化公式,对于每一个维度(列方向)进行归一化
# X[:,0]第一列,第一个特征
X[:,0] = (X[:,0] - np.min(X[:,0])) / (np.max(X[:,0]) - np.min(X[:,0]))
# X[:,1]第二列,第二个特征
X[:,1] = (X[:,1] - np.min(X[:,1])) / (np.max(X[:,1]) - np.min(X[:,1]))
# 如果有n个特征,可以写个循环:
for i in range(0,2):
X[:,i] = (X[:,i]-np.min(X[:,i])) / (np.max(X[:,i] - np.min(X[:,i])))
import matplotlib.pyplot as plt
# 简单绘制样本,看横纵坐标
plt.scatter(X[:,0],X[:,1])
plt.show()
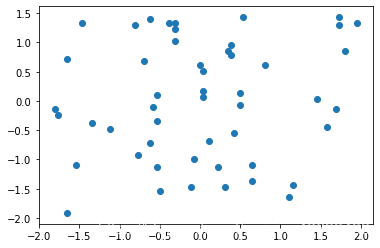
把所有数据归一到均值为0方差为1的分布。适用于数据没有明显的边界,可能存在极端数据值的情况。
X2 = np.array(np.random.randint(0,100,(50,2)),dtype=float)
# 套用公式,对每一列做均值方差归一化
for i in range(0,2):
X2[:,i]=(X2[:,i]-np.mean(X2[:,i])) / np.std(X2[:,i])
plt.scatter(X2[:,0],X2[:,1])
plt.show()
print(np.mean(X2[:,0]))
print(np.std(X2[:,1]))
# 输出:6.217248937900877e-17
# 输出:1.0
1.3.Sklearn中的归一化
对测试数据集进行归一化时,仍使用训练数据集的均值train_mean和方差std_train,因此要保存训练数据集中的均值和方差。
原因:测试数据代表模拟的真实环境,而在真实环境中可能无法得到均值和方差。
import numpy as np
import pandas as pd
from sklearn import datasets
from sklearn.model_selection import train_test_split
# Normalization
from sklearn.preprocessing import MinMaxScaler
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
#换成表
pd.DataFrame(data)
#实现归一化
scaler = MinMaxScaler() #实例化
scaler = scaler.fit(data) #fit,在这里本质是生成min(x)和max(x)
result = scaler.transform(data) #通过接口导出结果
result
result_ = scaler.fit_transform(data) #训练和导出结果一步达成
scaler.inverse_transform(result) #将归一化后的结果逆转
#使用MinMaxScaler的参数feature_range实现将数据归一化到[0,1]以外的范围中
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
scaler = MinMaxScaler(feature_range=[5,10]) #依然实例化
result = scaler.fit_transform(data) #fit_transform一步导出结果
result
#当X中的特征数量非常多的时候,fit会报错并表示,数据量太大了我计算不了
#此时使用partial_fit作为训练接口
#scaler = scaler.partial_fit(data)
# BONUS: 使用numpy来实现归一化
import numpy as np
X = np.array([[-1, 2], [-0.5, 6], [0, 10], [1, 18]])
#归一化
X_nor = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))
X_nor
#逆转归一化
X_returned = X_nor * (X.max(axis=0) - X.min(axis=0)) + X.min(axis=0)
X_returned
# Standardization
from sklearn.preprocessing import StandardScaler
iris = datasets.load_iris()
X = iris.data
y = iris.target
X_train,X_test,y_train,y_test = train_test_split(iris.data,iris.target,test_size=0.2,random_state=666)
standardScaler = StandardScaler()
# 归一化的过程跟训练模型一样
standardScaler.fit(X_train)
standardScaler.mean_
standardScaler.scale_
# 表述数据分布范围的变量,替代std_
transformX_train_standard = standardScaler.transform(X_train)
X_test_standard = standardScaler.transform(X_test)
# 使用transform
from sklearn.preprocessing import StandardScaler
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
scaler = StandardScaler() #实例化
scaler.fit(data) #fit,本质是生成均值和方差
scaler.mean_ #查看均值的属性mean_
scaler.var_ #查看方差的属性var_
x_std = scaler.transform(data) #通过接口导出结果
x_std.mean() #导出的结果是一个数组,用mean()查看均值
x_std.std() #用std()查看方差
