江湖小白之一起学Python (五)爬取淘宝商品信息
趁热需打铁,随着这几天的鸡血澎湃,我们来实现一下爬取淘宝商品信息,我记得几年前曾用python写了下抓取淘宝天猫,京东,拍拍的爬虫,专门采集商品信息,图片,评论及评论图片,我还用pyqt开发了个客户端,效果还不错,也让我用python赚了一些外快,来来来,千言万语也阻挡不了我一个显摆的心,贴2张多年前用python+pyqt开发的爬商品信息的软件
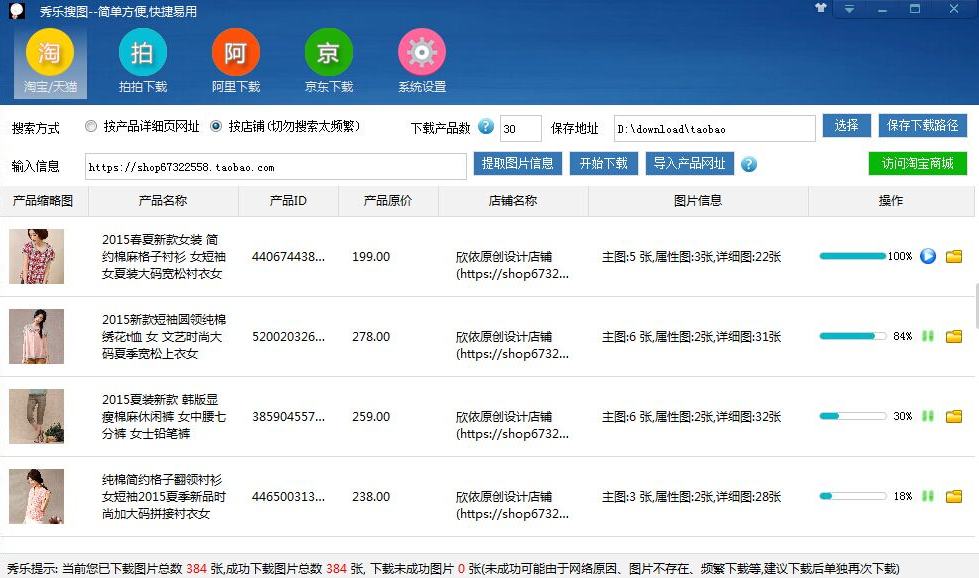
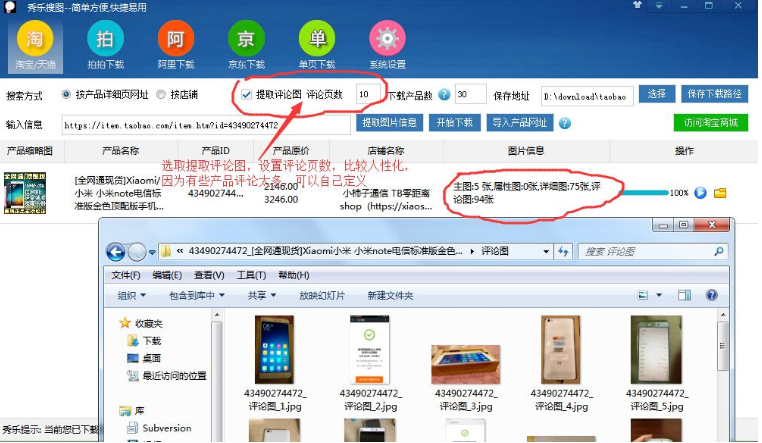
我觉得当时我这个在爬淘宝这些软件当中外观是最高大尚的,无奈木秀于林,风必摧之,扛不住同行的嫉妒,平台直接举报我,商品下架Game over! 深深的打击了我这颗幼小的心灵,才让我明白社会黑暗的一面,至此让我深深的沉沦,之后再也没有去抓淘宝信息了……峰回路转,最近头脑发热,想学学那些博主写写教程什么的,此刻让我沉沦的心从新燃烧起来,为了广大小白的一个爬虫梦,我决定重操旧业……额,当我准备素材的时候,我发现最近爬取淘宝信息要先登录了,看来经过几年的洗礼,淘宝也扛不住广大爱好者的热情,为了稳定舍弃一部分用户的体验,深度谴责这种行为~~!

