Python爬虫学习笔记(4)_淘宝商品比价爬虫
此篇笔记是笔者在学习嵩天老师的《Python网络爬虫与信息提取》课程及笔者实践网络爬虫的笔记。
淘宝商品比价爬虫一、前提准备1、功能描述2、分析页面3、代码实现4、完整代码:5、运行结果6、总结 一、前提准备 1、功能描述获取淘宝搜索页面的信息,提取其中的商品名称和价格。
2、分析页面①先确定搜索url
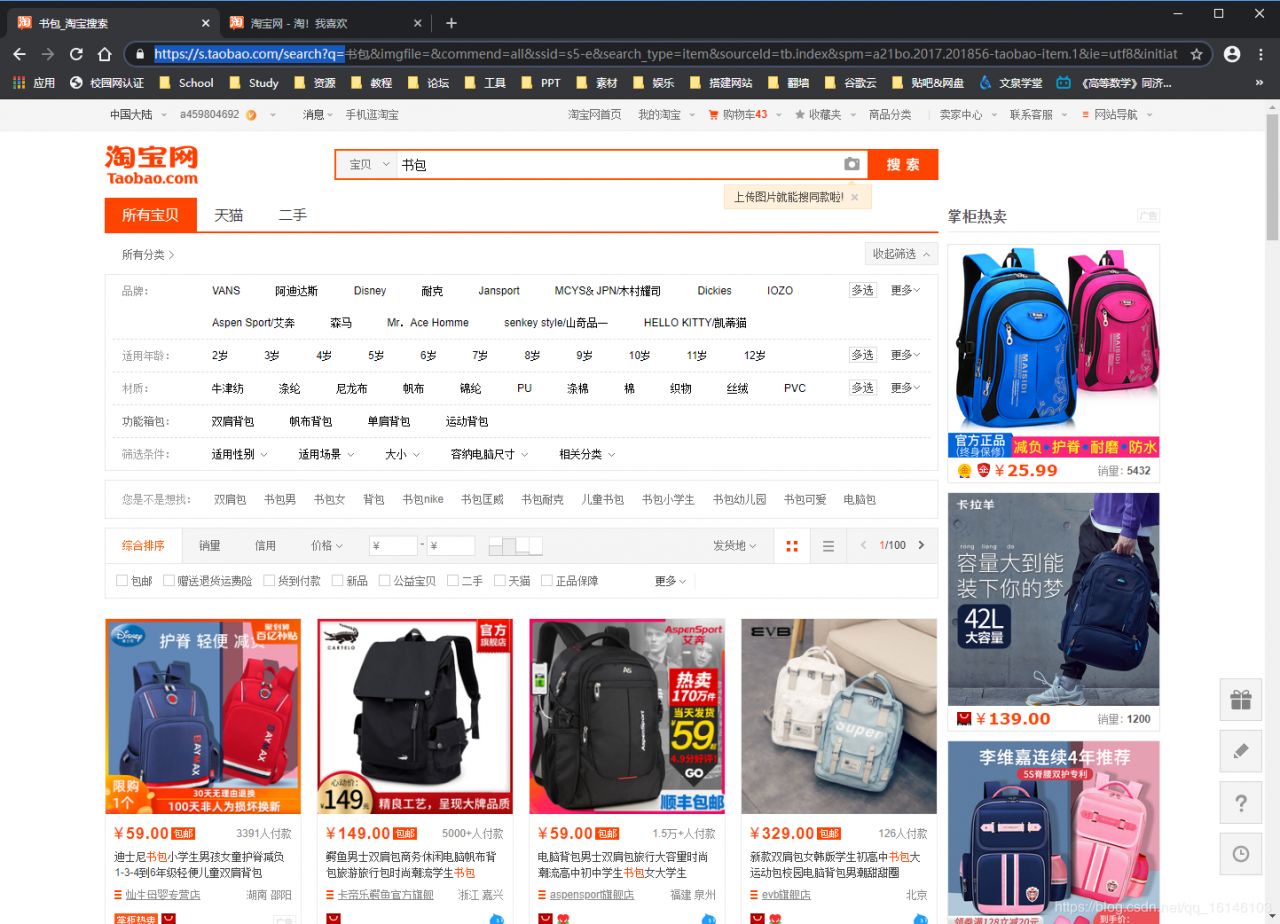
根据上图我们可以看到url为:https://s.taobao.com/search?q后面的书包为自定义搜索内容。
由此我们可以知道起始url为:start_url = 'https://s.taobao.com/search?q=' + 自定义搜索内容
②确定每一页物品的数量。
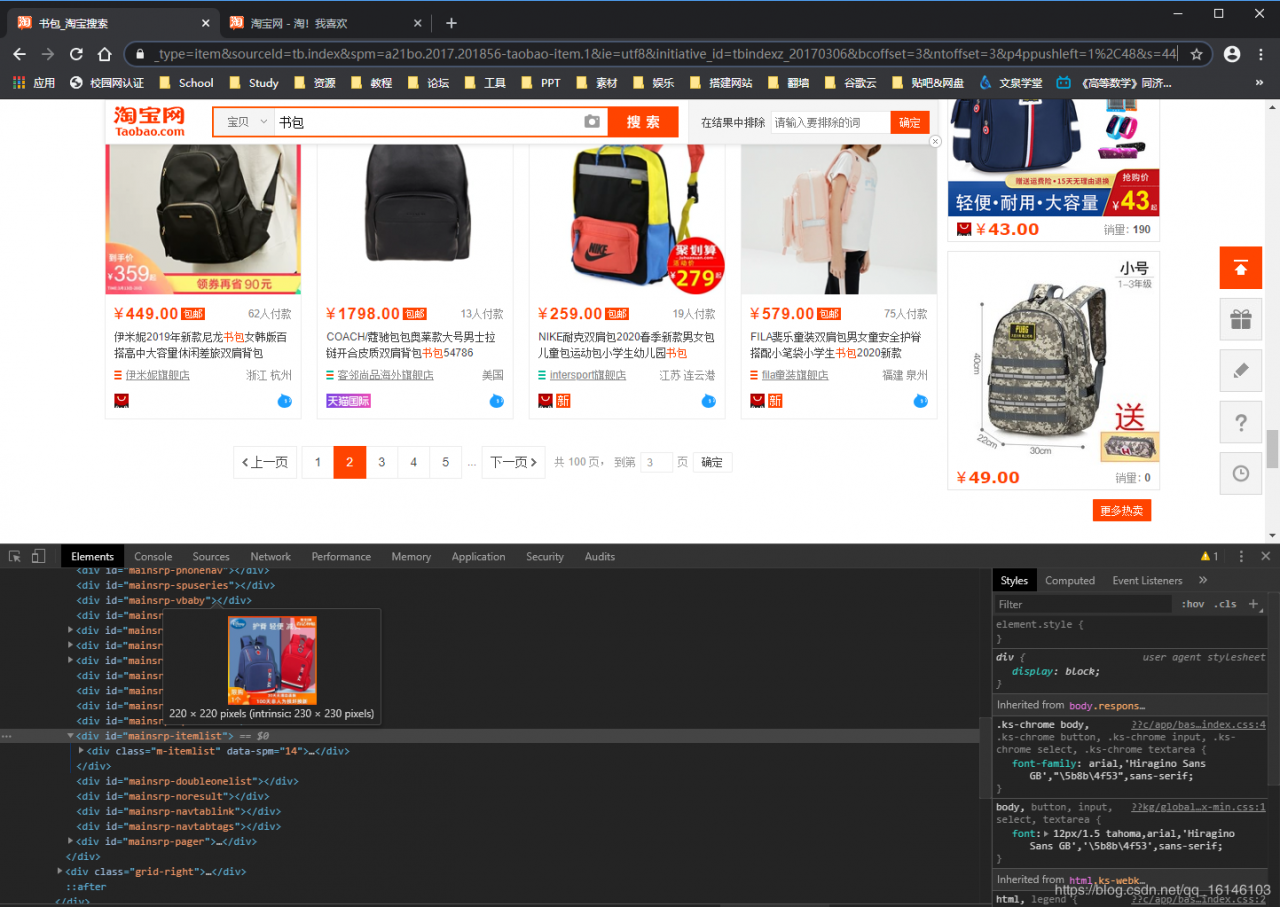

根据上面点击不同页面可以发现,每一页的间距为44
③每个商品的价格以及内容简介:
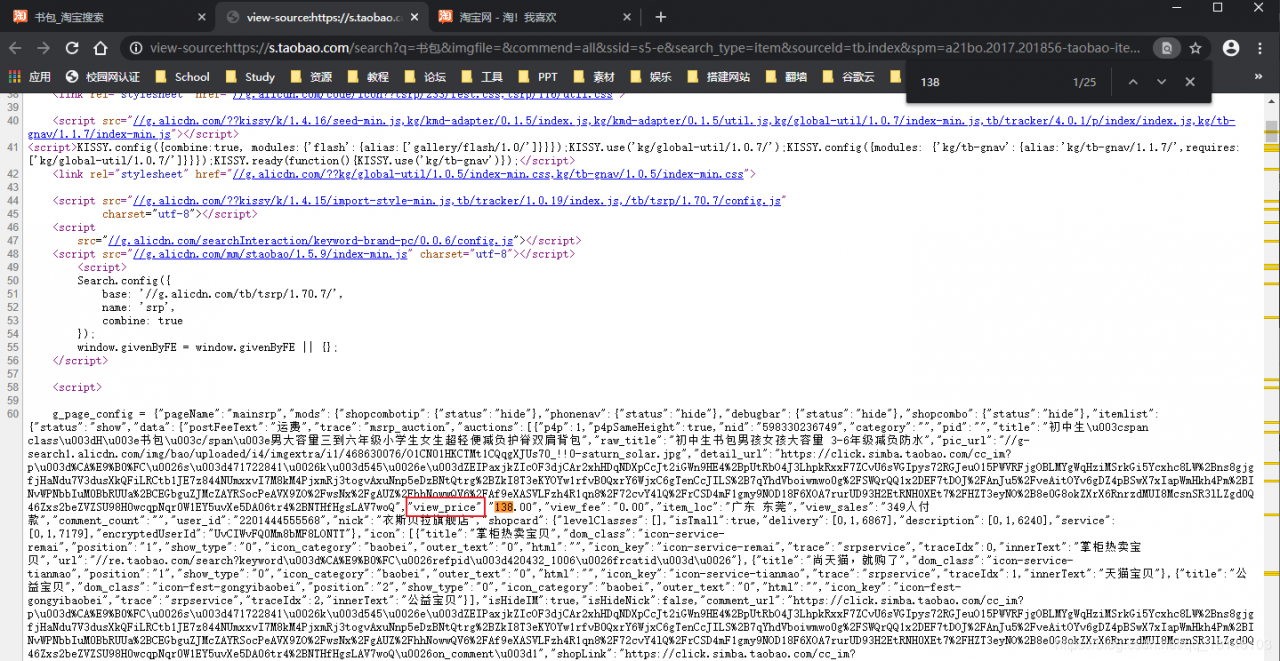
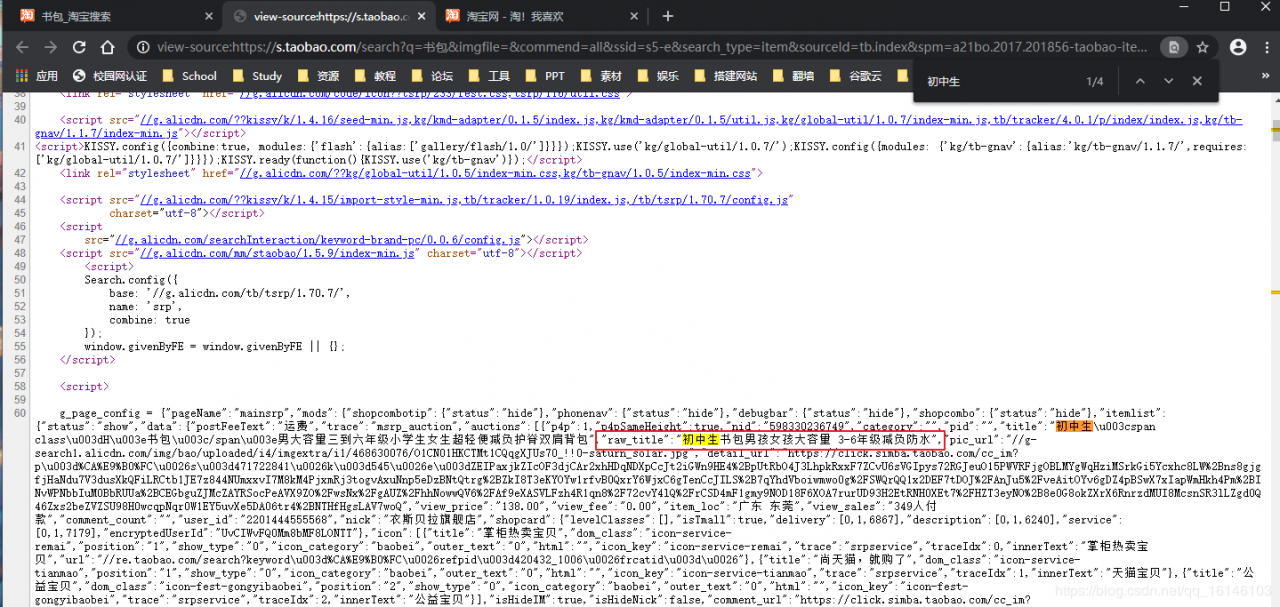
步骤:
提交商品搜索请求,循环获取页面
对于每个页面,提取商品名称和价格信息对于每个页面,提取商品名称和价格信息
将信息输出到屏幕上将信息输出到屏幕上
大体框架:
import requests
import re
def getHTMLText(url): # 获得页面函数
pass
def parsePage(ilt, html): # 解析获得的页面
