tensorflow2系类知识-4 :RNN
文章目录循环神经网络(RNN)示例代码
循环神经网络(RNN)
循环神经网络(Recurrent Neural Network, RNN)是一种适宜于处理序列数据的神经网络,被广泛用于语言模型、文本生成、机器翻译等。

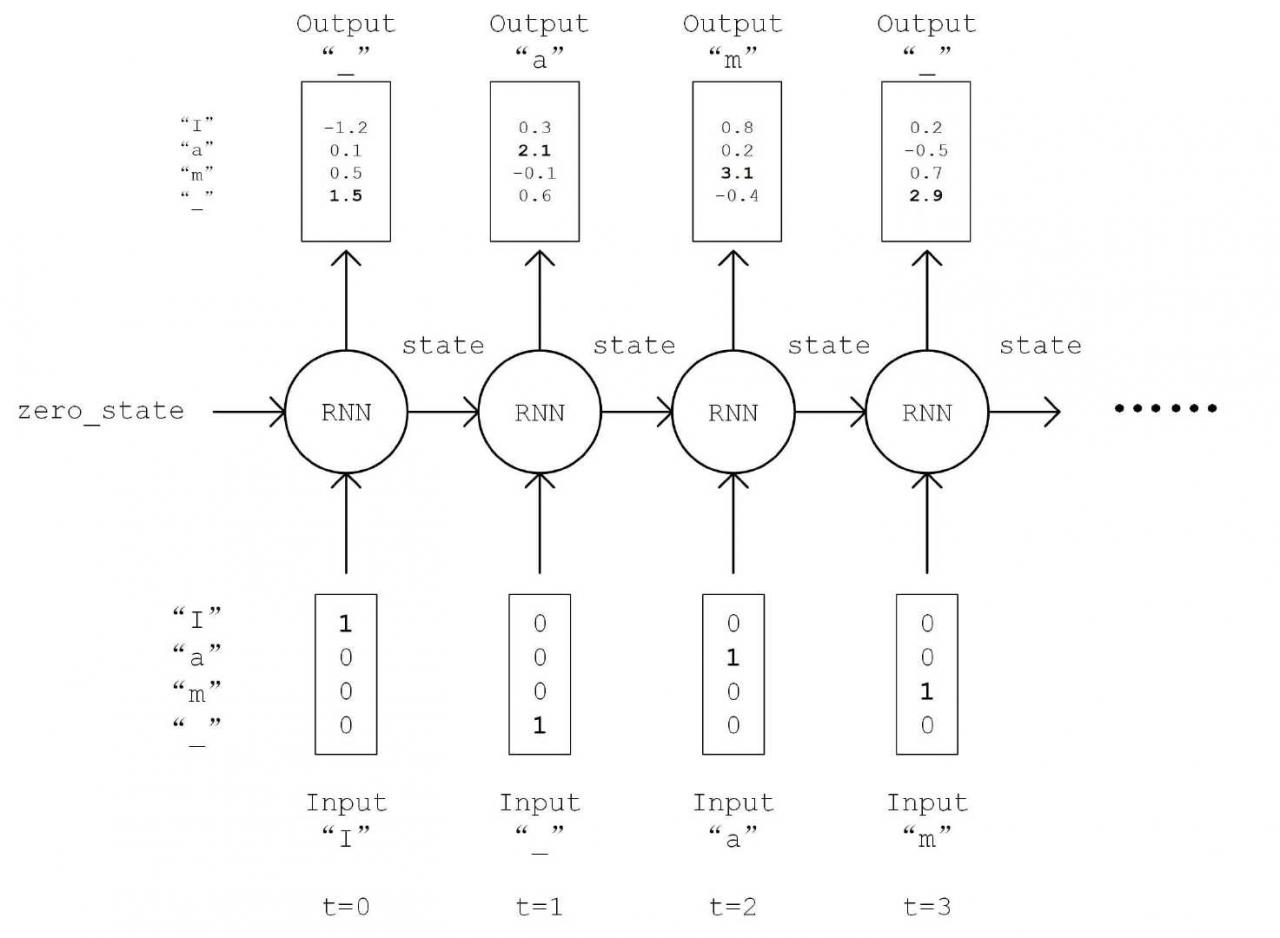
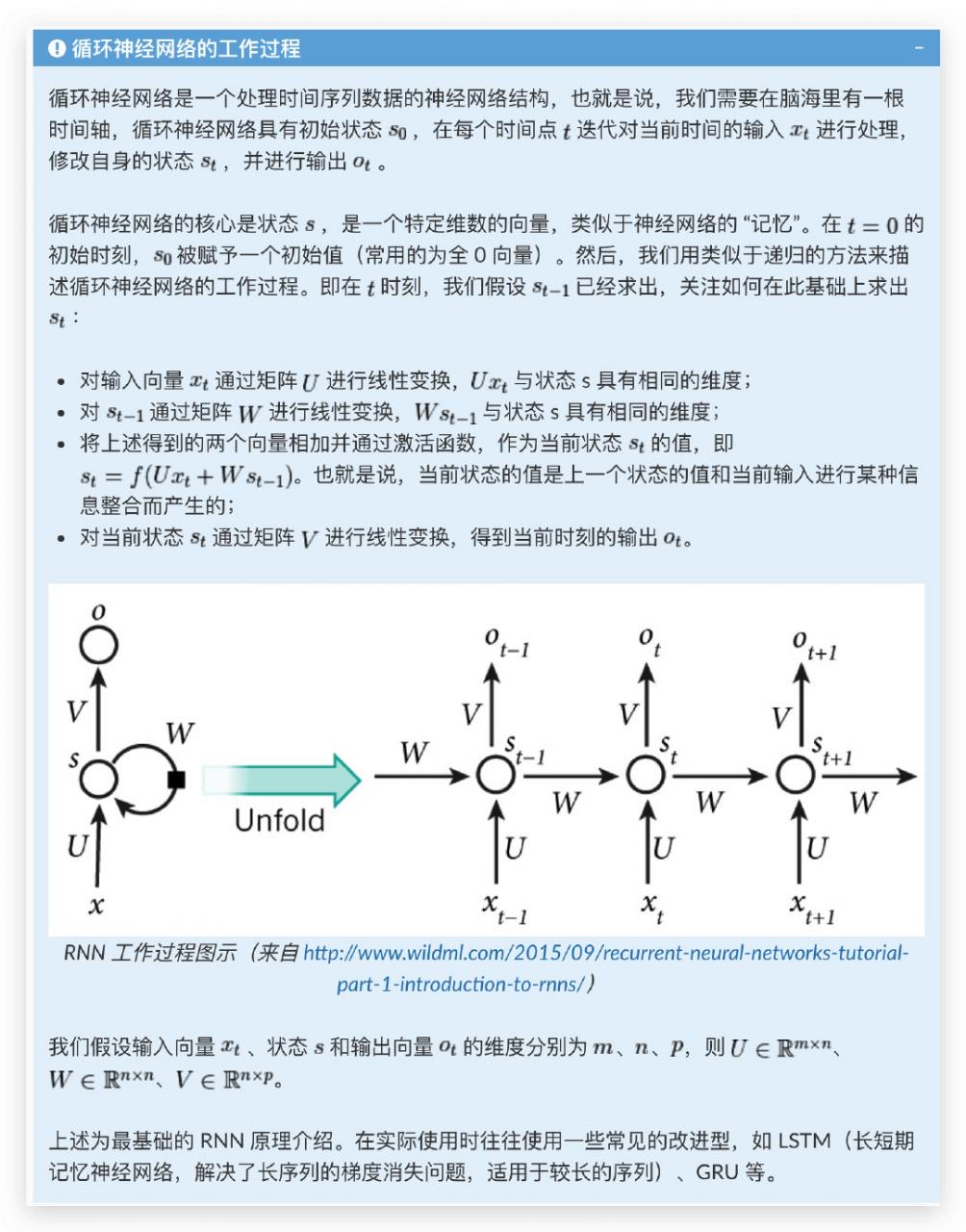 示例代码
示例代码
 缠禅可禅
缠禅可禅

 博客专家
原创文章 325获赞 139访问量 10万+
关注
私信
展开阅读全文
博客专家
原创文章 325获赞 139访问量 10万+
关注
私信
展开阅读全文
作者:缠禅可禅
示例代码
# -*- coding:utf-8 -*-
# /usr/bin/python
'''
-------------------------------------------------
File Name : RNN
Description : AIM:
Functions: 1. 基本原理
2. 概念
3. 示例代码
Envs : python == 3.7
pip install tensorflow==2.1.0 -i https://pypi.douban.com/simple
Author : errol
Date : 2020/5/2 15:20
CodeStyle : 规范,简洁,易懂,可阅读,可维护,可移植!