既然这样,你也无法阻挡那些有着梦想的少年心,仔细分析了下,在登录中,有个重要的参数UA,跟踪了下算法,JS混淆加密,看得我头疼,既然这里是小白学习的教程,那我就简化一下爬取商品信息的重要操作步骤:
1. 这里我们直接用cookie,将cookie放入headers请求头部信息,模拟浏览器访问
2.为了防止频繁访问,淘宝会弹出滑块验证的问题,这里我们会结合上篇所讲的Ip池的运用
接下来进入正题,比如我要抓取关键词为python的商品信息页面,那简化下搜索的地址:
https://s.taobao.com/search?q=python
下面我们就来获取这个页面的源码信息:
#代理Ip地址
proxies = {'https': '47.106.59.75:3128'}
User_Agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'
#封装一下请求头部
headers = {
'User-Agent': User_Agent,
'cookie': self.getcookie()
}
#淘宝搜索关键词为python的网址,q=后面是你要搜索的关键词
url='https://s.taobao.com/search?q=python'
#下面是使用头部信息和代理Ip开始请求访问
response = requests.get(url=url,headers=headers,proxies=proxies,timeout=5)
response.encoding = response.apparent_encoding
content = response.text
print(content)
其它注释基本都能看懂吧,之前的教程也提到过,重点说下cookie值,这里self.getcookie()是什么呢,是我写的一个读取cookie的方法,因为cookie是有时效性的,为了方便,我将cookie保存在一个命名为cookie.txt的文件里,方便更新及维护
#读取cookie
def getcookie(self):
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
return cookie
大家又看到def啊,self什么什么的,没错,我将整个爬虫封装了一个类文件,然后将一些通用的方法定义一下函数,那关键又来了,童鞋们又问,cookie从何而来,当然是从浏览器开发者中工具中来,首先我们在浏览器中打开https://s.taobao.com/search?q=python这个网址,如果你淘宝没有登录的话,会直接跳转到登录页面,先输入自己的淘宝账号登录,登录后会调回这个页面,接着我们还是轻轻的按下F12,弹出开发者工具窗口后,我们按F5刷新下页面,在密密麻麻的地址中找到这个:
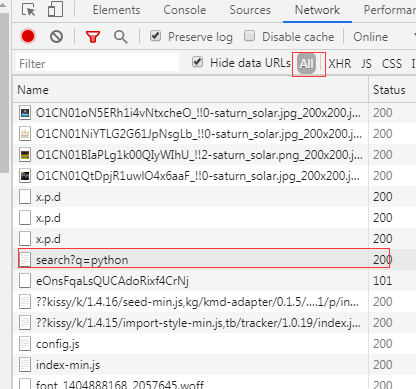
如果不好找的话,选择这项:
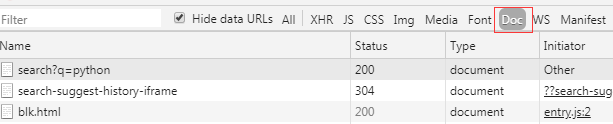
然后点击这栏,选择headers,找个Request Headers:
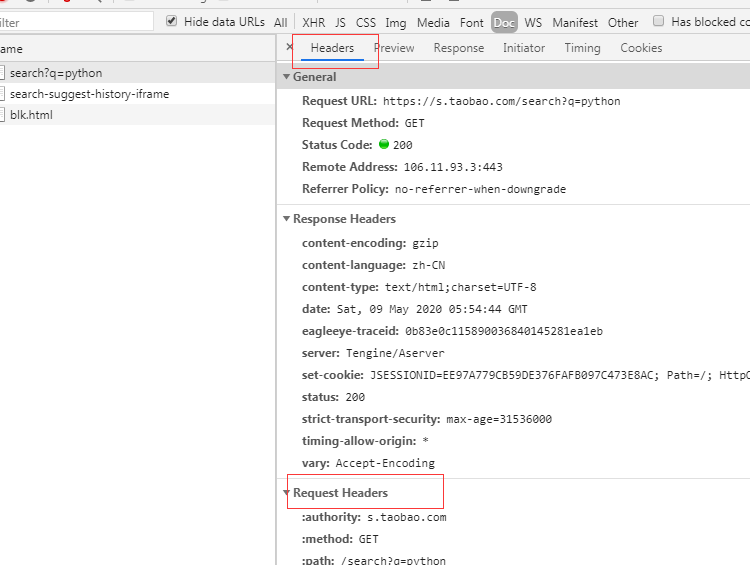
往下翻,找到cookie值:

然后不管三七二十一,直接将这段cookie值复制保存到你代码同级目录下的cookie.txt文件里,这样cookie值的获取就成功了,通过上面的代码就能获取搜索页面的源码内容,我们先分析下源码内容,发现是json串格式的:

淘宝的源码内容不是html标签,而是在script里,通过方法渲染成html标签,来,我们继续分析,发现我们需要的信息在‘auctions’,这里对于小白来说有点深奥(有需要以后可以专门讲下这个东西),‘auctions’是一个数组形式的,因为存在多个商品,这里很长一串,我们怎么快速的获取到这个内容呢,我们就用正则将这部分提取出来, re.search('"auctions":([\w\S\s]+),"recommendAuctions"', tbjsonstr)这句话的意思就是获取"auctions":和,"recommendAuctions"之间所有的内容包含空格换行,
#将获取到的源码内容过滤下,里面有很多\n的换行符,我们先去掉这些换行符
tbjsonstr = re.sub('\\n', '', content)
#通过观察我们要的商品信息的数据在"auctions":和,"recommendAuctions"这个之间,于是我们获取这段
result = re.search('"auctions":([\w\S\s]+),"recommendAuctions"', tbjsonstr)
#通过正则获取到括号里的内容
resultstr=result.group(1)
#这里把提取到的内容转成dict类型,方便获取详细参数
tblist=json.loads(resultstr,encoding="utf-8")
#循环遍历下信息
for tbinfo in tblist:
print(tbinfo['raw_title'],tbinfo['nick'],tbinfo['view_price'],tbinfo['view_sales'],t
详细看下代码里的注释,这里用到了re函数的search,关键就是[\w\S\s]+这里,加了括号是为了提取匹配的字符串,获取到的内容如下:

这里获取到的是文本类型的,为了使用JSON格式,我们用json函数方法转换下:json.loads(resultstr,encoding="utf-8"),然后就开始循环一下数组,在JSON中提取所需要的字段信息,方法上面代码所示,这个为了便于观察,将json数据格式化了一下:

不贴结果图的文章永远不是好文章,来我们打印一下结果看看:

到此就抓到了我们需要的商品信息,感觉才讲到一半,篇幅有点长,第1点我们完成了,接下来我们完成第2点就是用上ip池,防止频繁访问出现滑动验证码等问题,其实也简单先贴下方法:
#获取ip池
def get_ips(self):
with open('tbip.txt', 'r', encoding='utf-8') as f:
tbips = f.read()
tbipsarray = tbips.split('\n')
#过滤空字符
tbipsarray=list(filter(None, tbipsarray))
return tbipsarray
#随机获取一个ip
def randomip(self):
# 获取最新ip池
self.ips = self.get_ips()
randomip = random.choice(self.ips)
return randomip
#删除失效的ip地址
def del_ip(self,delip):
with open("tbip.txt", "w", encoding="utf-8") as f:
for i,ip in enumerate(self.ips):
if delip == ip:
continue
f.write(ip+"\n")
这里呢,封装了3个方法,第1个方法是获取通过上篇生成的ip池,第2个方法是获取随机一个随机ip,第3个方法是删除掉失效的ip也就是删掉这个通过代理无法访问淘宝网的ip,方便释放资源,避免无效ip的重复请求,通过这个方式,后期再完善一下,可以实现自动抓取ip,自动过滤无效ip,是不是解放了双手。