pass
def printGoodlist(ilt): # 输出结果信息到屏幕
pass
def main(): # 主函数
goods = '书包'
depth = 3 # 下一页深度
start_url = 'https://s.taobao.com/search?q=' + goods
indolist = [] # 输出结果
for i in range(depth):
try:
url = start_url + '&s=' + str(48 * i)
html = getHTMLText(url)
parsePage(indolist, html)
except:
continue
printGoodlist(indolist)
main()
4、完整代码:
# =============================================
# --*-- coding: utf-8 --*--
# @Time : 2020-03-20
# @Author : 李华鑫
# @CSDN : https://blog.csdn.net/qq_16146103
# @FileName: taobao.py
# @Software: PyCharm
# =============================================
import requests
import re
def getHTMLText(url): # 获得页面函数
try:
header = {
'user-agent': 'Mozilla/5.0 ',
'cookie': 'thw=cn; cna=npj6FSROsjACAdodv5gJhCng; hng=CN%7Czh-CN%7CCNY%7C156; tracknick=a459804692; _cc_=Vq8l%2BKCLiw%3D%3D; tg=0; enc=QBWbMOc0vQMNrTeNZMKkNSam6PhBuBNZFXZb7jRKj1R6%2FnZ%2FAztJW%2F4Ql%2BaqZxBArE4hIF2kV2dUg%2BBZSV88Eg%3D%3D; x=e%3D1%26p%3D*%26s%3D0%26c%3D0%26f%3D0%26g%3D0%26t%3D0%26__ll%3D-1%26_ato%3D0; miid=778994371391611536; t=c8d997f8c3862a9545d7aa8e0f55a811; _m_h5_tk=35adf942f203d5b2def2e96c38527acf_1579166355669; _m_h5_tk_enc=0f3e60d1c12cd628e261b932e21ab4a2; cookie2=15c929f24b3d18aec75687bbefabacb3; v=0; _tb_token_=e9b30e375eee7; alitrackid=www.taobao.com; lastalitrackid=www.taobao.com; __guid=154677242.3514116682747917000.1579155943921.0774; _uab_collina=157915745635971448621381; x5sec=7b227365617