scaler.fit_transform(data) #使用fit_transform(data)一步达成结果
scaler.inverse_transform(x_std) #使用inverse_transform逆转标准化
对于StandardScaler和MinMaxScaler来说,空值NaN会被当做是缺失值,在fit的时候忽略,在transform的时候保持缺失NaN的状态显示。并且,尽管去量纲化过程不是具体的算法,但在fit接口中,依然只允许导入至少二维数组,一维数组导入会报错。
大多数机器学习算法中,会选择StandardScaler来进行特征缩放,因为MinMaxScaler对异常值非常敏感。在PCA,聚类,逻辑回归,支持向量机,神经网络这些算法中,StandardScaler往往是最好的选择。

对每个字段都计算其缺失值比例,然后按照缺失比例和字段重要性,分别制定策略:
| Low loss rate | High loss rate | |
|---|---|---|
| Low importance | 1.不做处理 2.简单填充 |
去除该字段 |
| High importance | 1.通过计算进行填充 2.通过经验估计 |
1.尝试从其他渠道取数补全 2.使用其他字段通过计算获取 3.去除字段,在结果中标明 |
import pandas as pd
# 均值填充
df['目标字段'].fillna(df['目标字段'].mean(), inplace=True)
2.2.2.中位数填充法
# 中位数填充
df['目标字段'].fillna(df['目标字段'].mode().iloc[0], inplace=True)
2.2.3.条件平均值填充法
该方法中,用于求平均值的数,并不是从数据集的所有对象中取,而是从与该对象具有相同决策属性值的对象中取得。
# 条件平均值填充
def condition_mean_fillna(df, label_name, feature_name):
mean_feature_name = '{}Mean'.format(feature_name)
group_df = df.groupby(label_name).mean().reset_index().rename(columns={feature_name: mean_feature_name})
df = pd.merge(df, group_df, on=label_name, how='left')
df.loc[df[feature_name].isnull(), feature_name] = df.loc[df[feature_name].isnull(), mean_feature_name]
df.drop(mean_feature_name, inplace=True, axis=1)
return df
df = condition_mode_fillna(df, 'Label', 'Feature2')
2.2.4.模型预测填充法
使用待填充字段作为Label,没有缺失的数据作为训练数据,建立分类/回归模型,对待填充的缺失字段进行预测并进行填充。
2.2.4.1.kNN先根据欧式距离或相关分析来确定距离具有缺失数据样本最近的K个样本,将这K个值加权平均/投票来估计该样本的缺失数据。
from sklearn.neighbors import KNeighborsClassifier, KNeighborsRegressor
def knn_missing_filled(x_train, y_train, test, k = 3, dispersed = True):
'''
@param x_train: 没有缺失值的数据集
@param y_train: 待填充缺失值字段
@param test: 待填充缺失值数据集
'''
if dispersed:
clf = KNeighborsClassifier(n_neighbors = k, weights = "distance")
else:
clf = KNeighborsRegressor(n_neighbors = k, weights = "distance")
clf.fit(x_train, y_train)
return test.index, clf.predict(test)
2.2.4.2.Regression
基于完整的数据集,建立回归方程。对于包含空值的对象,将已知属性值代入方程来估计未知属性值,以此估计值来进行填充。(当变量不是线性相关时会导致有偏差的估计)
2.2.5.利用sklearn填补缺失值class sklearn.impute.SimpleImputer(missing_values=nan, strategy=’mean’, fill_value=None, verbose=0, copy=True)
| 参数 | 含义&输入 |
|---|---|
| missing_values | 告诉SimpleImputer,数据中的缺失值长什么样,默认空值np.nan |
| strategy | 填补缺失值的策略,默认均值。 输入“mean”使用均值填补(仅对数值型特征可用) 输入“median"用中值填补(仅对数值型特征可用) 输入"most_frequent”用众数填补(对数值型和字符型特征都可用) 输入“constant"表示请参考参数“fill_value"中的值(对数值型和字符型特征都可用) |
| fill_value | 当参数startegy为”constant"的时候可用,可输入字符串或数字表示要填充的值,常用0 |
| copy | 默认为True,将创建特征矩阵的副本,反之则会将缺失值填补到原本的特征矩阵中去。 |
在机器学习中大多数算法只能处理数值型数据,不能处理文字。然而现实中,许多标签和特征在数据收集完毕时不是以数值型数据表现的。为了让数据适应算法,须将数据进行编码,即将文字型数据转为数值型。
4.处理连续型特征:二值化与分段sklearn.preprocessing.Binarizer
根据阈值将数据二值化(将特征值设置为0或1)用于处理连续型变量。大于阈值的值映射为1,而小于或等于阈值的值映射为0。
二值化是对文本计数数据的常见操作,分析员可以决定仅考虑某种现象的存在与否。还可以用作考虑布尔随机变量的估计器的预处理步骤(例如,使用贝叶斯设置中的伯努利分布建模)。
作者:MENG_Hsin