那上面的方法在哪里使用呢,这里……这里……,首先我们在类的初始化函数定义一下:
def __init__(self):
#定义失败次数
self.failnum=0
#随机获取一个Ip
self.rip = self.randomip()
同理因为在使用代理的时候,可能由于代理ip过期等一下异常原因,我们还是给请求淘宝网址那段代码加个try,抛出一下异常,接着我们在异常情况下处理一下逻辑:
try:
…………………………(省略上面的代码)
except Exception as e:
#尝试访问失败超过3次,删除当前IP地址,重置失败次数,重新获取ip地址
self.failnum+=1
if self.failnum > 3:
#初始化失败次数回归为0
self.failnum = 0
#删除失效的IP
self.del_ip(self.rip)
#随机获取一个IP
self.rip = self.randomip()
print('重新获取IP:{}'.format(self.rip))
else:
print('ip:{},尝试链接次数:{} 次'.format(self.rip, self.failnum))
#重新访问此方法
self.get_info()
上面注释得很清楚了吧,这里我就不在解释了,感觉写完心里空荡荡的(赶紧点赞……)
好了,白嫖兄弟,可以开赞了……,完整代码双手奉上:
#coding:utf-8
import requests,random,re,json
class taobao:
def __init__(self):
#定义失败次数
self.failnum=0
#随机获取一个Ip
self.rip = self.randomip()
#获取淘宝列表信息
def get_info(self):
#代理ip地址
proxies = {
'https': self.rip
}
User_Agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'
#封装请求头部信息
headers = {
'User-Agent': User_Agent,
'cookie': self.getcookie()
}
#淘宝搜索关键ptyhon的网址
url='https://s.taobao.com/search?q=python'
try:
response = requests.get(url=url,headers=headers,proxies=proxies,timeout=5)
response.encoding = response.apparent_encoding
content = response.text
tbjsonstr = re.sub('\\n', '', content)
result = re.search('"auctions":([\w\S\s]+),"recommendAuctions"', tbjsonstr)
resultstr=result.group(1)
print(resultstr)
tblist=json.loads(resultstr,encoding="utf-8")
for tbinfo in tblist:
print(tbinfo['raw_title'],tbinfo['nick'],tbinfo['view_price'],tbinfo['view_sales'],tbinfo['item_loc'])
except Exception as e:
#尝试访问失败超过3次,删除当前IP地址,重置失败次数,重新获取ip地址
self.failnum+=1
if self.failnum > 3:
#初始化失败次数回归为0
self.failnum = 0
#删除失效的IP
self.del_ip(self.rip)
#随机获取一个IP
self.rip = self.randomip()
print('重新获取IP:{}'.format(self.rip))
else:
print('ip:{},尝试链接次数:{} 次'.format(self.rip, self.failnum))
#重新访问此方法
self.get_info()
#读取cookie
def getcookie(self):
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
return cookie
#获取ip池
def get_ips(self):
with open('tbip.txt', 'r', encoding='utf-8') as f:
tbips = f.read()
tbipsarray = tbips.split('\n')
#过滤空字符
tbipsarray=list(filter(None, tbipsarray))
return tbipsarray
#随机获取一个ip
def randomip(self):
# 获取最新ip池
self.ips = self.get_ips()
randomip = random.choice(self.ips)
return randomip
#删除失效的ip地址
def del_ip(self,delip):
with open("tbip.txt", "w", encoding="utf-8") as f:
for i,ip in enumerate(self.ips):
if delip == ip:
continue
f.write(ip+"\n")
if __name__ == '__main__':
tb=taobao()
tb.get_info()
好了,简单的爬取淘宝信息就到这里,其实里面还有些用法,大家自己揣摩下,比如self.ips怎么用到全局的等等,有兴趣的老铁们以后可以逐步拓展,然后形成一个强大的抓取工具,如我开篇所示……

江湖不说再见,咱们下篇见!

关注公众号,发现不一样的自我
如果有需要了解的和不明白的地方可以给我留言,我会整理一些代码提供参考
 飞奔的猫
飞奔的猫
 原创文章 45获赞 34访问量 9万+
关注
私信
展开阅读全文
原创文章 45获赞 34访问量 9万+
关注
私信
展开阅读全文
作者:飞奔的猫