263686170703b32223a223365323561373037306538313737393931373032646330666464613337346335434b6154675045464549756a734e6e372f4a724f68674561444449314f5467344e5459344e6a55374d513d3d227d; JSESSIONID=391518D427C8B71F1754C4144A533BCA; monitor_count=8; isg=BE9PlXPQTWYkTEpDzc8TlxxO3uNZdKOWgEm-D2Fcj77tMG0yYUXr5h6mMmCOSHsO; l=cBa32tzuqwYH7YbhBOCwZuI8jO79hIRVguPRwnNXi_5dY18KvH_Oomns5eJ6cjWdtkLW4IFj7Ty9-etuiRHx3mx-g3fP.'
}
r = requests.get(url, headers=header, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
# print(r.text)
return r.text
except:
return ""
def parsePage(ilt, html): # 解析获得的页面
try:
plt = re.findall(r'\"view_price\"\:\"[\d\.]*"', html)
tlt = re.findall(r'\"raw_title\"\:\".*?"', html)
for i in range(len(plt)):
price = eval(plt[i].split(':')[1])
title = eval(tlt[i].split(':')[1])
ilt.append([price, title])
except:
print("")
def printGoodlist(ilt): # 输出结果信息到屏幕
tplt = "{:4}\t{:8}\t{:16}"
print(tplt.format("序号", "价格", "商品名称"))
count = 0
for g in ilt:
count = count + 1
print(tplt.format(count, g[0], g[1]))
def main(): # 主函数
goods = '书包'
depth = 3 # 下一页深度
start_url = 'https://s.taobao.com/search?q=' + goods
indolist = [] # 输出结果
for i in range(depth):
try:
url = start_url + '&s=' + str(48 * i)
html = getHTMLText(url)
parsePage(indolist, html)
except:
continue
printGoodlist(indolist)
main()
5、运行结果
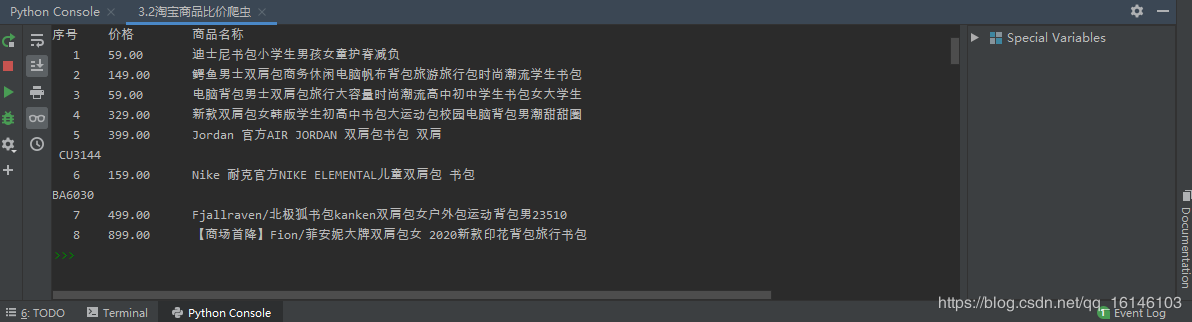
本爬虫程序并没有使用BS4,使用的是正则表达式,同时本程序也没有使用存储程序,这些都可以完善的,在此我就不完善了。
作者:不温卜火