-------------------------------------------------
Change Activity:
2020/5/2 : text
-------------------------------------------------
'''
import numpy as np
import tensorflow as tf
class DataLoader(object):
def __init__(self,):
path = tf.keras.utils.get_file('nietzsche.txt',
origin='https://s3.amazonaws.com/text-datasets/nietzsche.txt')
with open(path, encoding='utf-8') as file:
self.raw_text = file.read().lower()
self.chars = sorted(list(set(self.raw_text)))
self.char_indices = dic((c,i) for i,c in enumerate(self.chars))
self.indices_char = dict((i, c) for i, c in enumerate(self.chars))
self.text = [self.char_indices[c] for c in self.raw_text]
def get_batch(self, seq_length, batch_size):
seq = []
next_char = []
for i in range(batch_size):
index = np.random.randint(0, len(self.text) - seq_length)
seq.append(self.text[index:index + seq_length])
next_char.append(self.text[index + seq_length])
return np.array(seq), np.array(next_char) # [batch_size, seq_length], [num_batch]
class RNN(tf.keras.Model):
def __init__(self,num_chars,batch_size,seq_length):
super().__init__()
self.num_chars = num_chars
self.seq_length = seq_length
self.batch_size = batch_size
self.cell = tf.keras.layers.LSTMCell(units=256)
self.dense = tf.keras.layers.Dense(units=self.num_chars)
def call(self,inputs,from_logits=False):
inputs = tf.one_hot(inputs,depth=self.num_chars)
state = self.cell.get_initial_state(batch_size=self.batch_size,dtype=tf.float32)
for i in range(self.seq_length):
output,stat = self.cell(inputs[:,t,:],state)
logits =self.dense(output)
if from_logits:
return logits
else:
return tf.nn.softmax(logits)
num_batches = 1000
seq_length = 40
batch_size = 50
learning_rate = 1e-3
'''
从 DataLoader 中随机取一批训练数据;
将这批数据送入模型,计算出模型的预测值;
将模型预测值与真实值进行比较,计算损失函数(loss);
计算损失函数关于模型变量的导数;
使用优化器更新模型参数以最小化损失函数。
'''
data_loader = DataLoader()
model = RNN(num_chars=len(data_loader.chars), batch_size=batch_size, seq_length=seq_length)
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
for batch_index in range(num_batches):
X, y = data_loader.get_batch(seq_length, batch_size)
with tf.GradientTape() as tape:
y_pred = model(X)
loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=y, y_pred=y_pred)
loss = tf.reduce_mean(loss)
print("batch %d: loss %f" % (batch_index, loss.numpy()))
grads = tape.gradient(loss, model.variables)
optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))
def predict(self, inputs, temperature=1.):
batch_size, _ = tf.shape(inputs)
logits = self(inputs, from_logits=True)
prob = tf.nn.softmax(logits / temperature).numpy()
return np.array([np.random.choice(self.num_chars, p=prob[i, :])
for i in range(batch_size.numpy())])
X_, _ = data_loader.get_batch(seq_length, 1)
for diversity in [0.2, 0.5, 1.0, 1.2]:
X = X_
print("diversity %f:" % diversity)
for t in range(400):
y_pred = model.predict(X, diversity)
print(data_loader.indices_char[y_pred[0]], end='', flush=True)
X = np.concatenate([X[:, 1:], np.expand_dims(y_pred, axis=1)], axis=-1)
print("\n")
缠禅可禅
作者:缠禅可禅